
Introduction to machine learning

Source : https://www.ie.edu/exponential-learning/blog/data-science/machine-learning-marketing/
1. “Data is the new oil”
- If we consider 10-15 years back we don’t have smartphones and the internet. When the internet comes a generation of huge data starts. Now if we exploit the data we can launch big businesses and many more profitable things. Because everyone is generating data in the world currently 2.5 quintillion bytes of data are produced by humans every data. From this, we conclude that data is driving the world.
- Example: If google sells the data of people who are traveling for office to home at a particular time in a particular place to make my trip(travel company).They can launch a bus for these peoples at affordable costs which will be useful for the peoples and also improve their business
2.“ Machine Learning is a concept and framework for making the best”
The area of Machine learning started working is in the early 1950s but it gained momentum now because of the rise of the internet and we are generating large amounts of data.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it learn for themselves.
The process of learning begins with observations or data, such as examples, direct experience, or instruction, in order to look for patterns in data and make better decisions in the future based on the examples that we provide. The primary aim is to allow the computers learn automatically without human intervention or assistance and adjust actions accordingly.
Traditional Paradigm:
- The Developer writes the code(program). The data (inputs) is provide to the computer and then the computer computes it in an executable file and the output then generates.
- The output is deterministic(certain).
- E.g – Addition of 2 numbers.
Machine Learning Paradigm
- Once the model (brain/concept) is ready, we no longer need the data.If you need to train for new data you need to train it back
- e.g – If a student is provide with a Question Bank(Data) and the Answer Key(O/p) and the student reads it and understands the concepts completely, he/she no longer needs the QB and AK and he/she can now solve the problems based on the knowledge gained.If we well versed in the concepts they can score more in the test determines the level of understanding the concepts
- In this model, the output is predictable. It is not deterministic.
- ML does not require any hand-coded rules or complex flowcharts and it is all about predicting unseen data.

ML – Formal Definition
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
ML is all about –
- Improving performance P
- at executing some task T
- overtime with Experience E
e.g- Categorizing the emails in the inbox as spam or ham(other than spam known as ham)
- The number (or fraction) of emails correctly classified as spam/ham– P
- Classifying emails as spam or ham — T
- Watching you label emails as spam or ham – E
TYPES OF MACHINE LEARNING METHODS
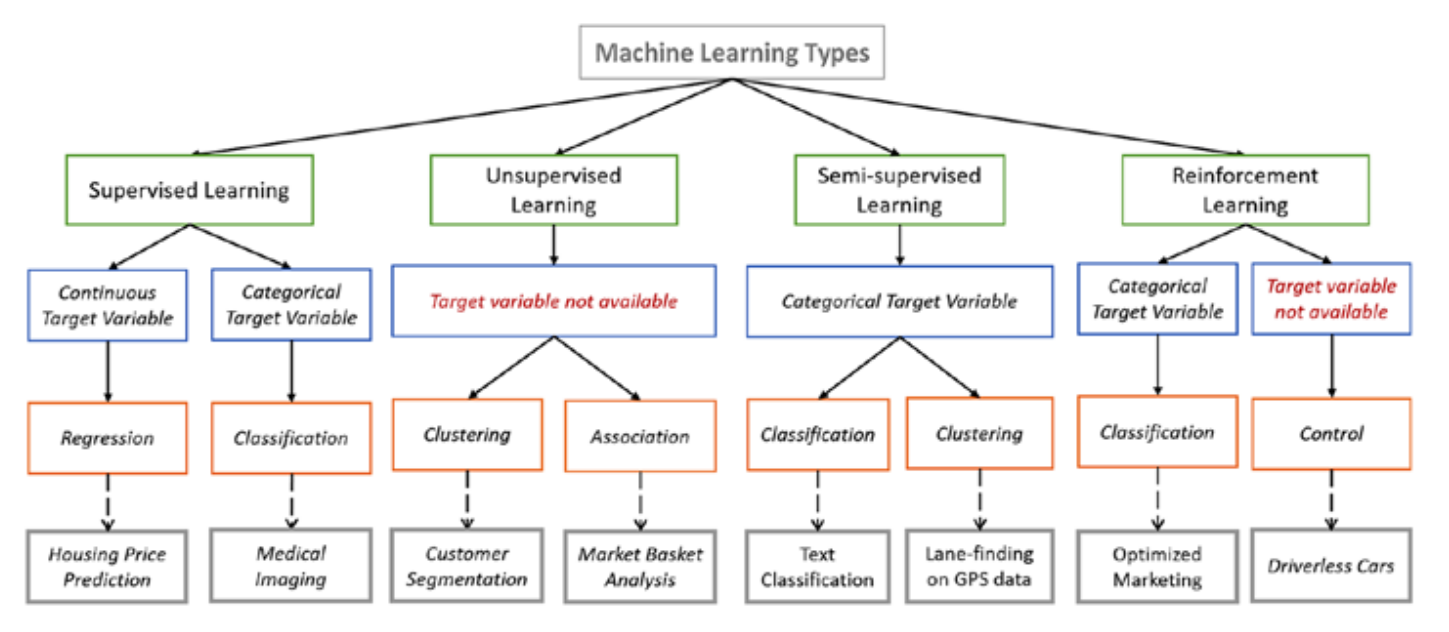
1. Supervised learning
Learning in the supervision of someone(Trainer/Supervisor).
CLASSIFICATION
- The output is Categorial or discrete in Nature.
- Example – A child has been taught that shape with 3 sides and edges with corner is a triangle and 0 sides and edges are smooth is a circle. So, whenever he is given the no. of sides he can categorize it into a triangle or a circle. If it is a square he will say only from the trained class. It is the drawback of classification.
- Machine Implementation – In a machine, a graph is plot based on the data(independent variables). e.g – Sides on the x-axis and circular nature on the y-axis. Then, the data is plotted and clustered into 2 categories – Triangle and Circle.
- The Machine draws a line between these 2 clusters and calculates the error. The Line such that it equidistantly separates the 2 categories and has a minimum error is found.
- This Line helps to categorize the data easily. ( if the data point lies on the side of the triangle, its a triangle, or if it’s on the side of circle, its a circle.
Classification Example
Real-world Example -:Weather Prediction – The model is trained on a dataset of previous days dataset and fed with output labels ( Sunny or Rainy) based on the independent variables such as precipitation, humidity, pressure, temperature, etc. Then, the trained model is fed with new unseen input(data). Based on its learning, it will predict the output as Sunny or Rainy. So the output will be discrete.
Regression
- These types of tasks usually involve performing a prediction such that real numerical value is output instead of a class or category for an input data point.
- The output is Continous and A Simple regression has only two variables x(sector) – Feature variable Y(price) – Target variable —> Linear regression
- Example- Predicting the price of houses based on the sectors(1 to n) in which it is situated. The graph is plotted with Sector number on the x-axis and price on the y-axis. Then, LOBF(Line of best fit) is drawn such that it passes through maximum points. Then, when someone wants to know the price he/she can charge for a house in a particular sector, it can be found by finding out the y- coordinate(price) of the line(LOBF), when the x-coordinate(sector number. is known)
- Multiple Regression: When there are multiple independent variables on which the dependent variable(the price of the house) is dependent on such as (Sector, BHK, Transport, School, Amenities, Hospitals, etc. , ) the LOBF becomes a curved graph (polynomial)
- All of the x values are independent and the y value is dependent.
2. Unsupervised Learning
- Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses.
- No supervisor or teacher does not exist
- Example: A son learning to ride a bicycle from his father is supervised learning, whereas he learning to ride a bike by looking at others without any assistance/trainer is unsupervised learning.
i. Clustering: Anamoly Detection
” Throw the cluster and let the user decides”
- E.g – Consider an employer, looking and analyzing at the log records of all the employees’ computers during office hours. He records the Employee ID and the hours of work done by the employee.
- Here, the machine will just plot the Employee ID on the x-axis & hours of work on the y-axis.
- The employer/owner will manually analyze the graph and find out who is spending how much time where.
- Say, the employer notices that the employees can be divided into 4 clusters based on the graph. He/She analyzes the history of some points from each cluster and finds out that the following info-
| Cluster | Analyzed Data |
| A | Spends only 3 hr on office work and spends rest time on FB. |
| B | Spends only 4 hr on office work and the rest of the time on Insta. |
| C | Spends 6 hr on work and the rest of the time searching on Linkedin, joboffer, naukri. com |
| D | Dedicates all 7 hrs to work |
- Analyzing this data will help the employer take suitable measures on appropriate people. Like he/she can organize motivational sessions for employees in cluster A & B to make them work harder. Also, he can notice that the employees in Cluster C are unhappy with their current job, so he/she can look into the matter and help them out.
iI. Dimensionality reduction
It’s all about identifying the useful features and discarding the others!
- Feature space gets bloated up with a humongous number of features
- This problem of having many features which are of no use to obtain the o/p –> “Curse Of Dimensionality”.
III. Association Rule-Mining
- Examine the dataset and find patterns and rules. Often named as market basket analysis.
- Association rule will decide what thing need to be added along with one and another
- E.g- Amazon giving generic recommendations such as – whenever you buy a mobile, it recommends you to buy a back cover or a screen guard because it has observed the pattern that the ones who buy a mobile phone also usually buy these things.
- Remember that the personal recommendations given by amazon based on your personal buying interests which you may search do not come under this.
3. Reinforcement Learning
- Learning from own observations.and its learning process is continuous
- It is a bit different from conventional supervised or unsupervised methods.
- It has an agent who works on the based on the actions it gets a reward(when beneficial) or penalty(when detrimental) policy.
- E.g – Google’s Autonomous Car – Here, Agent—> Car. Say it is learning to drive on a speed breaker. It has a particular score at the beginning. First Trial – It has no idea, it drives at 70km/hr speed. So, it realizes its detrimental and penalizes itself with -ve 10 score. Second Trial – It now decreases its speed to 40, although it has a better experience than the previous time still it is not optimal. So, its penalized with -ve score.
- These trials continue until the car learns the best optimal speed to cross the speed breaker and reward itself with a +ve score.
Example: AI-enabled Chess – In round 1, If human plays with strategy 1 and wins the game the machine will understand the strategy. In round 2 if human uses the same strategy machine will win. If it loses multiple times also its knowledge is getting bigger and bigger.
4. Semi-Supervised Learning: Combination of both supervised and unsupervised learning
Classification based on Incremental Data Samples:
- Instance-based learning
- Uses the raw data points themselves to figure out outcomes for the newer or previously unseen data samples
2. Model-based Learning
- Model-based Reinforcement Learning refers to learning optimal behavior indirectly by learning a model of the environment by taking actions and observing the outcomes that include the next state and the immediate reward.
Classification based on Incremental Data Samples:
1. Batch Learning
- The model is train in with a particular dataset in one go and then it stops learning.
- The major drawback that the model is going to stop learning after the trainer.
2. Online Learning
- Training data is fed in multiple batches and it keeps on learning.
- E.g – Stock market forecasting – where we continuously update the model with new training sets.
- The drawback is training by bad data samples can affect the model performance adversely.
- All ML methods work in the principle of “Garbage in and Garbage out”
Need and requirement of Machine Learning
- In this decade every business and organization is facing the challenge they are trying their best to using all the possible data and in order to make better and better decisions. That we don’t have data then the technology can’t survive. Every new technology is depending on the data.
- Human beings are the most advanced and intelligent lifeform on this planet at the moment.
- We really need machine learning to make data-driven decisions at scale using the power of reasoning or intuition.
- Excel also can do that but after reaching 20000 rows it will start hanging and can’t perform operations.
- The machine is able to process huge data. If we have the number of a million of data then machine learning is the better choice
- Machine Learning uses the data itself to drive decisions of using programmable logic, rules, or codes to make these decisions.
- Machines can be trained for doing a specific task for a number of times with accuracy and Machines provide a great efficiency at larger scales of data.
E.g- You have maintained a list of how your conversations with your friend are(Good or Bad) for some 100 and situations you will make the decision to lend money to him/her if there is more Good than the Bad. Here humans can only consider only the main 10 or 15 situations but the machine can consider all data and drive the decision.
Written By: Prateek Kumar
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs