
Use of Hyperparameters in Machine Learning.
Now let’s explore this in detail.

Hyperparameters are often used in the Cross-Validation part of Machine Learning. Now, What is Cross-Validation?
Generally speaking Cross-Validation in short “CV” is used to evaluate the performance of the model. CV splits the entire data into various sections and uses these sections for training and testing.
Let’s understand this with an example. Consider an image given below:-
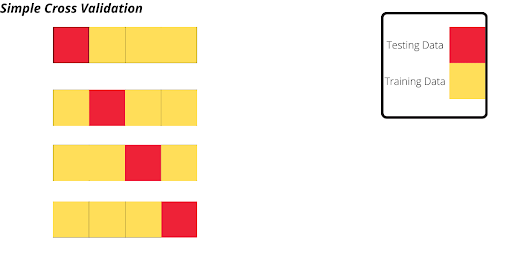
So suppose we have 600 records in our dataset. So out of that record, our cross-validation model will take one record for testing and the rest for training and this continues until every record is trained, so that is a basic Cross-validation example. Now let’s move to Hyperparameters.
Hyperparameters are generally those parameters that often can’t be learnt from a conventional training process. Hyperparameters are quite often used as a Trial and Error Method. Generally, Hyperparameters are often used after cross-validation is done and also used after all the training is completed.
Now let us understand when and where to use hyperparameter tuning step by step:-
First, we train the dataset using some Machine learning model and once trained, we
Discover patterns about our model.
Make predictions for our model.
But even if we follow these steps choosing a correct model isn’t an easy task. Because even in a model type there are other submodels as well. For example, if we consider Neural Networks it is divided into multiple submodels like:-
Perceptron
Back-propagation
Hopfield Network
Radial Basis Function Networks
Note:- It’s not important as of now to know in-depth about Neural Network. And in case if you’re wondering, this is how a simple Neural Network looks like:-
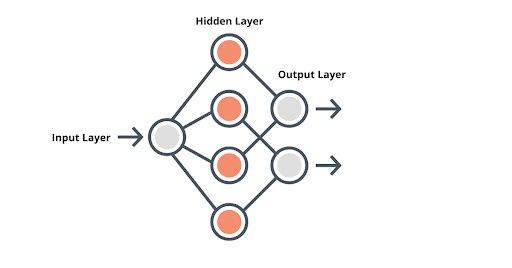
After we finalize on the model type and the architecture we then decide the training and learning algorithms related parameters, which are basically our Hyperparameters.
Hyperparameters basically control the weights and biases of the neural network .Some of the basic Parameters in a Neural Network are:-
Alpha (Learning Rate):- Learning rate is basically used in training of neural networks that has a value between 0 and 1. Usually, Data Scientists prefer using a Learning rate of [0.7]
No. of Iterations:- Iterations is a process of looping over the model until a specific requirement has been met.
No. of Hidden Layers:- A hidden layer is basically located between the input and the output of the neural network and is responsible for allocating weights and biases to the input and finally passes them through the activation function from the output.
No. of Hidden Units:- Hidden Units are the units present in the Hidden Layer.
Choice of our Activation Function:- Activation function basically describes the product of the node given a set of input/output functions.
These are the most common Hyperparameters in a Neural Network. Some other commonly used Parameters are:-
Momentum
Minibatch size
Regularization
Note that all these parameters stated above are to be set by us and are changeable as well. Now you might be wondering, How should we choose these Hyperparameters? Well, there are basically two solutions to this question. First, we can set the hyperparameters manually or we can use some popular searching methods like Grid Search, Manual Search, or Random Search.
Let’s talk about Grid Search first as it is more widely used, Grid Search is a Hyperparameter searching method that thoroughly searches through a set of a manually specified subset of Hyperparameters. Random Search Algorithm, on the other hand, selects the value of Hyperparameters using Probability Distribution.
This was about the Hyperparameters used in Neural Networks. But Hyperparameters can also be used in various Machine Learning problems like Random Forest, Decision Trees and many other regression and classification problems. Now let us look at how Hyperparameters can be used in Random Forest, as Hyperparameter tuning is quite popular in Random Forest. So some of the most commonly used Hyperparameters in Random Forest are as follows:-
N_estimators = It is the number of trees in the forest.
Max_features = maximum number of features required for spitting the nodes.
Max_depth = maximum levels in each decision tree.
Bootstrap = Used for the sampling of data points.
Okay, now assuming that you’ve understood the theory part now we’ll look at a practical example where Hyperparameter is required for Random Forest.
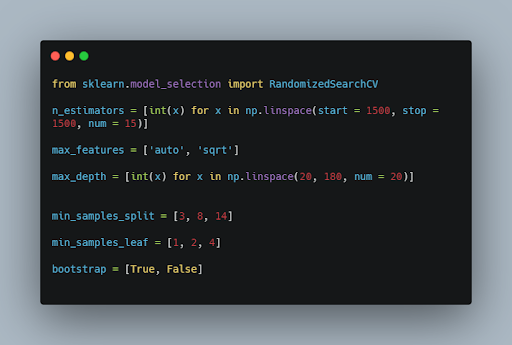
Step 1:- We will import the RandomizedSearchCV model from sklearn library and set all the hyperparameters manually.
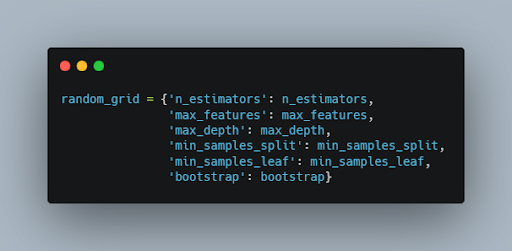
Step 2:- Now we will create a random grid for all the parameters that we set.
Step 3:- Now we will print our random grid.

Step 4:- Let’s see what the output looks like:-
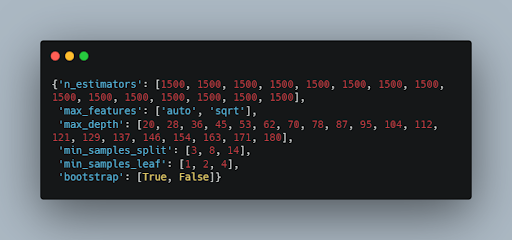
If you follow this method it will give you a random combination for solving our model and the advantage of using this method is we won’t have to try out every combination but just select some random sample values for our model.
So that’s it for the Hyperparameter tuning part, the next step in solving the problem would be to apply this tuning to a Machine Learning model.
Article By: S sanidhya Rajesh Barraptay
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other technical and Non Technical Internship Programs