
Let’s say that you’re creating a Machine Learning model to predict housing prices for your locality. The usual steps you would go through are:
1.Defining the problem
2.Obtaining raw data
3.Cleaning and processing the data
4.Deciding what frameworks and algorithms to use
5.Training and evaluating the model.
6.Deploying the best-performing version of the model.
A good practice when creating such models is to keep track of “Loss” incurred during the training and testing processes. Loss, also known as Error, is the difference between the model’s outputs and the actual output values corresponding to the input data. Loss can be defined in a more robust form but let us just stick to this simple one for the time being.

Now that you have implemented a method to track this error in your training methods, it is also beneficial to plot these results. This way, we can visually interpret how the model is performing even before having to improve the model definitions – if required that is.
Let’s consider an example:
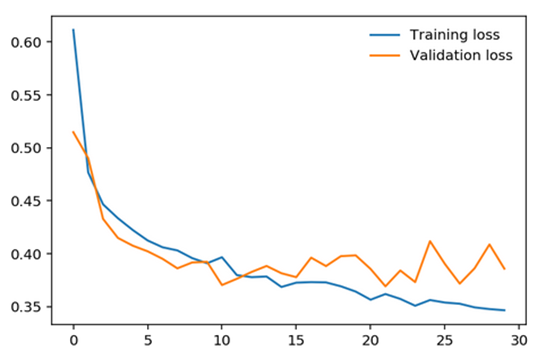
Here a model was trained on some dataset over 30 iterations, also called epochs and the losses were plotted.
Note: depending on the size of the dataset, 30 iterations might seem excruciatingly time-consuming, but it is always good practice to implement your training method in a way that will result in maximum performance.

(Pay no attention to the axes values. Depending upon the choice of loss/error representation and number of iterations, they may appear different to you)
As you can see from the plot, the model seems to have performed splendidly on the training data. We can tell that it can make predictions with near perfection. In stark contrast, the performance on the test data seems to be abysmal. The loss curve only marginally drops down before shooting right back up to its initial level. This situation is far from ideal and would be disastrous if the model was deployed to the user-base – lots of unsatisfied people plus all that bad PR!
What is happening here though?
This striking difference in the performance of the model on the two datasets is a common problem. It is the result of the model’s failure to generalize on data – this means that it doesn’t know how to react when new or unseen data is provided and is only effective on whatever data it was fed during the learning process. This is formally called Overfitting.
So how do we tackle this problem?
“Cross-validation”
Cross Validation is a statistical method that is usually implemented to improve the performance of a model. It is used by statisticians to see how their algorithms perform in the real world – i.e. a fool-proof evaluation technique.
Technically, we have already covered the most basic form of cross-validation. The splitting of data into training and testing sets is a very simple, and often adequate, method used in performing cross-validation. It is generally known as the “Holdout method”.
As we have seen, this simple method may not always provide satisfactory results. The next step towards improving performance is the addition of another split in the dataset. We are now talking about a training set, a testing set and a validation set. This newly added dataset is a functional mixture of the other two. It is used in evaluating a trained model – as with the testing set, but it is also considered to be an extension of the training data. We use this extra dataset to fine-tune our model’s parameters post-training and improve its performance.
With the addition of just one step, we have significantly improved the performance of our model. It is now guaranteed to generalise on unseen data such as user inputs. If needed, we could further improve the performance by tuning the parameters based on the outputs from this entire process.
But there is a catch!
This method tends to work best when we have access to tens of thousands of feature-rich data points. Unless you work for a giant corporation that can provide such an enormous dataset, you will likely be performing those splits on a much more restricted amount of data – especially in a scenario like your local housing prices problem. This in turn results in our model having fewer data points to learn from thereby affecting its performance – meaning that the extra validation step we took would be rendered pointless. This is commonly known as Underfitting.
The most challenging (and crucial) aspect of machine or deep learning is finding that sweet spot between under and over fitting where everything just…. Fits! And even seasoned veterans fail to achieve this in their first attempt at a project.
Luckily there have been many advancements made in Cross-validation techniques.
K-fold Cross-Validation:
A major cause for concern in the holdout method is the inclusion of sampling bias in the datasets. This refers to the possibility that the model may miss out on important information during the training process as a result of how the data is split. We have no control over how the split is made since the process is randomised and the same subsets are used throughout the remainder of the training and validation processes.
To tackle this issue, we use the k-fold cross-validation method. Here, the dataset is split into k equally sized parts. Of these k subsets, one is randomly designated as the testing dataset and the remaining k-1 subsets are used for training the model.
The process is performed k number of times and each k subset is used as the test dataset exactly once. This means that different portions of the dataset are used during the evaluation process while also ensuring that there is no repetition. This effectively decreases bias thereby greatly improving model performance. At the end of each iteration, the loss/error is accumulated, and the model is discarded. After all the iterations have been performed, the total error value is then averaged to provide the final measure.
Image source: http://ethen8181.github.io/machine-learning/model_selection/model_selection.html

Leave-p-out Cross-Validation:
This is an exhaustive approach to cross-validation. Here, we take a dataset of size ‘n’ and assign from it, a certain number ‘p’ of observations as the evaluation set and use the remaining data to train our model. This process is repeated until all possible combinations of ‘p’ from ‘n’ are laid-out and the model is trained and evaluated by the number of iterations given by:

Note: This is the generic formula for Binomial Coefficient. ‘r’ here represents ‘p’ stated above.
This is rightfully termed “Exhaustive approach” since depending upon the numeric values of ‘p’ and ‘n’, the number of total combinations can sky-rocket – much like the computational expenses from processing all this data! For example, selecting 10 subsets from a dataset of only 50 observations:
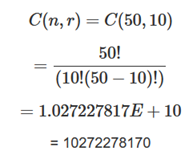
That is an insane number of iterations to perform. Good luck sitting through all that – just to realise that you have made a mistake in the implementation and now you must start all over again!
Code Implementation
The most commonly used library for implementing cross-validation is Scikit-Learn.
K-Fold Cross-Validation:

We can make use of the model_selection module from sklearn to implement the k-fold cross-validation.
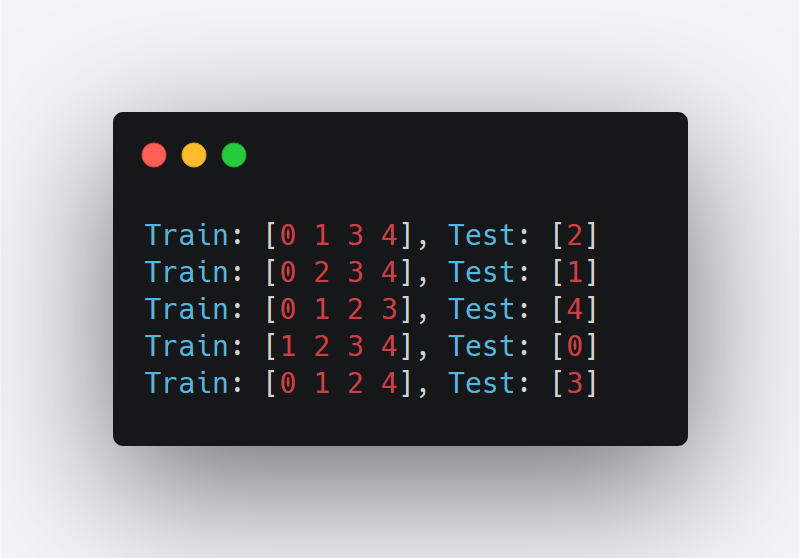
I have created a very basic dataset using numpy.array 5 data points with two features each – and the corresponding outputs. An object is created from the KFold class and the number of splits is set to 5 – i.e. a 5-fold Cross-Validation.
The outputs (indices of the array) from the print statement are:
Leave-P-Out Cross-Validation:

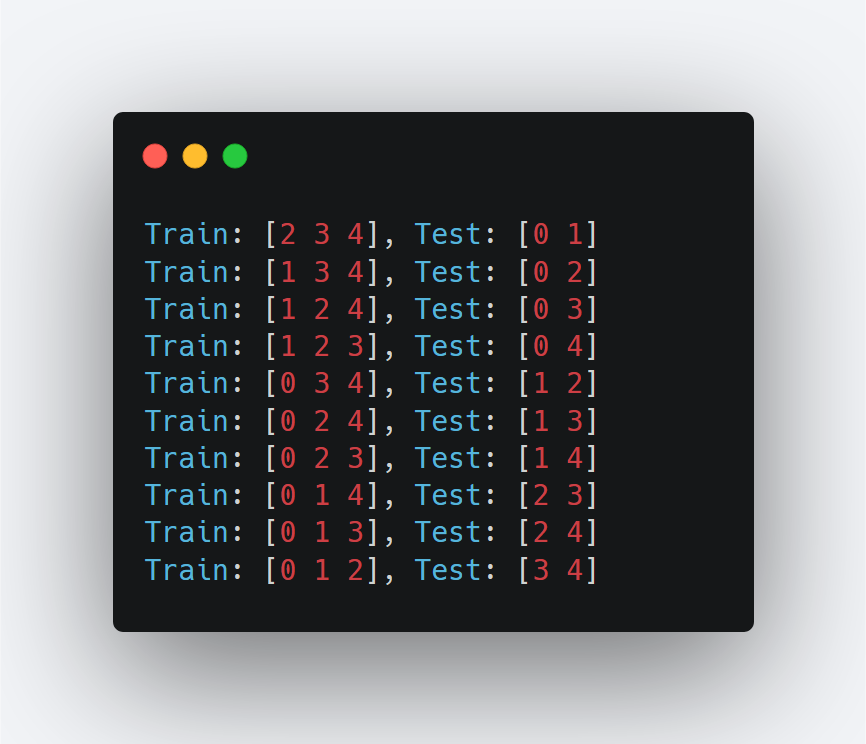
As you can see, the implementation is almost exactly the same as with the k-fold CV. The LeavePOut cross-validator only takes in one argument, which is the p value.
The output indices from the print statement are:
Now that we’ve got the training and testing datasets split up, we can continue with the training and evaluation of the actual model.
Although there are numerous Cross-Validation techniques, the k-fold and leave-p-out methods are the most widely used. Many of the other methods are either special cases of or mere derivations from these two, for example:
· Leave-one-out is a special case where r = 1.
· Leave-P-groups-out
· Repeated k-fold is where the k-fold process is performed for n iterations.
· Stratified k-fold
This post is merely an introduction to the process of validation in machine or deep learning. Innovations on existing practices are continuously being made and adapted. Despite the numerous libraries and frameworks that can be made use of, the model-architect must be able to creatively implement the fundamental logic behind these techniques in order to maximize the performance and satisfy their clientele.