
Introduction: Object Detection
We humans when we see the images over the phone or in any other way, our brain can easily identify the contents inside the image. If we talk about machines it’s not easy to identify because it needs lots of training data and test data to learn before identifying. But this is not at all easy and we won’t follow these steps every time right?
Is there any other way or advancement in the process. Yes, we have a concept called Computer Vision, where we can perform object recognition, detection and etc using this beautiful concept.

Pic Credits : Google
Check out the above image, where the machine has correctly recognized the contents in the image.
In recent times object detection has rapidly used technology in many sectors and also a fastest growing technology too. We use object detection use cases in self-driving cars, social distancing (during covid-19 pandemic) and in manufacturing companies to check the quality factors and many more fields of object we use detection concepts.
What is Object Detection?

Let’s consider an above image where we can see a cat hiding inside the carpet. We humans can easily identify or detect but when it comes to machines then we have to feed them with training data with multiple images then it will identify the cat or any other things in the image. The above picture is actually the detected image with a label attached to the object.
In object detection we actually do image classification and localization where we get the output as shown in the above image. The first task in the object detection to check whether the cat is present in the above image or not. If there is a cat in the image then it should mark where it actually exists. Basically the confident value we get with the width and height of the detected cat in the image. The marked box is actually called a bounding box.
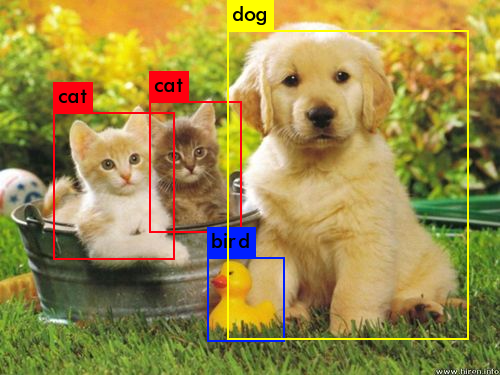
We can also implement this concept when we have multiple objects in the image. For example consider the below image where it contains multiple objects like cat, dog and bird. This is how it detects the objects when we have more than one object in the image. When we come to the output for this type of image, here the confident value is different for different objects with corresponding width and height.
Why Deep Learning for object detection?
The deep learning concept we usually use when we have a huge amount of data to train and it works fine providing good accuracy. It learns each feature distinguishing in the image with good accuracy in return. Neural networks will work fine for object detection as a basic algorithm with better accuracy and we have different techniques for object detection that will be discussed later in the tutorial.
We will face a major issue i,e computational. This computational part will be done while detecting the object in the image and we will fail to get a good number of accuracy but when we use deep learning neural networks it actually shares the computation while computing the features and with better accuracy and also speed too.
The deep learning learns enough features distributions and is also able to generalize well on new unseen images in the testing part.
Usually when we research this object detection concept, no other company or person is actually using the old traditional image processing techniques. They are move into deep learning techniques like neural networks for better accuracy and speed.
When we dive deep into the neural network in object detection space, we have actually two different categories for object detection:
- One Stage Object Detectors : In this category we usually use the techniques like YoLo, SSD, Transformer based neural network
- Two Stage Object Detectors : Here the techniques we use is Faster RCNN
Let’s explore the Faster RCNN category technique briefly.
1. Faster RCNN
Let’s first understand what R-CNN is. R-CNN is a Regional based convolution Neural Network which is propose by Ross Girshick and team. R-CNN is the first algorithm in the series before Fast and Faster R-CNN.
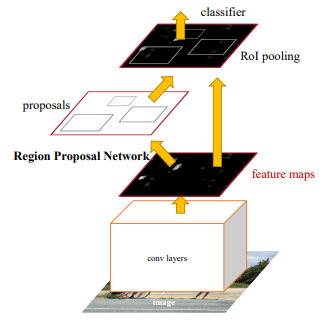
The above picture is the architecture of the faster R CNN algorithm which we basically use for object detection.
Step 1: Region Proposal Network(RPN)
In this region, it will check the possibility of objects in the image which means in which area the object is present in the image.
Consider if we provide the cat image as input, then in the RPN it will check the area in which the cat is present in the image. If you found the area in which cat or any other image is found then we will label that area as a foreground class and the area where the object is not found will be labeled as background class.
The Foreground label will be moved to the next stage of the process.
Step 2: Generate anchor boxes
What are anchor boxes?
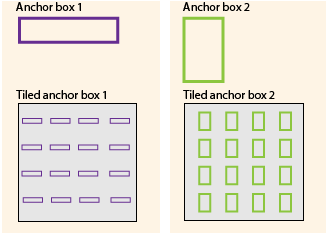
Anchor boxes are nothing but pre-defined bounding boxes. See the above image where we can see two different anchor boxes with different sizes. The height and width of the anchor boxes is way different. We want these anchor boxes because when we want to capture the object in the image, where we can’t tell this might be the size of the object and we can use these anchor boxes. So when we encounter different object over in the image we need different size anchor boxes

See the above picture, where we can see the different size anchor boxes for detected objects with respect to the size. Once we generate the anchor boxe/s our next step is to calculate the IOU.
IOU is nothing but Intersection Over Union. Which computes the intersection over union on these 2 bounding boxes.
Step 3 : Bounding boxes prediction and classes
In this we will be using a fully connected neural network which will be our input followed by Region Proposal Network. At the end of this it will predict the object class with bounding boxes prediction.
Endnotes
In this article, we have covered almost everything under object detection and also with one important technique we learnt. Hope this article gives you insight for your learning.
Written By: Krishna Heroor
Reviewed By: Umamah
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs