

Multi-Label Text Classification means a classification task with more than two classes; each label is mutually exclusive. The classification makes the assumption that each sample is assigned to one and only one label. On the opposite hand, Multi-label classification assigns to every sample a group of target labels.
this may be as predicting properties of a data-point that aren’t mutually exclusive. Multi-label text classification has several applications like categorizing businesses on Yelp or classifying movies into one or additional genres.
Let’s take a Stack Sample dataset from Kaggle, for performing multilabel classification.
Dataset for Multi-Label Text Classification:
StackSample: 10% of Stack Overflow Q&A | Kaggle
Firstly, import libraries such as pandas, NumPy for data framework and learn for model selection, extraction, preprocessing, etc.

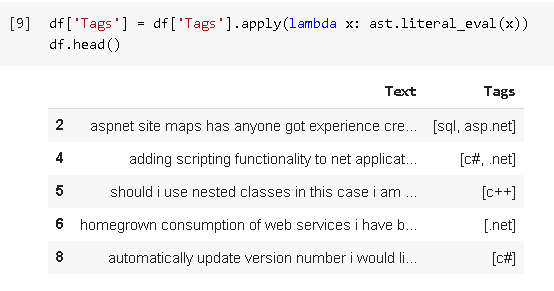
Read the dataset by pd.read_csv and write df. head() to see the top 5 data from the dataset.

The ast.module is use for evaluation which helps Python applications to process trees of the Python abstract syntax grammar. This module helps to find out programmatically what the current grammar looks like. In this, it will convert the string into a list.

Here, I am using a lambda function which will iterate over each row data, and then that data will be placed inside x, then will perform an ast.literal_eval function which will change all the ‘Tags’ data into a list.
From sklearn we import MultiLabelBinarizer which will convert the data in the ‘Tags’ column into One hot encoding.

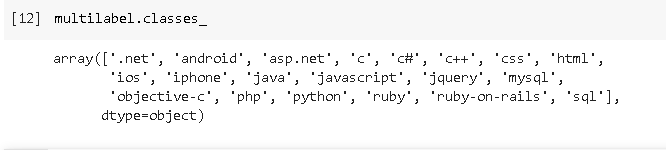
As you can see we got our Tags column data into One hot encoding and we can check their classes by typing multilabel_classes_ .
Here, I have taken the top 20 classes from the dataset because it will take less time for training and testing the model.
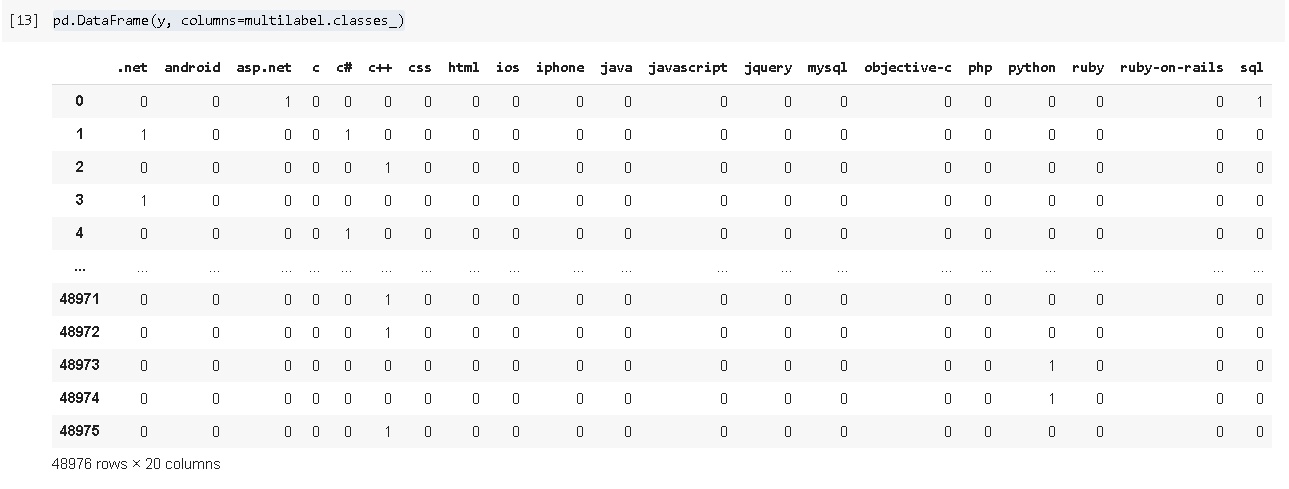
You can see this into a data frame by running this command pd.DataFrame(y, columns=multilabel.classes_) .
TFIDF Vectorizer:
It is described as Term Frequency X Inverse Document Frequency vectorizer. It has an analyzer input parameter which we can set as ‘word’ which is default and we can also change it into ‘char’,’char_wb.’ So if the analyzer is set as word then it will do tokenization word by word and if you set it as char then it will do tokenization character by character .char_wb it is character word boundaries which will do tokenization with character as well as to detect the word boundaries.
Max_features:
It will ensure that we shouldn’t dictionary size more than selected max_features by the user. So, here I am selecting 1000 as my max_features.
After that,tfidf.fit_transform is used to transform the data which is stored in a column named ‘Text’ which obtains the title and body of the stack flow questions of the dataset.
Training and Testing of the Dataset :

Training and Testing of the Dataset :

In this, the train_test_spilt takes the X takes the input variables as well as Y takes the input variable but here, x is a feature and y is a target. Apart from that, set the test_size as 0.2 and random_state as 0.
Building the Model:
Machine Learning Algorithms:
Import the models such as Logistic Regression, SVC, and SGDClassifier (Stochastic Gradient Descent) from sklearn.

Jaccard similarity methodology that is applied by taking the is that the size of the intersection of the expected labels and therefore the true labels divided by the dimensions of the union of the expected and true labels. It ranges from zero to one, and one indicates a good score.

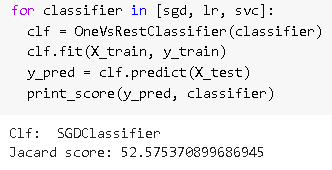
Create a list sgd,lr,sv and set clf as Onevs RestClassifer which means we have 20 classes in the output t.In which we’ll take one class at a time and then it takes rest of 19 classes as all other classes and do the same with each data. Using clf.predict(X_test) it will store the prediction value in y_pred and print the prediction score for the LinearSVC model.

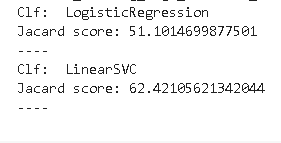
clf.fit(X_train,y_train) by using this it will start training this model then using y_pred we will predict the data taking X_test data and print the prediction score. Below shows the accuracy of the model i.e SCDClassifier, LogisticRegression, and LinearSVC.
Model Testing:
Here, we can test the model using real data. for this type of text for example “I don’t know anything related to java and python” and store it in variables such as x.
Then pass tfidf. transform with x and store in xt and then do clf. predict on this data an array of o’s and 1’s in which 1 indicates the predicted labels that belong to x.
To see which classes we need to write multilabel.inverse_transform(clf. predict(xt)) then it will show us the predicted label for the x data.
As you can see the predicted labels for the x are shown below i.e java, ruby.

Conclusion:
First, we’ve loaded the text pre-processed dataset using pandas data frame and additionally evaluated the string tags.AST module and encoded the tags using Multilabelbinarizer.
Thereafter, we’ve performed the Text Vectorization on Question sort data using TfidfVectorizer. Finally, we’ve matched the model on numerous classifiers like LinearSVC, SGDClassifier, or supplying Regression for multi- Label classification and expected the output on real information.
For higher accuracy and prediction we tend to model Multilabel text classification RNN, LSTM, bi-directional LSTM, etc.
written by: Kanchan Yadav
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs