
Text mining (also known as text analytics) is a technology that uses AI and uses NLP to transform the free text in databases and documents into structured data that is then suitable for further analysis or to drive machine learning algorithms.
Lets understand Text Mining:
Unstructured vs Structured Data :
Structured Data –
Predefined structure, i.e., a database. We can have millions of rows, columns and tables, but the database is structured.
Unstructured Data –
No pre defined data model. so, Think of a bunch of satellite images or Twitter feed or the entire list of chats or speeches from the British Parliament.
Why is Text Mining Important?
Industries, Businesses ,organizations and individuals generate lots of data everyday. Statistics shows that almost 82% of the present text data is unordered , meaning it’s not structured in a required way i.e in rows and columns , it’s impossible to manage such unstructured words In other words, its not useful for finding out any pattern..
though Being able to capture, arrange ,organize and categorize important information from raw data is a top and major concern for Businesses . Text mining is important to this mission.
In a business context, unorganized raw data can include chats, posts ,emails, social media posts , survey, support tickets etc. Structuring through all these types of information surely will results in failure. Not only because it’s expensive and time-consuming but also because it’s impossible and inaccurate to scale.
What is Text Analytics?
- Sentiment Analysis
- Search unstructured data
- spam filtering (characteristics of e-mails)
- Social Media monitoring
- Competitive intelligence (business, security…)
- Translation
- Simulation
Semantic vs Bag of Words
Semantic – the process of changing a natural language sentence into a formal representation of its form that is meaningful to read.
Bag of Words – Disregarding grammar and also word order it is the simplification of the text.
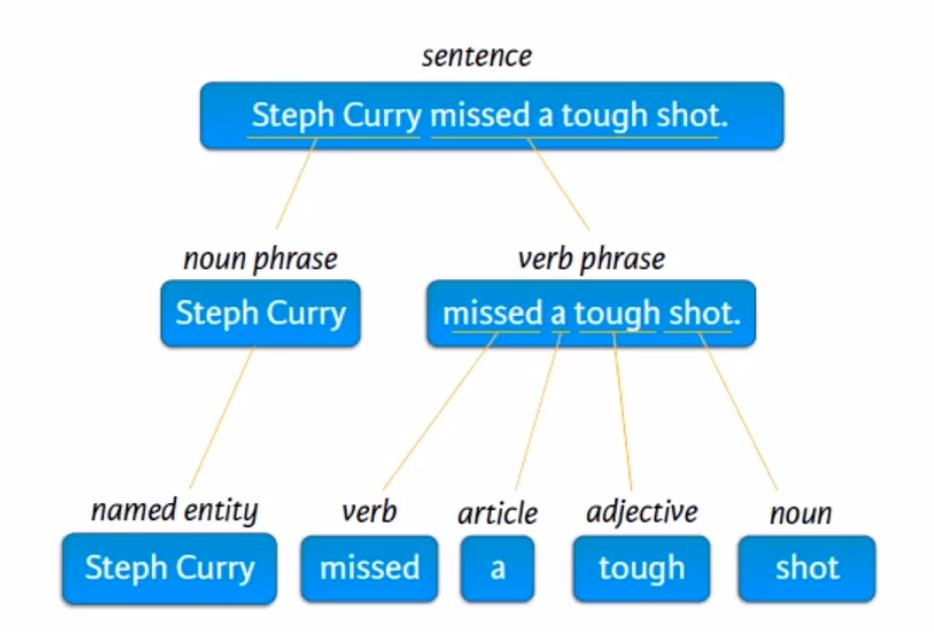
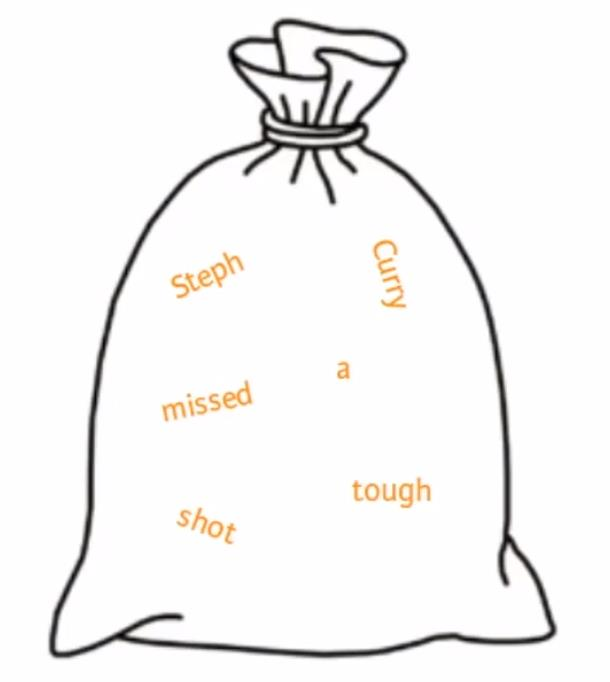
What is a corpus?
Corpus (or corpora plural) is a thus large set of text .
Cleaning up the data
Stemming – Returning words in a text to their original form. For instance, the words ‘cut’,
‘cutting’ and ‘cutted’ all simply become ‘cut’ when stemmed.
Stop Words – ‘useless’ words we generally want to remove for data analytics so we use stop words technique..
Words like ‘is’, ‘the’, ‘an’ and ‘in’ are very common and thus we remove them.
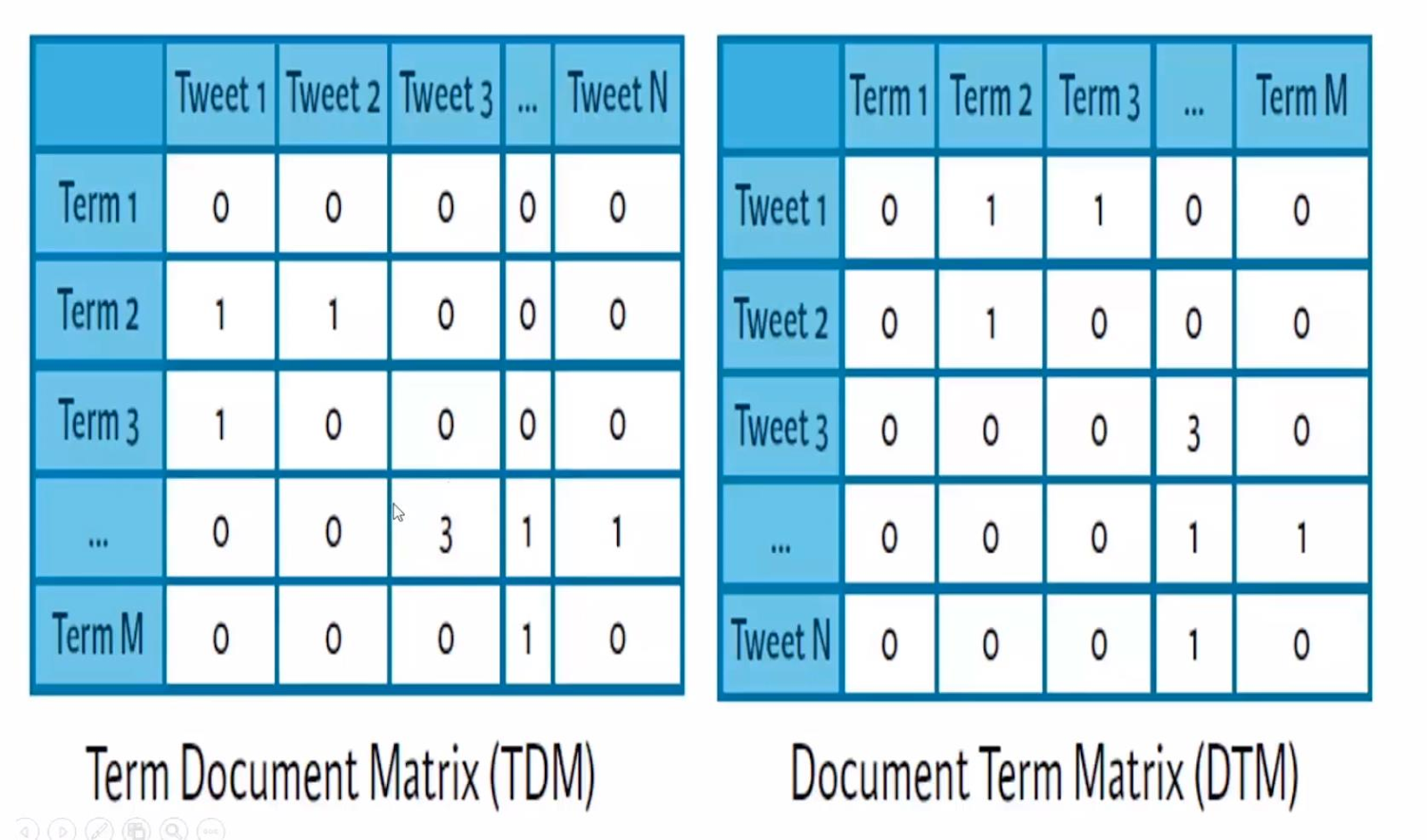
TDM v DTM:
Cleaning up the data:
Word Embedding:
An NLP technique of representing words in the form of vectors.
Popular methods include:
- Dimension reduction techniques, like SVD.
- word2Vec (Neural networks)
- Glove
- That is, it detects similarities mathematically.
Similar words and similar vectors
- thus, Two words with similar contexts mean similar things.
- Eg: Red & Blue, Cat & Dog
- Cosine Similarity -measuring distance between word vectors
- Embedding can (surprisingly) build even more meaning into the vectors.
- Eg: ‘King’-‘Man’+‘8Woman’ ≈ ‘Queen’
Applications
- Analyzing any form of text for insights: reviews, survey responses, tweets, comments.
- NLP
- Text classification
- Sentiment analysis
- Translation
- Recommendation systems
Singular Value Decomposition
- so, Begins with a text corpus (Eg. All the tweets in say a yr)
- Assemble a word co-occurrence matrix: M
- also, Find a lower dimensional word embedding matrix W such that, M = W * WT .
This step be done using Singular Value Decomposition (SVD) - The W matrix now thus contains the vector representation for each word.

Conclusion:
Text mining is helping businesses , organizations and also companies become more efficient and productive, and gain a better advantage and knowing of their customers. also, use this understanding and insights to make efficient data-driven decisions.
thus, Many repetitive and time-consuming tasks can now be replaced by models and algorithms that gain information from examples to achieve highly precise and accurate results. Analyzing enormous or large datasets and using different and unique techniques, such as sentiment analysis, keyword detection or topic labeling , leads to profit driven observations about what customers think and feel about a service and their product.
Article By: Nikhil Rampuria
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs