
In This Article, We Are Going To Look At What Nature Of Dataset We Have Like A Balanced One Or An Imbalanced One.
In the Balanced Dataset the data points are perfectly equal in each class. But for example, you encounter a dataset in which one class is having 10000 data points and the other class is having 100 data points, with this, we encounter a class imbalance problem.
The class imbalance problem is a hot topic that is being investigated recently in machine learning and data mining. It occurs when the data points of one class surpass the instances of another class. The class having more data points is called the majority class while the other is called the minority class. However, in many applications, the class has lower instances and is the more interesting and important one.
thus, The imbalance problem magnifies whenever the class of interest is relatively rare and has a small number of instances compared to the majority class. Moreover, the cost of misclassifying the minority class is very high in comparison with the cost of misclassifying the majority class for example.
The class imbalance is often intrinsic property or because of limitations to get data such as cost, privacy, and large effort.
Some of the domains are mentioned on Nature Of Dataset:-
- Medical Diagnosis
- Fraud Detection(Credit Card, Phone Calls, Insurance)
- Network Intrusion Detection
- Pollution Detection
- Fault Monitoring
- Biomedical
- Bioinformatics
- Remote Sensing (Land Mine/ UnderWater Mine)
The unbalanced distribution of data points ends up in chaos in common classifiers such as Decision trees or neural networks which assume that training classes are perfectly balanced.
Generally in real-world applications, the ratio minor category is incredibly negligible having a ratio (1:100 or 1:1000 or 1:10000). Because of the absence of data, few samples from minor categories in the training set tends the classifier to falsely detect them or outliers in the mathematical model such that the decision boundary is far from the true ones.
There are a few concepts such as overlapping which refers to the level of separability between data classes.
however, In most class imbalance problems the cost of errors for different classes is uneven and usually, it is unknown.
The below article is structured as follows. In Section II, we will briefly see the feature selection methods used. Section III gives an idea of the evaluation metrics used. In Section IV, we will give some hints to various solutions introduced for dealing with the imbalance class’s problem.

Feature Selection in Imbalance Problems
It mainly aims to select important features that help in improving the accuracy and performance of the mathematical model. When the data is imbalanced, the risk of increased misclassification rate goes higher because of the High dimensional data, and irrelevant features may reduce the performance of the mathematical models.
thus, Feature selection metrics will be categorized as:
1. One-sided
2. Two-sided
It is based on what kind of feature they select i.e, only positive features (mostly indicative to the target class) or a combination of both positive and negative features. Also, feature selection metrics will be categorized
1. Binary
2. Continuous
This depends on the data type. Some of the examples are Chi-square, Odds ratio (OR), and Information Gain (IG) can handle both binary and nominal data. Continuous Data can be handled by the Pearson correlation coefficient, Signal to Noise ratio (S2N), and Feature Assessment by Sliding Threshold (FAST).
Evaluation Metrics Used in Imbalanced Classes | Nature Of Dataset
The standard evaluation metrics used are accuracy and error rate however, these metrics are not proper to handle imbalance classes as the overall accuracy will always be biased to the major class regardless of the minor class with lower samples which leads to poor performance on it. For a two-class problem, the concept of a confusion matrix is used.
The most evaluation metrics associated with imbalance classes are
1. Recall (sensitivity)
2. Specificity
3. Precision
4. F-measure
5. Geometric Mean (g-mean)
Sensitivity and specificity are used to monitor the classification performance of each class. While precision is used in problems interested in high performance on only one class, F-measure and G-mean are used when the performance on both classes –majority and minority classes- needs to be high.
Other popular metrics used in imbalance classes are:
1. ROC (Receiver Operating Characteristic) curve
2. AUC (Area Under Curve)
ROC curve is a tool for visualizing and summarizing the performance of a mathematical model based on a trade-off between true positive rate (Y-axis) and false positive rate (X-axis). thus, The area under the ROC Curve is AUC.
There are other cost-sensitive metrics that use the cost misclassifying errors when they are known such as cost matrix and cost curve. A cost matrix is a matrix that identifies the cost of classifying samples where C(i,j) defines the cost of classifying an instance from class i as class j.
Solutions for Dealing with Class Imbalance | Nature Of Dataset
A. Sampling Methods
It is a preprocessing of data which handles the imbalance problem by creating a balanced training data set and by adjusting the prior distribution for minor and major classes. Sampling methods include Mainly:
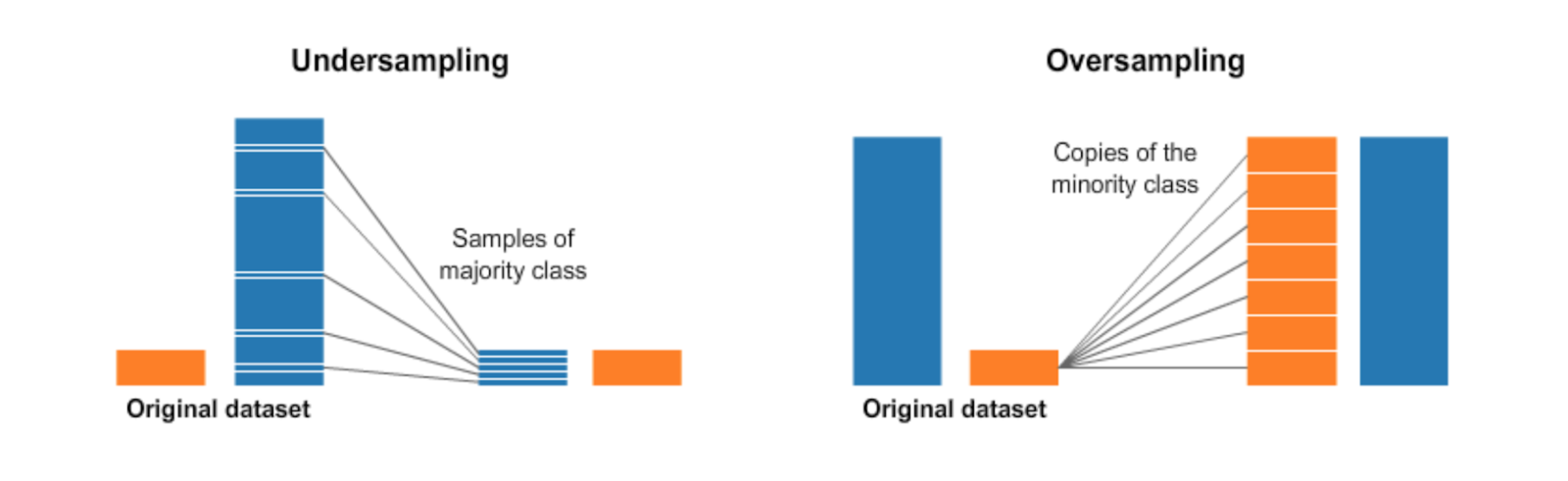
1. Under-sampling
2. Over-sampling
Under-sampling balances the data by removing samples from the major class and over-sampling balances the data by creating copies of the existing samples or adding more samples to the minor class. Significant variances between the majority and minority categories will be handled by oversampling once data is very imbalanced. However, under-sampling may result in loss of useful information by removing significant patterns and over-sampling may result in overfitting and may introduce additional computational tasks.
B. Cost Saving Learning
The cost learning techniques take the misclassification cost in its account by assignment of the higher cost of misclassification to the positive class (minority category) i.e. C(+,-)> C(-,+), and generate the model with the lowest cost.
Another cost-sensitive learning approach used in an unbalanced dataset is adjusting the choice of threshold in the standard ML algorithms, where the choice of threshold is an effective factor on the performance of learning algorithms.
C. Recognition Based Methods
In the recognition-based technique (one-class learning) the mathematical model learns on the simple minority class samples (target class). so, This approach improves the performance of the classifier on unseen data and acknowledges solely those belong to that class.
D. Ensemble-Based Learning
It is a combination of multiple classifiers therefore to improve the generalization ability and increase the prediction accuracy. therefore, Bagging and Boosting are known techniques for Ensemble-Based Learning.
In boosting, each classifier relies on the previous one, and focuses on the previous one’s errors. Examples that are misclassified in previous classifiers are additionally chosen more or weighted additionally heavily. Whereas, in bagging, every model within the ensemble votes has equal weight. In order to improve model variance, bagging trains every model within the ensemble using a randomly drawn set of the training set.
conclusion on Nature Of Dataset
However, there’s no general approach for all imbalance data sets and there is no unification framework. This article shortly discusses Nature Of Dataset & various solutions for managing class imbalance problems.
written by: Karan Gupta
reviewed by: Kothakota Viswanadh
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs