
Introduction:
There are several possible techniques for classification knowledge. Principal element analysis and linear discriminant analysis area unit 2 unremarkably used techniques for knowledge classification and spatiality reduction.
Linear Discriminant analysis simply handles the case wherever the with at school frequency area unit unequal and their performances has been examined to every which way generated check knowledge. This technique maximizes the magnitude relation between category variance to with {in category|in school|at school} variance specifically class knowledge set thereby guaranteeing maximal on an individual basis. The utilization of LDA for knowledge classification is applied to classification downside in speech recognition. We have a tendency to conceive of implementing associate degree algorithms for LDA in hopes for providing higher PCA is that PCA will additional feature classification and LDA will knowledge classification . In PCA, the form and site of the first knowledge sets modifications once remodeled to a unique house wherever as LDA doesn’t change the placement however solely tries to produce additional category disconnectedness and draw a call region between the given categories.
Different approaches to LDA:
Data sets are often remodeled and check vectors are often classified within the remodeled house by 2 completely different approaches.
Class dependent transformation :
This kind of approach involves maximising the magnitude relation between category variance to with at school variance. The most objective is to maximise the magnitude relation so adequate category disconnectedness is obtained. The class-specific sort approach involves victimisation 2 optimizing criteria for remodeling the info set severally.
Class freelance transformation:
This approach involves maximising the magnitude relation of overall variance to with at school variance .This approach uses only 1 optimizing criterion rework|to rework|to remodel} {the knowledge|the info|the information} sets and therefore all data points regardless of their category identity area unit remodeled victimisation this transform.In this sort LDA ,each category is taken into account as a separate category against all different categories.
Classification:
Input vector x belongs to R(d), assign it to 1 of K separate categories C(k) ,k=1,2,……..,k.

Assumption: categories area unit disjoint ,i.e., input vector area unit allotted to precisely one category.
Idea: Divide input house into call region whose boundaries are units known as call surfaces.
Linear classification:
Focus on linear classification model, the choice boundary could be a linear performance of x.
Defined by (D-1) dimensional hyperplane

If the info are often separated precisely by linear call surfaces , they’re known as linear dissociable.
Implicit assumption: categories are often sculpturesque well by Guassians
Here : treat classification as a project downside.
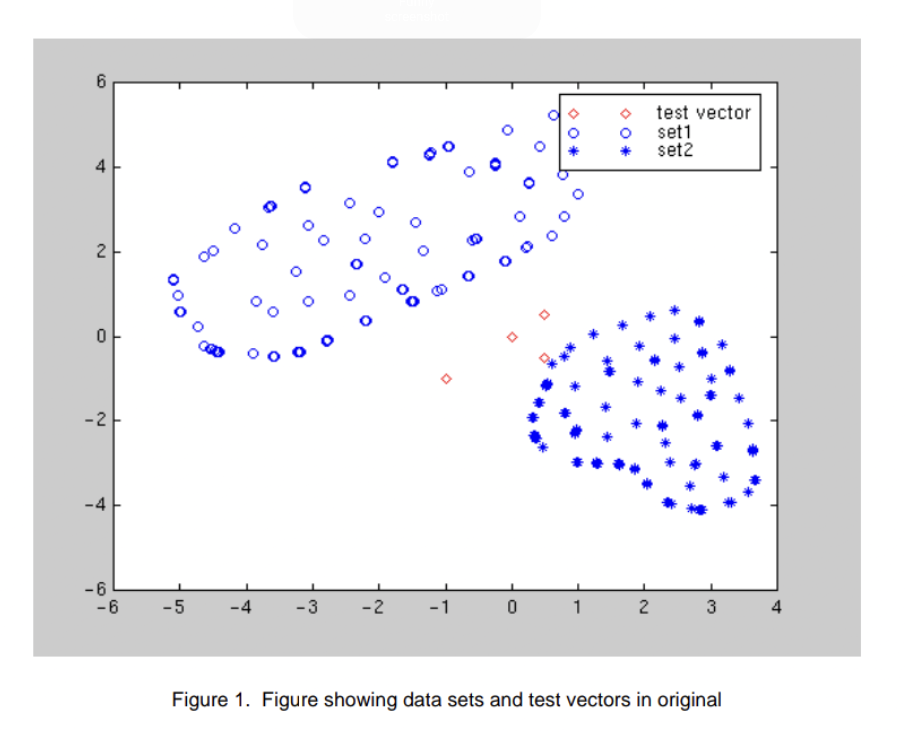
EXAMPLE:
Measurement for one hundred fifty iris flowers from 3 completely different species
Four features(petal length width sepal length width)

Given a brand new measurement of those options ,predict the iris species supported a projection onto a low-dimensional house.
PCA might not be ideal to separate the categories well.
Orthogonal Projection:
Project input vector x belongs to R(d) right down to a 1-dimensional topological space with basis vector w.

We will mostly target the coordinates y within the following.
Projection points equally apply to ideas mentioned these days.Coordinates equally apply to PCA .
Classification as projection:
Assume we all know the premise vector w , we will figure the projection on any purpose x belongs to R(d) onto the one dimensional topological space spanned by w.

Threshold w, such has that we have a tendency to opt for c(1) if y> w and c(2) otherwise.
The linear call boundary of LDA:
Look at the log -probability ratio-

Where the choice boundary for c(1) and c(2) is at zero.
Assume Guassian chance p(x|c(I))=N(x|m(i),summation) with identical variance in each categories .Decision boundary
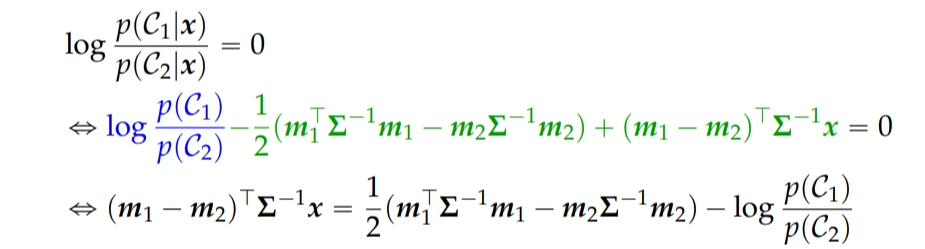
Of the shape Ax=b ,Decision boundary linear in x.
Potential issues:
Considerable loss of knowledge once projected.

Even if the info was linearly dissociable in R(d) .we might lose this disconnectedness
Find smart basis vector w that spans the topological space.
Approach : maximize young woman separation-
Adjust elements on the premise of vector w.
Select the projection that maximizes the category separation

Consider 2 categories c1 with n1 and c2 with n2 points.
It’s maximize this w.r.t w with the constraint ||w||=1
Maximum category separation :
Projected categories should still have appreciable overlap(because of powerfully non-diagonal variance of the category distributions.
LDA: giant separation of projected category suggests that and little with at school variations.
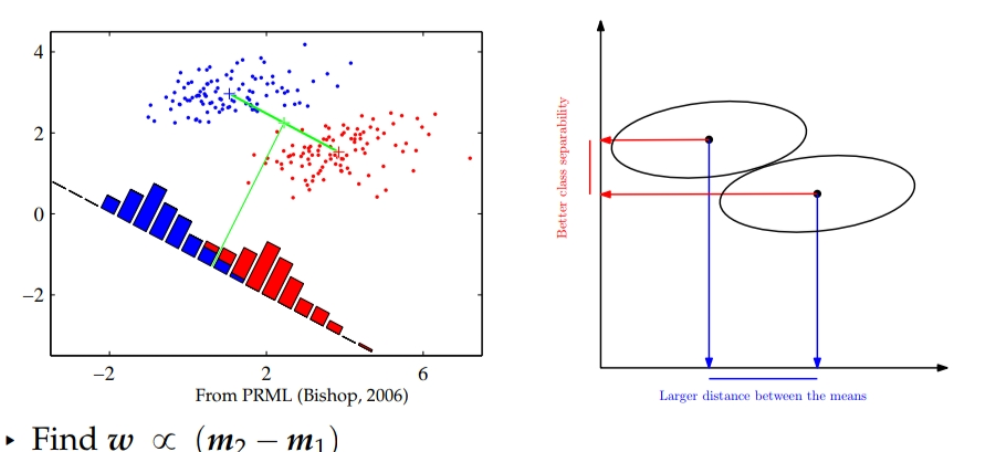
Key plan of LDA:
Separate samples of distinct teams by projected them onto an area that maximizes their between category on an individual basis whereas minimizing their with at school variability

Fisher criterion:
For each category c(k) the with at school scatter(unnormalized variance) is given as –

S(w) is that the total with at school scatter and proportional to the sample variance matrix.
Algorithms :
1. Mean standardization
2. figure means vector m(i) belongs to R(d) for all k categories.
3. figure scatter matrices s(w),s(b).
4. figure Eigenvectors and eigenvalues.
5. choose k Eigenvector w(i) with the biggest eigenvalues to make a D*k dimensional matrix
6. Project samples onto the new sub areas victimisation W and figure the new coordinates Y=XW
7. Coordinates matrix of the n knowledge points w.r.t eigenbasis W spanning the k dimensional topological space.
Assumptions in LDA:
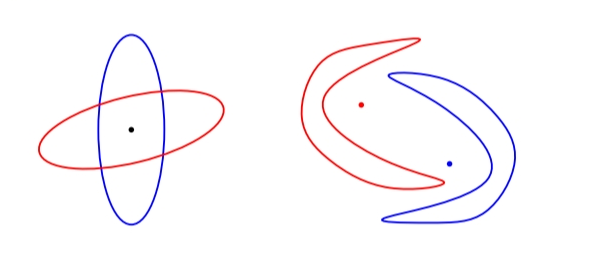
1. Truth variance matrices of every category area unit equal.
2. While not this assumption – Quadratic discriminant analysis
3.Performance of the quality LDA are often seriously degraded if there is solely a restricted variety of total coaching observations N compared to the dimension D of the options house.
4.LDA expressly tries to model the distinction between the categories of knowledge. PCA on the opposite hand doesn’t take into consideration any distinction at school.
Limitation of LDA:
LDA most discriminant options area unit the suggests that of the info distributions
LDA can fails once the discriminant info isn’t the mean however the variance of the info
If the info distribution area unit is terribly non – Guassians ,the LDA projection won’t preserve the advanced structure of the info that will be needed for classification.