
What is Random Forest :

By the name of Random Forest, we think it is just a group of random trees. But in Machine Learning it will Play a Huge Role. It Holds Various Features that Significantly Help to Classify a result or Prediction.
Random Forest is Capable of both Regression and Classification Task. It is based on the Number of Trees. It creates a forest with a Number of Trees. The More No of Trees the More Robust Your Decision Or Prediction Will Be.
In Simple Definition, we Can say Random Forest is a group of Decision trees. In those Decisions, trees have Different Outputs. And this Output will Feed to the Random Forest. The random forest will Predict Output On the Basis majority.
Some Application of Random Forest :
Remote Sensing: ETM (Electronic Ticketing Machines) Devices to Acquire Images.
Object Detection: Multi Labels Object is Done By Random Forest Algorithm
Kinect: Random Forest is used in Console Games Called Kinet. It Tracks Body Movements and Captures in a game.
Why We Can Use Random Forest :
Because,It uses Multiple Trees to reduce the risk of Overfitting a Model . And Training Time is Also Less.Run efficiently on a large database. It Can Also Maintain Accuracy When a Large Proportion of Data is Missing.
Random Forest – Important Terms?
Entropy: It is a Measure of Randomness in the dataset.
In our Data When we Much Randomness that time we called it High Entropy E1.
After Splitting, we called it Lower Entropy E2.
Information Gain: It is a Measure of Decrease in Entropy after the dataset is Split.
Leaf Node : Leaf Node holds the classification or a Decision.
Decision Node : Decision Node has two or more branches.
Root Node : The UpperMost Decision Node is Known as the Root Node.
Gini Index : Random Forest uses the gini index for the node impurity.It is a Measure Most Commonly chosen for Classification type Problems. If any Dataset contains the example of another class then it would be calculated.
Gini Index can be Defined as :
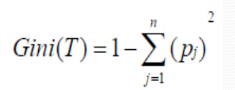
Steps in Random Forest Algorithms( with example):
Let the number of training cases be N, and the number of variables in the classifier is X.
The number X of input variables are used to Determine the Decision at a Node of the Tree,
For each node of the Tree, Randomly Choose X variables on Which to Base the Decision at that Node.
Each tree is Fully Growed Not Pruned.
Let also Understand with Flow Chart:
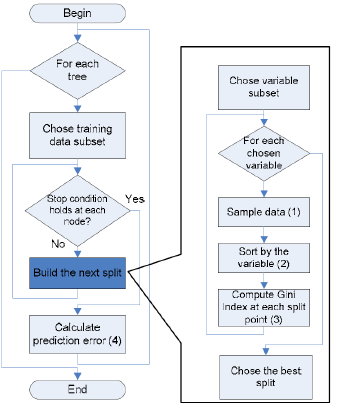
As we see Each For each Node we choose the Training data subset. It first checks the condition if yes then it should calculate the prediction error and if No choose a variable subset for each variable then it sorts the variable and Calculate a Gini Index at each point and give the best split to the condition, Condition will check it Again and calculate the Predict error and it Terminates.
Advantages/ Disadvantages :
Advantages :
-Here are some adv of using Random Forest :
-Both Classification and Regression Task
-Handle the Missing values and Maintain Accuracy for Missing Data
-Wont Overfit the Model
-Handle Large Data set with Higher Dimensionality.
Disadvantages:
-Good Job at Classification but not good as for Regression
-You have a very Little Control on What Model Does.
Let’s Do One Example:
Code :
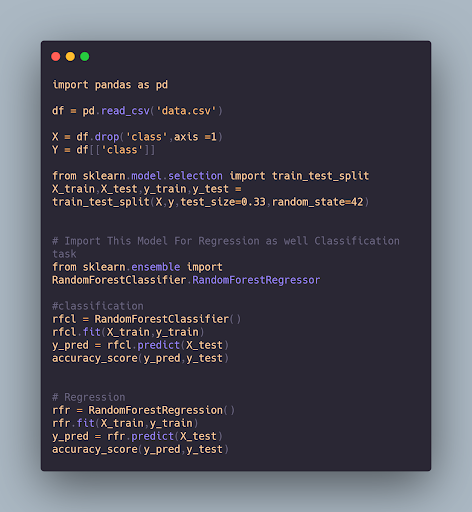
With the above code, we just read the data and identify our X and Y Which are our Inputs and Output. Then We Split the Data and Feed to the Classifier or Regression Model. it Will Predict Output based on Our Labels and After that, it will Find the Accuracy on the basis of predicted value and our test data.
Conclusion:
With Random Forest we Understand it is a good Algorithm for both the Classification & Regression Task to Predict a Predictive Model. It also will handle missing data with no overfitting and It Predict an output based on the Majority.
Article by: Chandra Prakash Mewari
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other technical and Non Technical Internship Programs