
Introduction: Random Forest
A random forest is an ensemble model that combines many decision trees. Individually, predictions made by decision trees (or humans) may not be accurate but combined together, the predictions will be closer to the mark, on average.
Being a combination of many decision trees, there is a greater probability of having many views from all trees in the forest to arrive at the final desired outcome/prediction.
There is less information consider for prediction when a single decision tree is into consideration. Since we use many decision trees in the random forest approach, the source of information is diverse and extensive and they are not bias.

(https://miro.medium.com/max/567/1*Mb8awDiY9T6rsOjtNTRcIg.png)
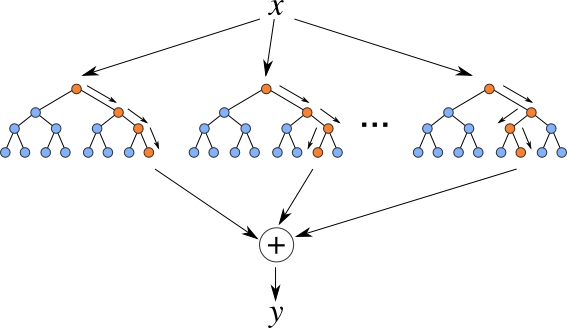{kind=link}
We can see the structure of a random forest in the above image. This algorithm works with the bagging technique. Random subsets are created from the original dataset. Trees are seed and grow at each node in the image. thus, only a specific number of features are consider at each node to decide the best split up. The final prediction is calculate by averaging the predictions from all decision trees.
Ensemble Method
In the Ensemble method, we group multiple models together. method. Ensemble methods are consider as the best model approach for better performance and accuracy of actual outputs.
Let’s discuss the two major terms associated with the Ensemble method.
- Bias Error: A model with a high bias means that it is a low-performance model that continues to miss major trends. It is measured as the difference between the predict and the actual value.
- Variance: This is the amount by which a model’s performance varies with different datasets. A model with high variance will give an overfitted training model but will perform badly on other data.
Ensemble Modeling
There are three major methods of building an ensemble model,
Overview of Random Forest with Example
Suppose we are planning to go on a trip. To know about the places around we have 3 main sources, travel blogs, reviews, or ask a friend who has already visited that place.
When we ask about reviews from friends, based on their past experience and knowledge each friend can suggest some different place. So, we list down all possible recommendations and ask them to vote among all the places in order to select the best place to visit. We will choose the place with the maximum votes.
There are two parts involve in the decision-making process,
- The first part includes asking friends about their individual travel experiences can get recommendations for various locations they have visited. This part can be as the algorithm of the decision tree where each friend makes the selection of the places.
- After all the recommendations have been collected, the second part is the voting procedure. This is carry out to select the best place in the recommendation list. This entire process of making the recommendation list and voting to find the best place to visit is refer as the algorithm of random forest.
Parameters in Random Forest
n_estimators:
- It defines the number of decision trees to create in a random forest
- Generally, the higher the number of decision trees, the more stronger and stable is the prediction.
- A very large number of decision trees takes higher training time.
criterion:
- It defines the function that is in use for splitting. For example gini.
- This function measures the quality of a split for each feature and chooses the best split.
max_features:
- It defines the maximum number of features that are allow to be divide under each decision tree.
- Increasing max feature can increase performance but a very high number can decrease the diversity of the tree.
max_depth:
- This parameter defines the maximum depth of each tree that a random forest holds.
min_samples_split:
- This is in use to define the minimum number of samples required in a leaf node before a split is attempt further.
- The node does not split if the number of samples is less than the required number of samples for splitting.
min_samples_leaf:
- It defines the minimum number of samples required to be a leaf node.
- Smaller values are more prone to capture noise from the training data.
max_leaf_nodes:
- It is the maximum no of nodes for each tree.
- If the number of leaf nodes becomes equal to the max-leaf nodes, the tree will not split further.
n_jobs:
- It indicated the number of jobs to run in parallel.
random_state:
- It defines random selection.
- It is used to compare various models.
verbose:
- This controls the verbosity when fitting the model and predicting.
- It has a default value of 0.
Advantages and Disadvantages of Random Forest
Advantages:
- Used to solve both classification and regression problems.
- It is not affected by missing values
- This technique is based on bagging, so it reduces overfitting and variance. This results in better accuracy.
Disadvantages:
- It also does not perform well on the regression tasks.
- thus, It is a complex model.
- It however requires high training time to learn a model.
Written By: Chaitanya Virmani
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs