

When we refer Supervised Learning,the first question comes that algorithmic program ought to be used that is easy to know and straightforward to implement. K-Nearest Neighbor (or KNN) is that the right alternative because it is one in every of the foremost used supervised Learning algorithmic program attributable to its simplicity.
KNN is one in every of the simplest Machine Learning algorithmic program supported supervised Learning. K-Nearest Neighbor assumes the similarity between the new data and available cases and put the new one into the category that is most similar to the available categories of data.
K-Nearest Neighbor
KNN algorithm can be used for Regression furthermore as Classification however it’s most used for Classification problems.
- Non-parametric algorithm: KNN is non-parametric algorithm,it means it does not make any assumptions on underlying data.
- Lazy learner: KNN is a lazy learner algorithm as it does not learn from the training set immediately instead it stores the dataset and at the time of classification,it performs an action on the dataset.
Example: Suppose, we have an image that either belongs to cat or dog.. So for this purpose, we can use the KNN algorithm, as it works on well with the similarity measure. Our K-Nearest Neighbor or KNN model will find the similar features of the new data set to the cats and dogs images and based on the most similar features it will put it in either cat or dog category.

KNN ALGORITHM
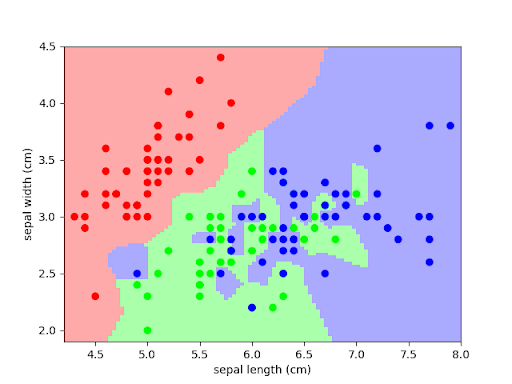
https://scipy-lectures.org/packages/scikit-learn/auto_examples/plot_iris_knn.html
The image above is the problem of classification on IRIS dataset.Notice that similar data points are close to each other. KNN captures the idea of similarity (sometimes called distance, proximity, or closeness) with some mathematics— calculating the distance between points on a graph.
Suppose we have two categories, i.e., Category A and Category B, and there is a new data point x1, so how to decide which category do this data point belongs? To solve this type of problem, we can use KNN algorithm. With the help of KNN, we can easily identify the category of a particular dataset. Consider the below diagram:
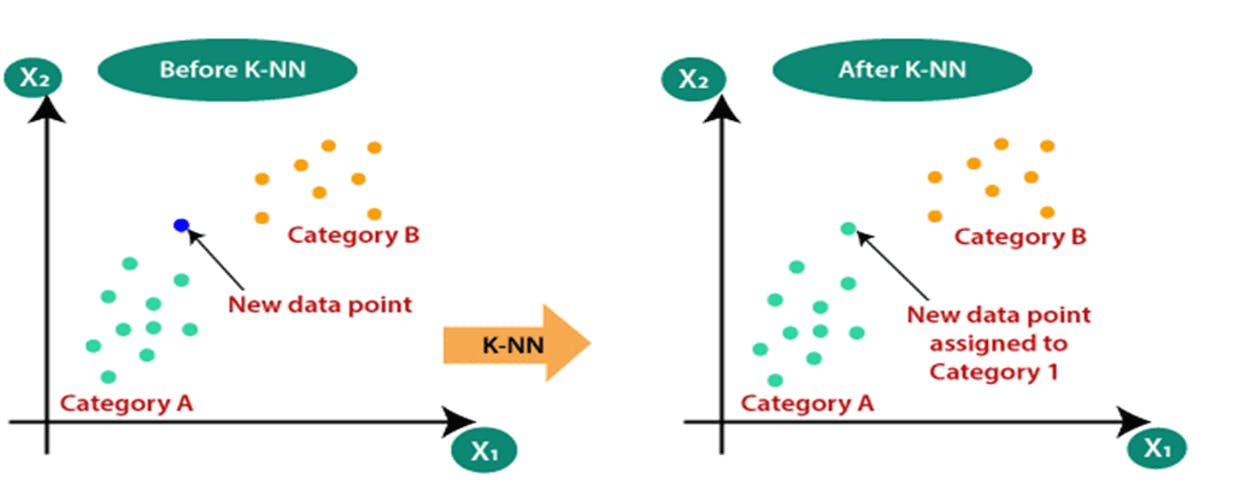
The K-NN working can be explained as:
- Step-1: Select the number of K of the neighbours.
- Step-2: Calculate the distance of K number of neighbours.
- Step-3: Take the K nearest neighbours as per the calculated distance.
- Step-4: Among these K neighbours, the algorithm will count the number of the data points in each category.
- Step-5: Assign the new data points to that category for which the number of the neighbour is maximum.
- Step-6: Our model is ready.
Suppose we have a new data point and we need to put it in the required category. Consider the below image:

- Firstly, we will choose the number of neighbours, so we will choose the k=5.
- Next, we will calculate the distance between the data points. The distance is the distance between two points
- By calculating the distance we got the nearest neighbors, as three nearest neighbors in category A and two nearest neighbors in category B. Consider the below image:

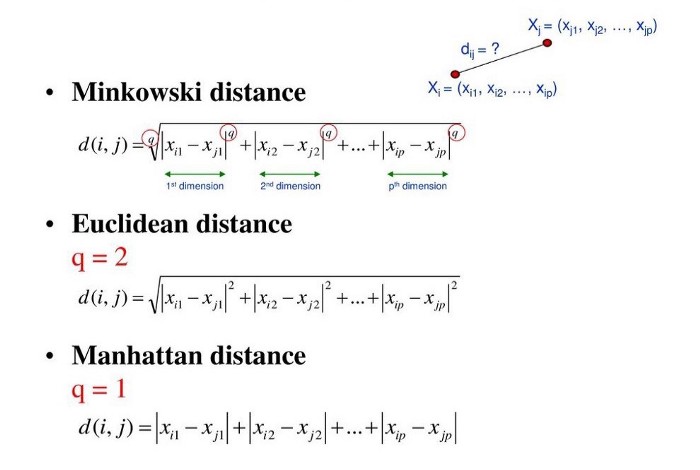
How to calculate the distance?
Usually there are three types of methods that can be used to calculate the distance.
- Minkowski Distance
- Euclidean Distance
- Manhatten Distance
https://slideplayer.com/slide/12735721/
Euclidean Distance is widely in use to calculate the distances between test samples and trained data values. We measure the distance along a straight line from point(x1,y1) to (x2,y2).
KNN IN PYTHON(USING SCIKIT-LEARN)
Scikit-learn is an open source Python library that has powerful tools for knowledge analysis and data processing. It’s on the market underneath the BSD license and is construct upon the subsequent machine learning libraries:
- NumPy, a library for manipulating multi-dimensional arrays and matrices. It additionally has an in depth compilation of mathematical functions for playing numerous calculations.
- SciPy, an system consisting of assorted libraries for finishing technical computing tasks.
- Matplotlib, a library for plotting numerous charts and graphs.
KNN Implementation using Scikit-Learn

CHOOSING THE RIGHT VALUE OF K
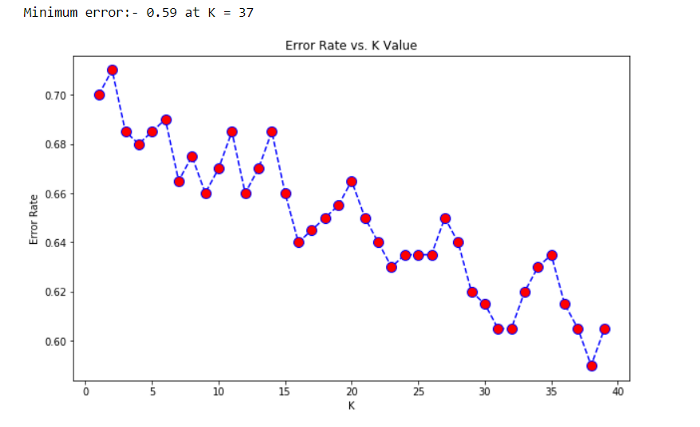
Inorder to settle on the proper value of K,we need to run the KNN algorithm many times with totally different values of K and opt for the K that the error is that the least.So,to choose the K price,we derive a plot between error rate and K denoting values during a outlined vary. Then opt for the K as having a minimum error rate.
You’ll get the insight with the assistance of following example:
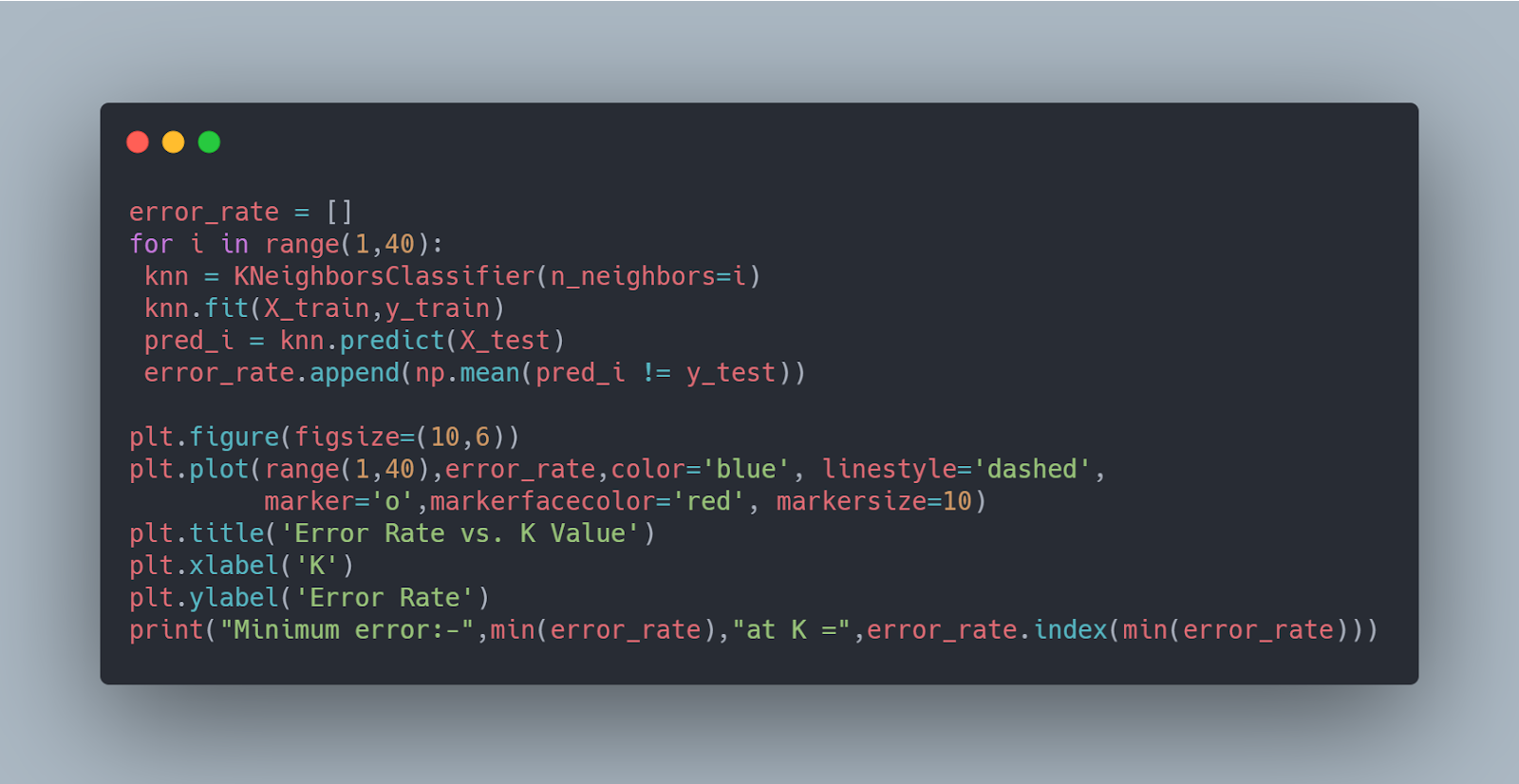
Now,as you can see from the Error Rate Vs K value plot,the error is minimum for K=37.So,for this model K=37 is the optimal value.
ADVANTAGES
- It is simple to implement.
- thus, robust to the noisy training data.
- It can be more effective if the training data is large.
- No need to tune several parameters, or make additional assumptions.
- The algorithm is versatile.
DISADVANTAGES
- Always needs to determine the value of K which may be complex some time.
- The computation cost is high because of calculating the distance between the data points for all the training samples.
written by: Prateek Kumar
reviewed by: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs