
A GENERAL INTRODUCTION TO LSTM NETWORK.
As everyone knows, the Machine Learning/Deep Learning market is growing exponentially. It is because Machine Learning is getting into various technologies and making it smarter like object detection, machine translation, speech recognition, text summarization and many more. It is making advancement in all those fields because of new and different algorithms like CNNs, RNNs, GRU, LSTM etc. In today’s world the machine Translation, speech recognition is some of the renowned technologies on which every person relies on. So Algorithm that makes these technologies work we need to appreciate the algorithms. Some Machine Translation, speech recognition algorithms are RNNs, GRU and LSTM. LSTM is considering the best algorithm. Long Short Term Memory also known as LSTM networks are kind of RNNs neural networks with some extra and better features. LSTMs have an edge over conventional feed-forward neural networks and RNN in many ways.
A LOOK IN THE RNNS NEURAL NETWORK
As we know that RNNs are better than conventional feed-forward neural networks. These feed-forward neural networks cannot classify what comes next in a sentence during its formation by using its previous word. RNNs have a better edge on the feed-forward neural networks. What RNNs do is they are networks with loops in them, allowing information to persist.

In the above image we can see that a simple RNNs in which Xt is as input and ht is as output and the A is the activation function value which is looped in the network again. So it gets updated every time it goes in the loop.
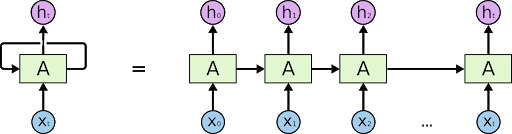
The general form to represent the RNNs networks is shown above. Its looks like that same network has been connected with each other and h1, h2, —-,ht is output of the network.
LIMITATION OF RNNs
Recurrent neural networks work fine when we are dealing with short-term dependencies. For example:
THE COLOR OF THE SKY IS_________.
Now According to RNNs the output is:
THE COLOR OF THE SKY IS BLUE.
But RNNs cannot perform well on long-term dependencies problems. The reason behind this is the problem of VANISHING GRADIENT. We know that for a conventional feed-forward neural network, the weight updating that is applied on a particular layer is a multiple of the learning rate, the error term from the previous layer and the input to that layer. Thus, the error term for a particular layer is somewhere a product of all previous layers’ errors. When dealing with activation functions like the sigmoid function, the small values of its derivatives (occurring in the error function) get multiplied multiple times as we move towards the starting layers. As a result of this, the gradient almost vanishes as we move towards the starting layers, and it becomes difficult to train these layers. A similar case is with RNN also.
LSTM AS A SAVIOUR
Long Short Term memory networks (also known as “LSTMs networks”) are best when you are dealing with the long term dependencies. LSTMs are capable of learning long-term dependencies. LSTMs networks were introduced by Hochreiter and Schmidhuber in 1997 and were popularized by many people very quickly. Their default working is set such that it can remember information for long periods of time. We all know that RNNs have the form of a chain of repeating modules of neural networks. LSTMs also have similar chain-like structure, the repeating modules have different stories within them. Instead of having a single neural network layer, LSTMs have gates in its module. LSTMs module looks like
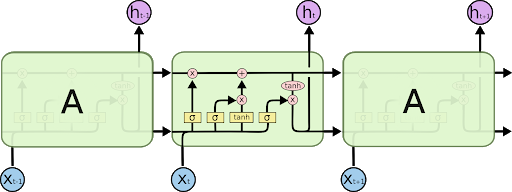
Each layer in LSTMs has a new variable c which is the memory cell. Memory cells help in memorizing something or not. This memory cell is the reason why LSTMs are better when dealing with Long-term dependencies. The cell gate carries relevant information throughout the processing of the sequence.
All gates contain sigmoid activation function. There are a total 3 gates – “Forget gate, Input gate, Output gate”.
Forget Gate – This gate decides what kind of information should be thrown or kept. Now the information from the previous hidden state and from the current state, then it is passed through the sigmoid function which responds only 0 and 1. Closer to 0 means to forget, closer to 1 means to keep.
Input Gate – When we have to update we use the input gate. We pass states to sigmoid and to tanh function and both are multiplied and the output will help us in updating the information.
Output Gate – The output gate decides what the next hidden state should be. We pass the states to sigmoid and to modified tanh function. We multiply both output and we get final output.
CONCLUSION
To sum this up, RNN’s are good for processing sequence data for predictions but suffer from LSTM . LSTMs were created as a way to mitigate STM using mechanisms called gates. Gates are just neural networks that regulate the flow of data flowing through the sequence chain. LSTMs are used in state of the art deep learning applications like speech recognition, speech synthesis, natural language understanding, etc.
Article By : ANKUR OMER
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other technical and Non Technical Internship Programs