
Table Of Contents
1. Intuition Behind Ensemble Learning
2. What Is Ensemble Learning?
3. Types Of Ensemble Learning
4. Ensemble Learning Methods With Python Implementation
5. Endnotes
Before Getting Started With The Definition Part Let Us Know The Intuition Behind The Ensemble Learning Concept With An Example.
Intuition Behind Ensemble Learning
If You Want To Buy A New Laptop For Data Science Work, Will You Walk Directly Into The Nearby Shop To Buy A Laptop Without Any Second Thought Or By The Shop Dealer Advice?This Won’t Be Possible Right.

Before That You Will Do Some Research On Which Laptop Would Be Preferable For Data Science Work Through Several Web Portals. Based On The Reviews, Configurations And Majorly When Budget Matches You Will Go For Buying The Laptop.

In Short, We Won’t Make Direct Conclusions, But Yes We Make Decisions After Doing Some Research Or By Asking Friends Opinions.
In The Similar Way Ensemble Models In Machine Learning Work Or Operate On The Similar Concept. Ensemble Methods Are Basically Learning Methods That Achieve Performance By Combining Multiple Models (Learners).
What Is Ensemble Learning?
Ensemble Learning Is Usually Used To Average The Prediction Of Different Models To Get A Better Prediction
Main Objective Of The Ensemble Methods Is To Combine The Several Base Learners To Create A Combined Effect Or To Improve The Stability And Predictive Approach Of The Model.
This Is The Reason Why Everyone Chooses This Learning Method While Participating In Hackathons Or Competitions.
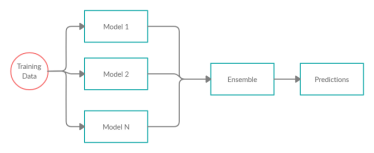
Types Of Ensemble Learning
There Are Two Types Of Ensemble Methods Or Learning
1.Averaging Or Bagging Method: In This Method We Build Several Estimators Independently And In The End Averaging The Predictions. Example: Random Forest
2.Sequential Or Boosting Method: In This Method Base Estimators Are Built Sequentially Using Weighted Versions Of Data I,E Fitting Models With Data That Were Miss-Classified. Example: Adaboost
Next, We Will Understand The Relation With The Bias And Variance
Basically When We Build Any Machine Learning Models The Prediction Error Is What The Sum Of
1.Bias Error
2.Variance Error
1.Bias Error: It Is Nothing But How Far We Are Actually Predicted From The Actual Value . High Bias Is Nothing But Over Simplifying The Model In Other Words Underfitting. So To Overcome This We Have To Add More Features Or To Use A Complexity Model.
2.Variance Error: It Is The Variability Of Model Prediction For A Given Set Of Data Points. This Will Tell How Data Is Actually Spread. High Variance Means The Model Performs Pretty Well But On The Other Side Error Rate Will Be High. So To Overcome This Use More Training Data.
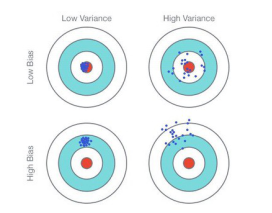
Ensemble Learning Methods
1.Bagging: Bagging Is Used To Decrease The Variance And Keep Bias The Same. Bagging Helps To Implement Similar Learners On Sample Populations.Bagging Consists Of Running Multiple Different Models, Each On Different Sets Of Input Samples And Then Taking The Average Of Those Predictions. Bagging Is A Kind Of Averaging Technique And Applied Mainly To An Over-Fitted Model.
Example : Random Forest
Why Do We Use Random Forest Over Decision Tree?
The Limitation Of The Decision Tree Is That It Overfits The Model And Shows High Variance. To Overcome This We Have Random Forest Which Is An Averaging Ensemble Method Whose Prediction Is The Function Of ‘N’ Decision Trees.
Let’s Compare Decision Tree And Random Forest Using Python Programming With MNIST Data-Set
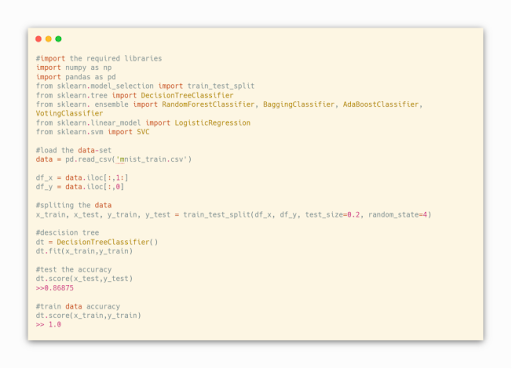
From The Above Decision Tree Implementation For MNIST Data, The Accuracy For The Test Data Is 86.75% Which Is A Good Accuracy But When We See The Accuracy For The Train Data The Accuracy Is 100 %. Which Means The Model Is Overfitted And Lets Try To Implement It With The Random Forest Algorithm.
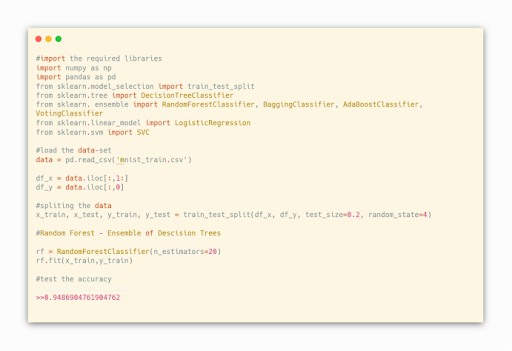
By Using The Random Forest Algorithm We Can Say That The Accuracy For The Test Data Is Best With 94.86% Which Is Good Compared To The Decision Tree Algorithm.
Going Forward Let’s Implement Bagging Technique For The Same Data And Will See The Train, Test Accuracy
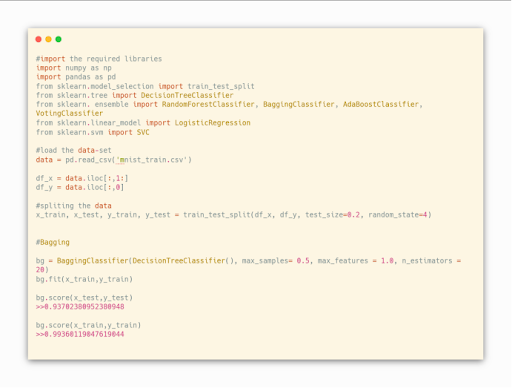
After Implementing Bagging Technique, The Accuracy With The Test And Train Data Is Not Much Different When Compared With The Decision Tree & Random Forest.
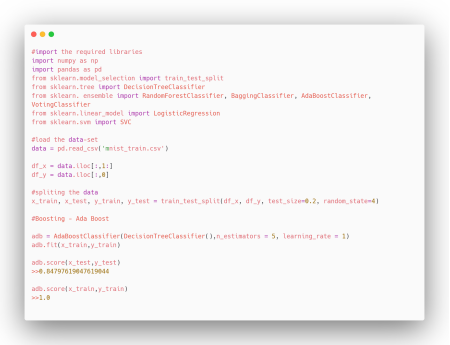
2.Boosting: It Is An Iterative Method Which Allows You To Adjust The Weight Of An Observation Depending Upon The Last Classification. Boosting Decreases The Bias Error & Helps You To Build A Strong Predictive Model. If I Choose The Adaboost Method,You Train A Sequence Of N Models In The Following Sequence. Let’s Say In Every Training Phase, You Sample The Input Sample And Choose A Small Subset Of It. Then Weight Of Those Samples That Have Been Wrongly Classified In The Previous Phase With Much Higher Weight Than Others. Boosting Is One Of The Sequential Methods And It Is Applied Mainly For Underfitting Algorithms.
Let’s Implement Boosting Technique – Adaboost Practically Using Python For MNIST Data-Set
3.Voting Classifier: Core Concept Of Voting Classifier Is Conceptually Different From Machine Learning Classifier And Uses A Majority Vote Or Weighted Vote To Predict The Class Labels. VotingClassifier Is Quite Effective With Good Estimators And Handles Individual’s Limitations.
Two Types Of Voting Classifier
I. Soft Voting Classifier: Different Weights Configured To Different Estimators
II. Hard Voting Classifier: All Estimators Have Equal Weight-Age.
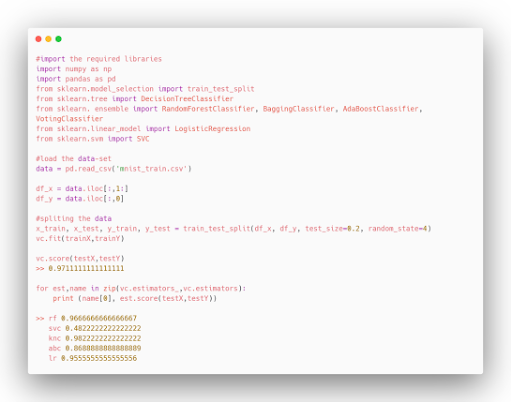
Let’s Implement Voting Classifier Using Python For MNIST Data-Set
1.Hard Voting Classifier
2.Soft Voting Classifier

Find the code Here
Endnotes:
The main of using Ensemble Learning models is, in the end we try to achieve low bias and low variance for better model performance.
Thanks for reading!
Article by: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other technical and Non Technical Internship Programs