
Logistic Regression In Machine Learning
Logistic Regression is a classification technique that is used to predict a discrete set of classes. This algorithm uses the idea of Linear Regression but transforms its output using the logistic sigmoid function to return a probability value which can then be maps to two or more discrete classes.
Logistic Regression Vs Linear Regression
| LOGISTIC REGRESSION | LINEAR REGRESSION |
| It is a classification algorithm. The predicted outputs are discrete classes. | It is a regression algorithm. It predicts continuous numeric output values. |
| In logistic regression, we use sigmoid as an activation function. | In linear regression, no activation function is used. |
| Based on maximum likelihood estimation. | Based on the least square estimation. |
Types of Logistic Regression
thus, Logistic Regression In Machine Learning is categorize into:
- Binary.
- Multinomial.
- Ordinal.
1. Binary Logistic Regression

(https://miro.medium.com/max/713/1*6BLktaLLBRHMIV556X-vew.png)
{kind=link}
As the name suggests in this type of Logistic Regression In Machine Learning, we predict the probability of being a class from a set of two discrete classes. In other words, we predict the odds of being a class. Example: yes/ no, pass/ fail.
2. Multinomial Logistic Regression
Multinomial logistic regression is also known as unordered, polychotomous, or polytomous Logistic Regression In Machine Learning. so, This type of regression is use to model a multi-level response with no order. Example: Color( blue, black, green, red, etc.)
3. Ordinal Logistic Regression
Also known as Ordinal multinomial logistic regression, it is use to model a multi-level ordered response. Example: Low/ Medium/ High.
Sigmoid Function

(https://qph.fs.quoracdn.net/main-qimg-6b67bea3311c3429bfb34b6b1737fe0c)
It is an activation function that maps any real value into another value between 0 and 1. thus, We use the sigmoid function to map predictions to probability.
In the above image, we can see the graph and the formula for calculating the sigmoid function.
Where z = W₀+W₁X₁ + W₂X₂+….+WnXn
Logit Function
It is the natural log of odds that Y equals one of the class categories.

(https://miro.medium.com/max/1168/1*6pnEwGy2Z5z73NasEmC9MQ.png)
{kind=link}
The above image shows the formula of the logit function,
Where P is the probability of a class and (P/1-P) is refer as the odds of a class.
Note: Sigmoid and Logit are inverse functions of each other
Proof:
logit(P) = log ( P/1-p ) = βiXi
we know, p/1-p = eβiXi
p=(1-p) eβiXi, p= eβiXi – peβiXi
p=( eβiXi / 1+ eβiXi )
p= (1/ (e(1/βiXi)+1)), p= 1/ (1+ e-βiXi)
p=1/ (1+ e-z) = sigmoid function
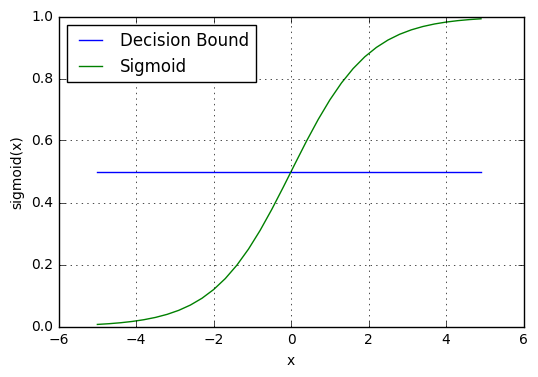
Decision Boundary
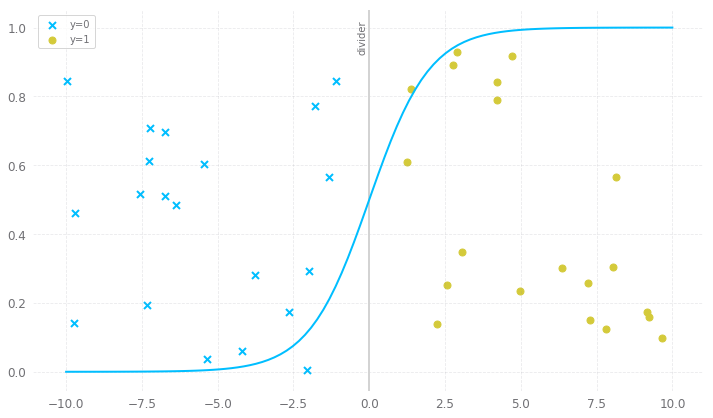
The sigmoid function we discussed above thus returns a probability score of being a particular class between 0 and 1. In order to map this into a discrete class (true/false, cat/dog), we select a threshold value or a tipping point above which we will classify values say class 1 and below that point, we will classify values into class 2.

(https://ml-cheatsheet.readthedocs.io/en/latest/_images/logistic_regression_sigmoid_w_threshold.png)
{kind=link}
Suppose we select a threshold line at 0.5.
P>=0.5 -> class 1
P<0.5 -> class 0
This threshold line is called the decision boundary.
Maximum Likelihood estimator
Maximum Likelihood Estimator (MLE) is a technique that however helps us in determining the parameters of the distribution that best describes the given data. thus, MLE treats the problem as an optimization or search problem. also, For a given joint probability distribution and its parameters, we wish to maximize the probability of that particular distribution.
Code with Example
so, Let us understand Logistic Regression In Machine Learning with the Iris Flower dataset.
The first step is to import necessary libraries
Now we have imported the dataset from the sklearn library.

These are thus The feature values and we have stored these features in a variable ‘X’.
The target of the dataset, i.e. the discrete classes is shown in the images below.

We can also see that we have three discrete classes that are already encoded into numeric values. so, The three classes are ‘Sentosa’, ‘Versicolor’, ‘Virginia’.
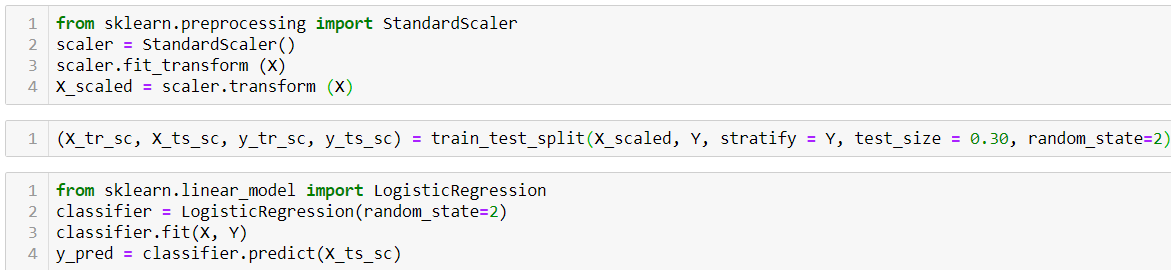
In the next step, we have scaled the data using a standard scaler for better predictions. Then we have divided our dataset in 70:30 into training and testing data using train_test_split. At last, we have imported the logistic regression model and fitted the data for training. so, We have calculated the output for the test data and stored it in a variable named ‘y_pred’.

Finally we have used accuracy as the evaluation metrics and calculated the accuracy of the scaled test data. Now as we can see, this model is giving an accuracy of 95.5%.
Advantages and Disadvantages
Advantages:
- it is easier to implement and efficient to train.
- It is less prone to overfitting when the data is low dimensional.
- A natural network can also be thought of as a stack containing many logistic regression functions.
- This algorithm can be extended from binary to multi-class classifier by using another activation function that is softmax function.
Disadvantages:
- It is prone to overfitting with high dimensional data.
- thus, For complex problems, neural networks and other powerful algorithms can outperform it In Machine Learning.
- It is sensitive to outliers and repetitive data can reduce model performance.
- Non-linear problems can not be solved using it. Since linearly separable data is rarely found in real-world scenarios, we need to transform these non-linear data into linearly separable data. This can be accomplished by increasing features which ultimately results in high dimensional data.
Written By: Chaitanya Virmani
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs