
Machine Learning aims to find and discover useful patterns from large data sets. The value of patterns discovered from mining the data enables businesses to make effective data-driven decisions and develop a sustainable competitive advantage. Applications of data mining can be find in social welfare, e-commerce, sales and marketing, politics, supply chain operations and finance etc.
The interesting part to see for us is how this field brings together techniques from machine learning, statistics and information retrieval.
Data mining methods currently used, includes clustering, decision trees, classification, and random forest.
Hold on, I will now answer all your questions regarding Data Mining .
What is Data Mining?
Data mining is the process of finding and discovering patterns exploring in large data sets i.e Big Data. It’s a subfield of computer science which blends many techniques from machine learning, data science, statistics, database theory.

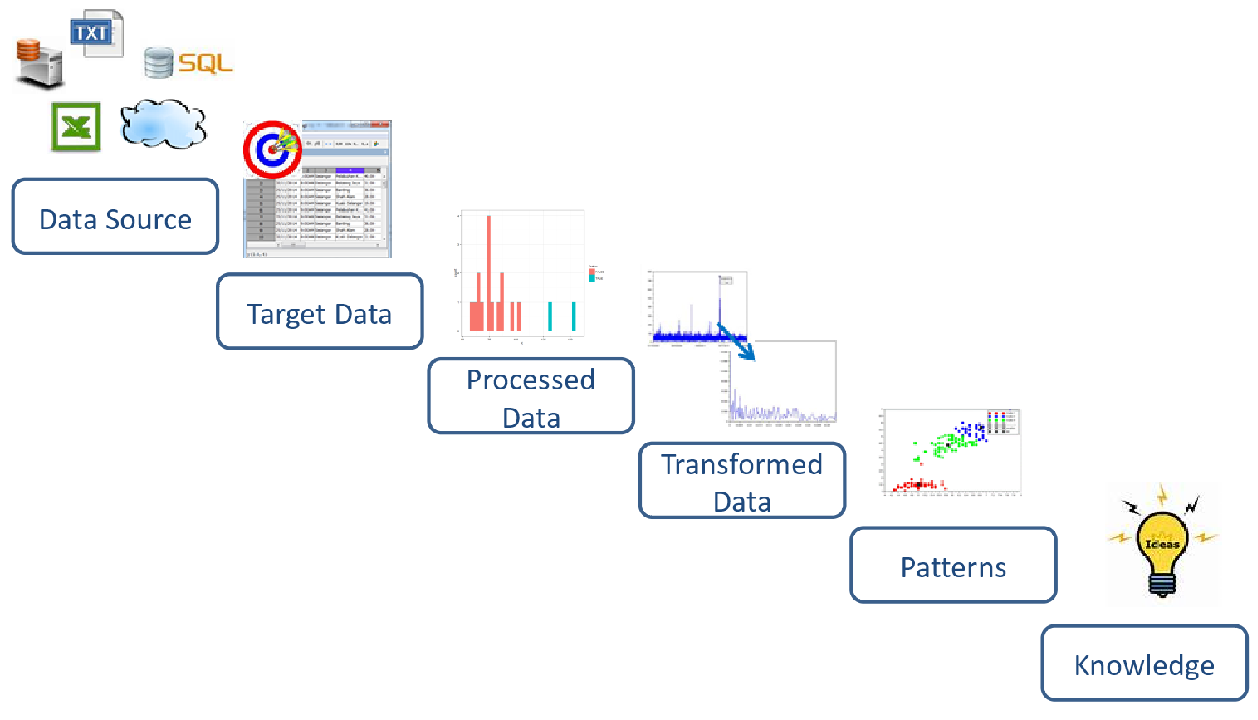
Where does Data Mining fit?
Data Source—> Target Data —> Pre-processing Data —> Transformed Data —> Models—> Knowledge.
Where is Data Mining used ?
- Supermarkets: Loyalty programs, Stocking shelves.
- Telecom: Predict customer churn.
- Credit Cards: Potential customers for new credit card offerings.
- E-Commerce: Cross-sell and Up-sell promotions.
- Human Resources: Employee retention and ranking.
- Educational Institutions: Factors influencing student success/failure rate.
- Retail: Segment customers based on Recency, Frequency and Monetary (RFM) purchases.
- Customer Relationship Management: Customer acquisition and retention.
- Crime Agencies and Fraud Detection: Identify fraud detection patterns.
Data Mining techniques:
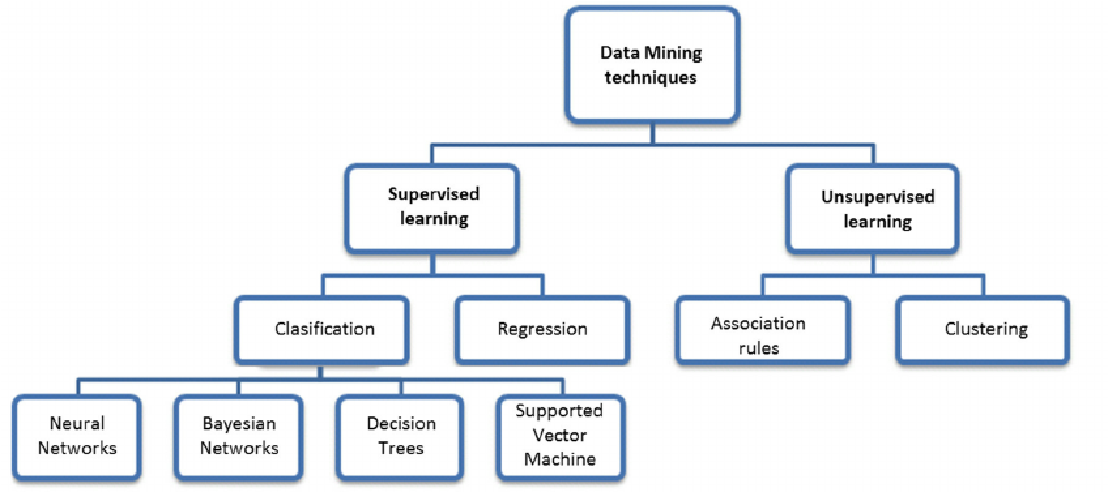
Types of Data Mining:
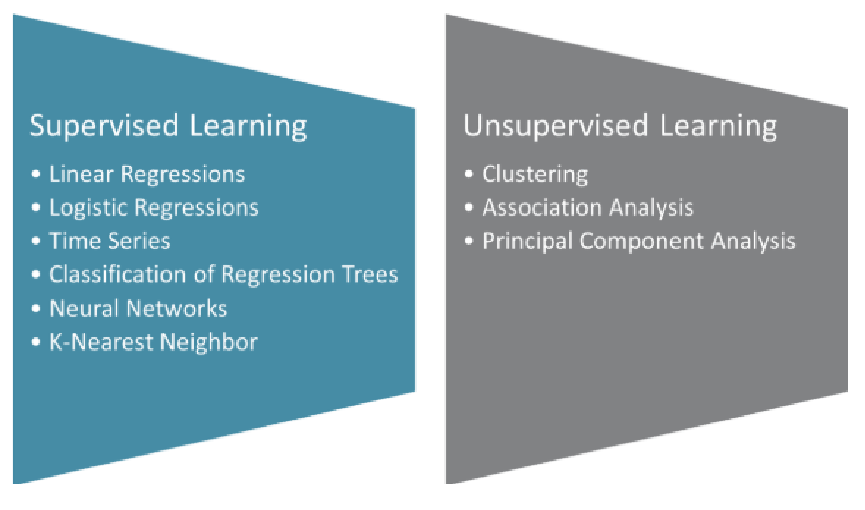
Unsupervised learning :
Supervised Learning :
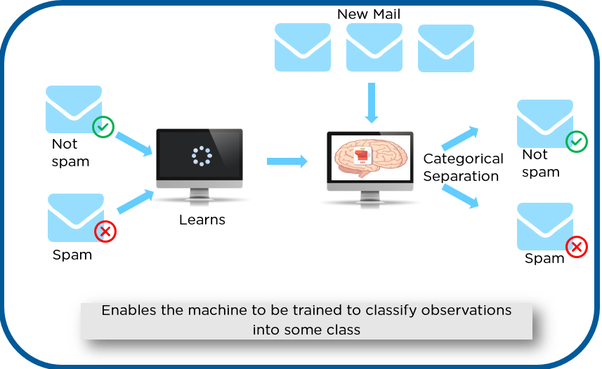
Training and Test Data:
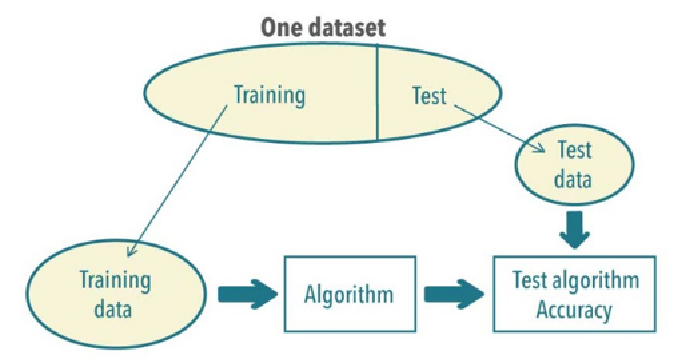
Cross validation:
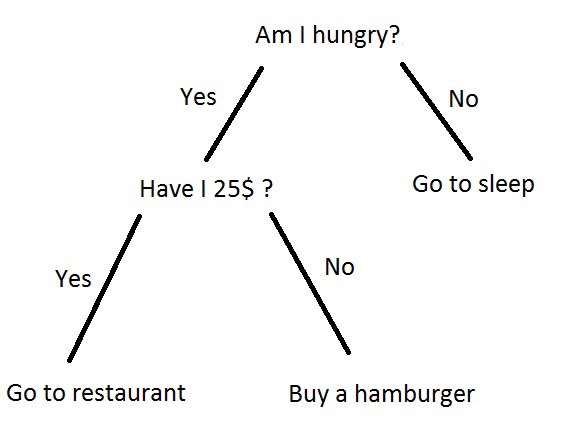
Decision Tree:
A decision Tree is one of most popular and effective supervised learning techniques for classification problems that equally works well with both categorical and quantitative variables. It is a graphical representation of all the likeable solutions to a decision that is based on certain order. In this algorithm, the training sample points are split into two or more sets based on the split condition over input variables. A simple example of a decision tree can be as a person has to make a decision for going to sleep or restaurant based on parameters like he is hungry or have 25$ in his pocket.
Clustering:
Clustering is one of the fundamental problems of unsupervised learning algorithms defined as the process of dividing the simple data points into homogeneous groups of similar data points. Grouping of data points is based on the similarities and dissimilarities between them, the points within the same group are similar and among different groups they are dissimilar. This could be understood by the following figure where similar data points are cluster on the basis of colour.
The agglomerative clustering starts by considering each data point as a single cluster. In the next step the singleton clusters are merge into a bog cluster upon the similarity between them. The procedure is repeat until all the data points are merge into one big cluster. The procedure can be represent as a hierarchy/tree of clusters.
The divisive clustering works completely opposite to agglomerative clustering and also known as Divisive Analysis (DIANA). The method starts from one big cluster considering all data points within it. In the next the big cluster is divided into the most heterogeneous two clusters. The procedure is repeated until each data point is in its own cluster.
Artificial Neural Networks:
Neural network is formed when each neuron gets connected to each other and can be connected with about 6,000 other neurons.
Conclusion:
Companies, industries and organizations are using data mining to identify a link between internal aspects like Employee skills, Cost of production and external aspects like competition and economic scenario.
Huge amount of data is generated every day and we need new models and techniques of data mining to find hidden patterns in data.
Article by: Nikhil Rampuria
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs