In our last article, we have learned about how to collect data, organize the data, and process the data set. In this blog, we are going to analyze different aspects of data analysis.
The process which includes inspecting, cleaning, transformations, and modeling data to reach a goal of discovering helpful information, enlightening conclusions, and supporting decision-making statements is called Data Analysis. Data analysis includes multiple facets and approaches, which comprises a variety of techniques under a variety of names, and is used in different business, science, and social science domains. In modern era data analysis plays an important part in making the decision in scientific areas as well as in operating the businesses effectively.
Data Mining
Data Mining uses Data analysis as a specific technique that focuses on mathematical application modeling(Statistics) and knowledge discovery for predictive rather than purely descriptive purposes while business intelligence covers data analysis that relies on aggregation, focusing mainly on business information.
Further in mathematical applications, the Data analysis is often additionally divide up into some varieties are Descriptive Statistics, Exploratory Data Analysis (EDA), and Confirmatory Data Analysis (CDA). Primarily EDA focuses on discovering new features within the data whereas the CDA focuses on confirming or falsifying existing hypotheses.
The analysis which is focus upon the application of statistical models for predictive forecasting or classification is the predictive analysis. Some techniques which are applicable to statistical linguistics and structural techniques to extract and classify information from textual sources are call as Text analytics. The above discussed are varieties of Data analysis.
Data analysis is closely connect to Data Visualization.
The Process of Data Analysis
Data Requirement Gathering
First of all, you have got to accept why one wishes to try to do this data analysis? All you would like to search out is the aim or aim of doing the Analysis. you have got to make your mind up which sort of knowledge analysis you wished to do! during this section.
thus, you have got to make your mind up what to investigate and the way to live it. you have got to know why you’re investigating and what measures you have got to use to try to do this Analysis.
Data Collection
After demand gathering, you may get a transparent plan concerning what belongings you need to live and what ought to be your findings. Currently, it is time to gather your information supported needs. Once you collect your information, keep in mind that the collected information should be processed or organized for Analysis. As you collect information, you need to need to keep a log with a group date and supply.
Data Cleaning
Now no matter what information is collect might not be helpful or extraneous to your aim of the research, therefore it ought to be clean. the information that is collect might contain duplicate records, white areas, or errors. The information ought to be clean and error-free.
so, This section should be complete before Analysis as a result of information improvement. your output of research is going to be nearer to your outcome.
Data Analysis
Once the information is collect, clean, and process, it’s prepare for Analysis. As you manipulate information, you’ll notice you have got the precise data you would like, otherwise you would possibly have to be compel to collect a lot of information. Throughout this section, you’ll be able to use information analysis tools and software systems that are able to assist you to know, interpret and derive conclusions supporting the necessities.
Data Interpretation
After analyzing your information, it’s finally time to interpret your results. you’ll be able to opt for the thanks to specific. however, communicate your information analysis either you’ll be able to use merely in words or even a table or chart. Then use the results of your information analysis method to make your mind about your best course of action.
Data Visualization
Data Visualization is incredibly common in your day to day life; they usually seem within the sort of charts and graphs. In different words, the information shown diagrammatically in order that it’ll be easier for the human brain to know and the method it.
however, information mental image usually accustomed to discover unknown facts and trends. By observant relationships and scrutiny datasets, you’ll be able to notice the simplest way to search out purposeful data.
Trying Some Codes for Understanding
First, we will install some libraries that are pandas, NumPy, seaborn, matplotlib, and Streamlit in our environment. using pip.

After the installation of Libraries, we will create a folder as frontend where we’ll create a streamlit app as GUI. We will perform Data transformation, use the components to display the outputs.
First, we will create a monthly consumption file which will be very useful. For that, we will be using Jupyter notebook, and below is the code.
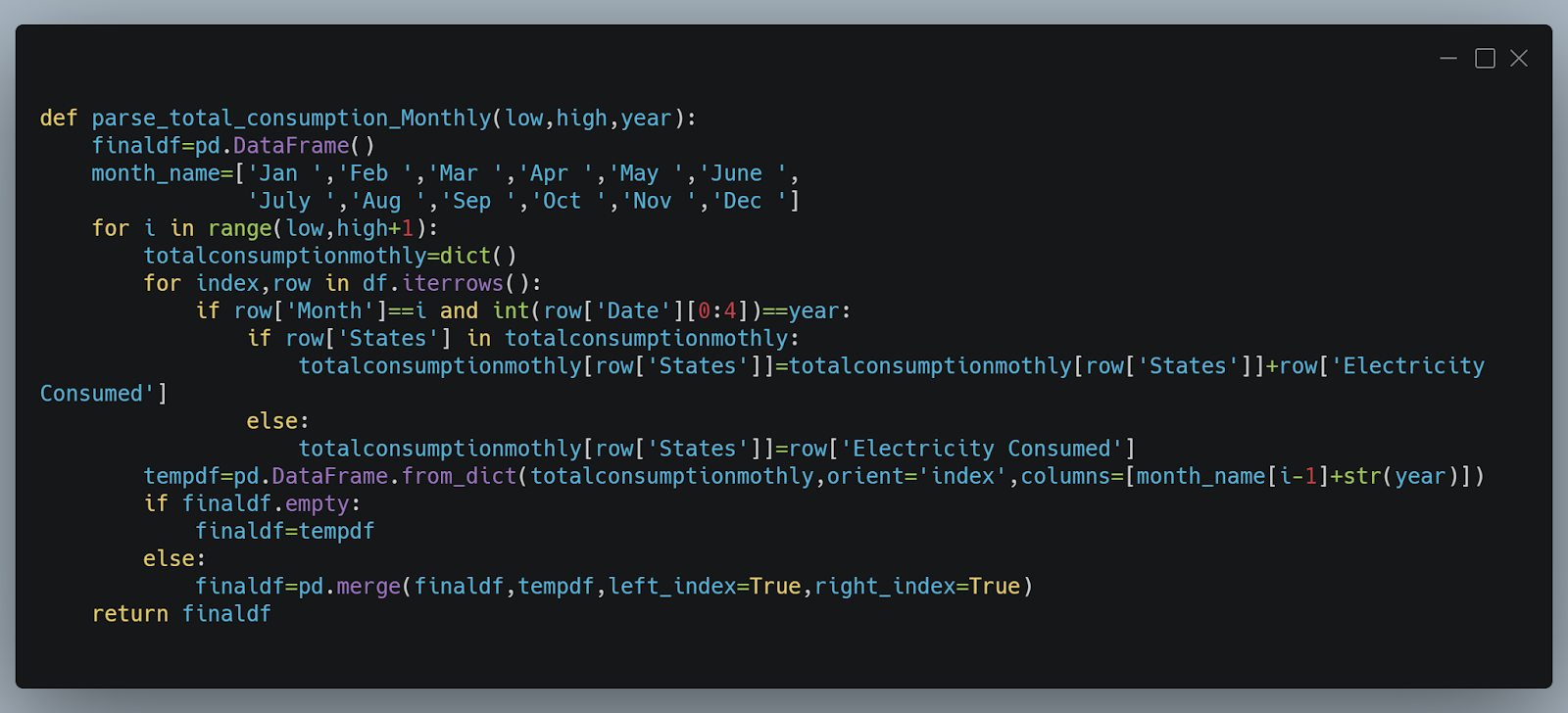
We will create two dataframe one of 2019 and another of 2020 then we will merge them as one using.
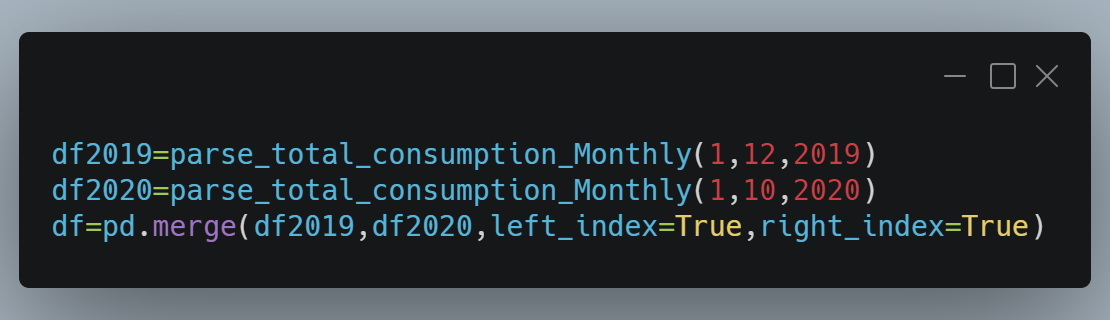
thus, we are going to make a streamlit app with its library and we are going to use CSV files.
Streamlit
Streamlit is an open-source Python library which makes it easy to create and share beautiful, custom web apps for machine learning and data science. hence, Within a few minutes one can build and deploy powerful data apps.
- Version between Python 3.6 – Python 3.8 must be in your system.
- Install Streamlit using PIP.
- Execute the ‘hello world’ app.
- Create a new Python file, import Streamlit library, and write some code.
- Execute the file with below command:
streamlit run [filename].py
so, you have seen some basic time to get a deep dive in it, by learning how Streamlit works and how to build great apps.
Importing the Essential Library
Creating Some Function for Help
We are going to make some cache functions in streamlit. A cache function allows your app to execute quickly between when you load the data from the web, try to manipulate large datasets, or perform expensive computations. To implement the cache, cloak functions with the @st.cache decorator:

Any function with the @st.cache decorator, it notifies Streamlit engine that whenever the function is called it needs to check a few parameters first:
- The input parameters that you called the function with
- thus, The value of any external variable used in the function
- The body of the function
- also, the body of any function used inside the cached function
therefore, If for the first time Streamlit has been executed and seen any of these four parametrics with these exact values and in this exact combination and orientation, it executes the function and stores the result in a local cache memory.
When in the future, the cached function (or same subroutine) is executed, and none of these above components are changed, Streamlit will skip it and will not execute the function altogether and, instead, return the output previously stored in the cache.
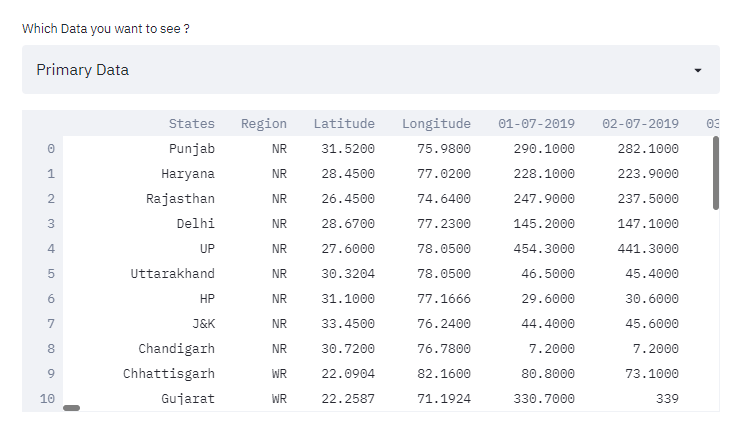
1. Function for reading the Dataframe

In the above function, we are extracting the files and putting them in the select box function of streamlit library. And the output show is below
2. Function For Generating Monthly Comparison using state
The below Function creates a dataframe consisting of state, Electricity of 2019 of a particular month and same as for 2020. We are placing a selectbox function within the month. Then we use the generate function for creating dataframe and states are indexed as an index.
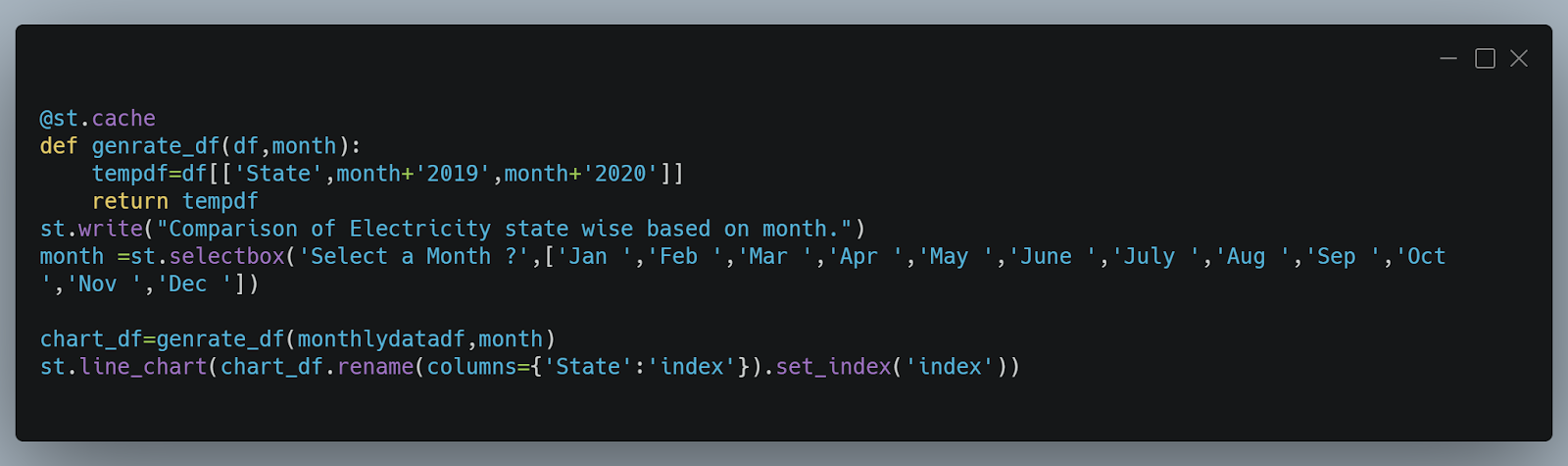
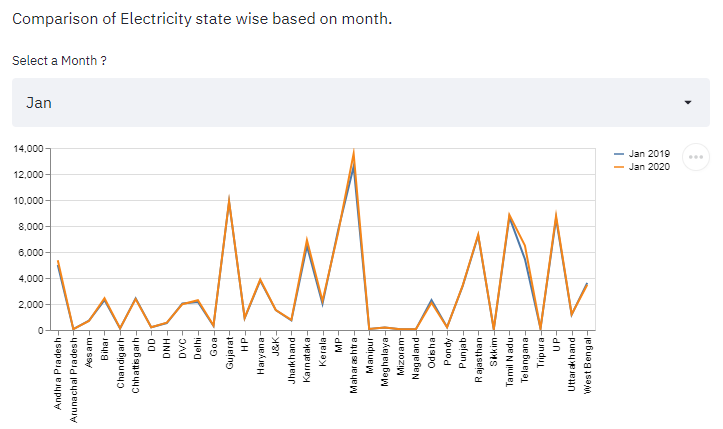
Output
Below is the output for the above code.
3. Yearly Consumption
The Below code forms the summation for the year 2019 and 2020 till October month because we have collected the data till 11th October 2019. so, The code runs in the complexity of O(n).
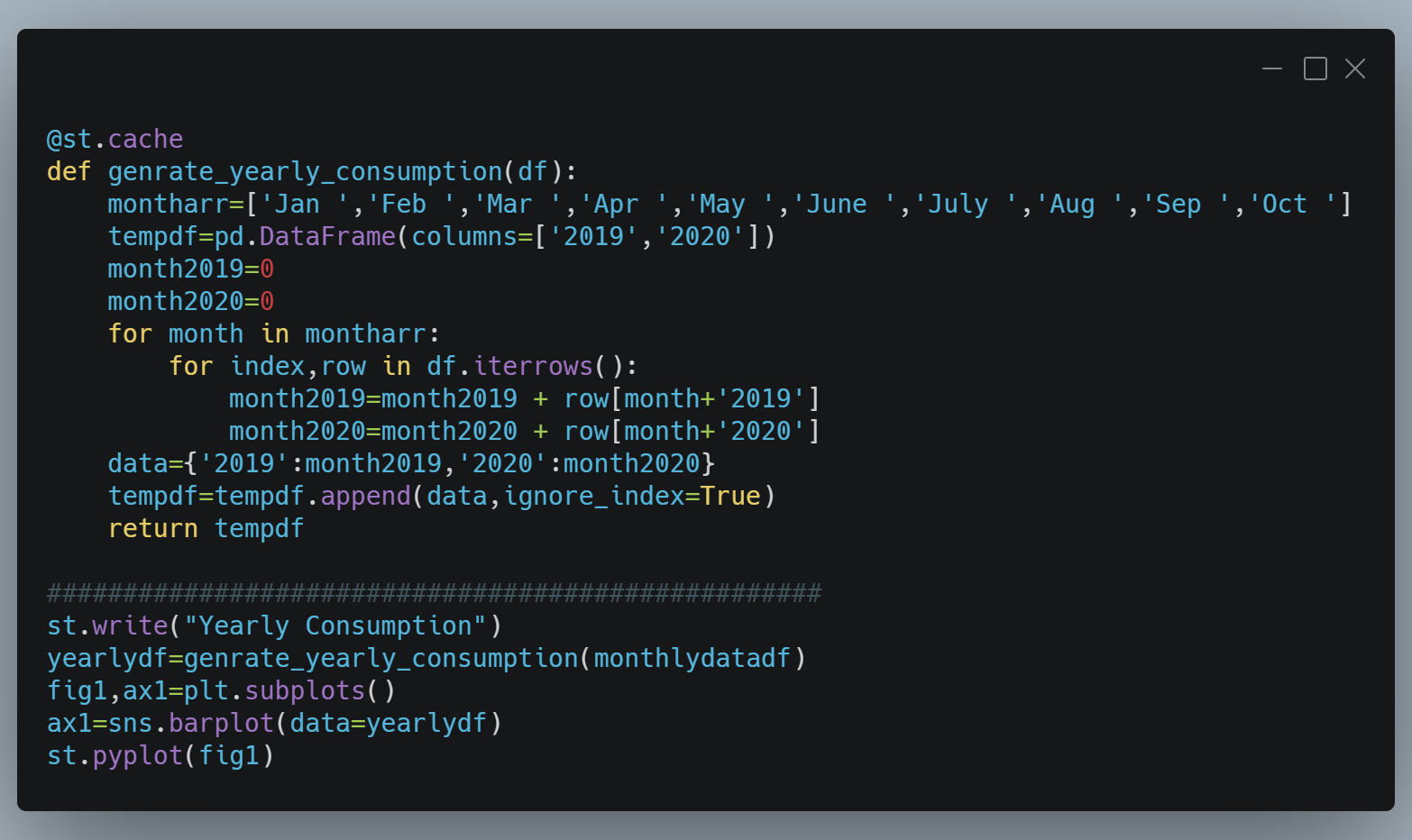
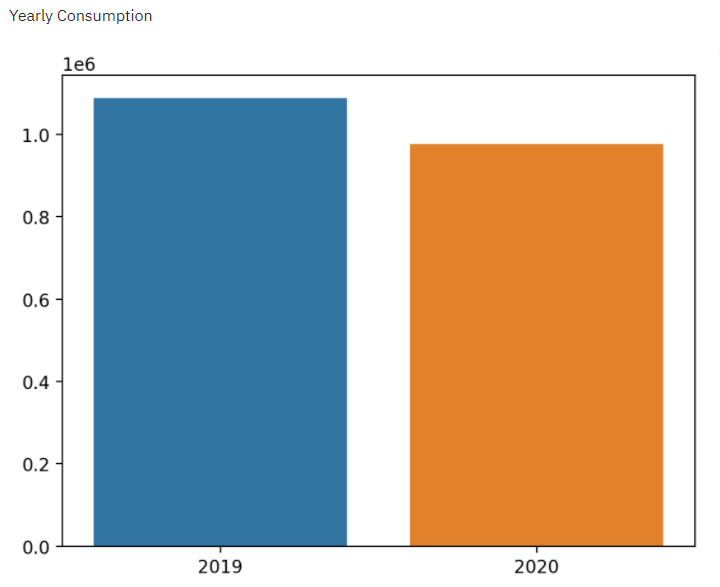
thus, Below is the output for above code.
4. Consumption of Electricity by State in month-wise
The below code is to compare the electricity consumed by each state month-wise and we are comparing it with 2019 vs 2020. After that output has been displayed in the streamlit component. The code runs in the complexity of O(n).


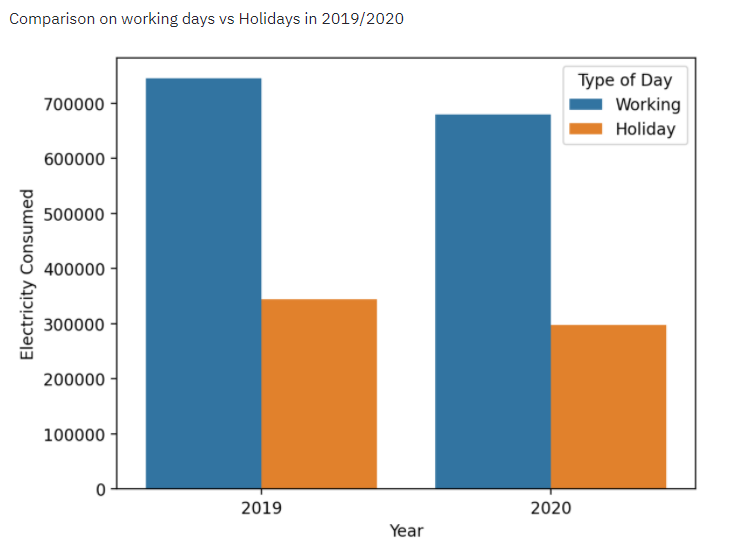
5. Comparison of working days vs Holidays in 2019/2020
The Below Code Compares Working Days and Holidays consumption between 2019 and 2020. The code runs in the complexity of O(n). After that, we have added the output as a streamlit component.

6. Comparison of consumed electricity based on average
The Below code outputs the comparison of average electricity consumed by a state in months separately and the same for that out has been attached. The code runs in the complexity of O(n).

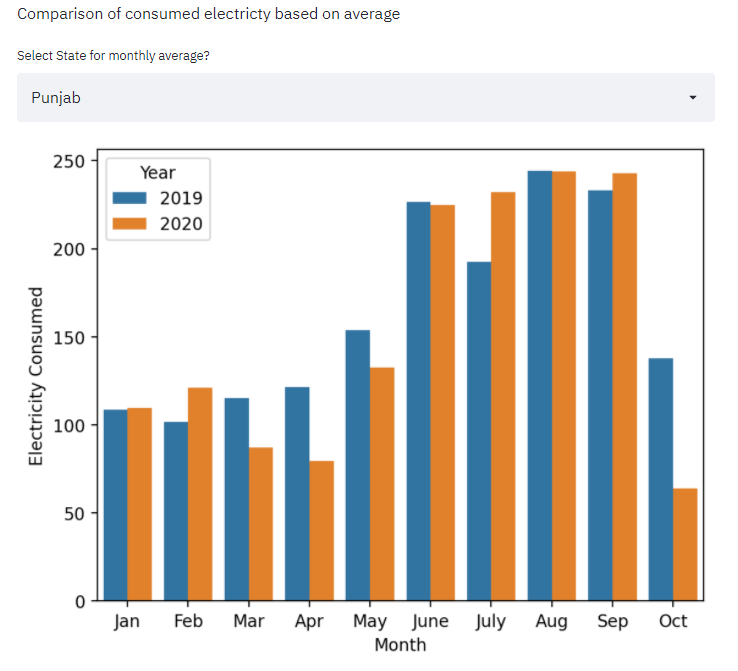
The above data visualization gives us some insights about the dataset using data analysis techniques. Sometimes this technique co-relates with Exploratory Data Analysis.
Note- In the above program the output of October 2020 is low because we have taken the data till 11th October 2020.
written by: Karan Gupta
reviewed by: Kothakota Viswanadh
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs