
Dimensionality Reduction
Introduction
Being a Data scientist or enthusiast we will be working with a huge dataset with more than thousand features. How about working with more than 50,000 features?. Have you ever worked on these huge datasets?. I have, working with loads of data with huge features requires more patience and lots of work. Basically when we work with loads of data the advantage is we can analyse data more accurately but in another way it is a challenging task to analyse each and every feature.

In the meantime it is not an easy task to extract insights or to analyse each and every features/variable in every single step. To overcome this, are there any technique/s we can adapt to minimize the time to analyse the features in a quicker manner to deal with the Dimensionality of the data?
Yes, we have the concept called Dimensionality Reduction where we can reduce the dimensionality of the data to perform and make meaningful analysis for better model accuracy.

What is dimensionality reduction?
As I said earlier, in many machine learning problems, the datasets will have a large number of variables/features, which are sometimes more than the observations. In this scenario machine learning algorithms have some difficulty when dealing with large datasets, the only solution for this is to reduce the total number of variables or features before feeding it to the algorithm part.
Dimensionality reduction or dimension reduction is the process of reducing the number of variables which are under consideration by obtaining the smaller set of variables/features.
General Dimensionality reduction techniques
Dimensionality reduction can be done in two different methods/techniques
1. Feature selection
2. Feature Extraction
1.Feature selection: Finding a subset of the original set of variables or features, to get the smaller subset. Later which can be used to model the problem. It usually involves three ways
I. Filter ( IG, Correlation coefficient, chi-square test)
II. Wrapper (Recursive feature elimination, generic algorithm)
III. Embedded (Decision tree)
2.Feature extraction: This reduces the data in a high dimension space to a smaller dimension space. The methods used for feature extraction may be supervised or unsupervised learning depending on whether or not they use the output information.
Let us understand with a simple equation,
W+ X + Y = Z
Consider X + Y = XY
Consider W = 0
Then, total equation gives 0 + XY = Z i,e XY = Z
From the above equation, when we equate x + y = XY , this is feature extraction and considering W = 0 is our feature selection.
Methods of Dimensionality reduction
1.Principal component analysis (PCA) : From the m independent variables of your dataset, PCA extracts p<= m new independent variables that explain the most the variance of the dataset, regardless of the dependent variables
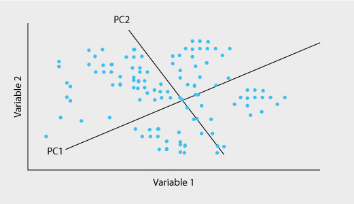
Pic credits: Google
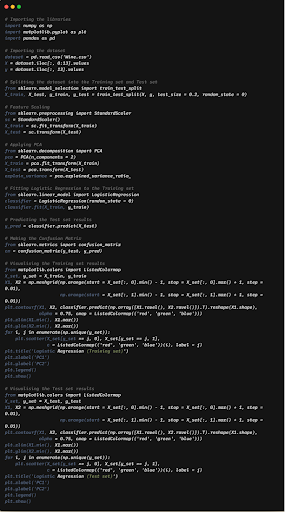
Let’s gets some hands-on by implementing using python
In this implementation we are using wine data to perform PCA
2.Linear discriminant analysis: It is one of the dimensionality reduction techniques which is commonly used for classification problems.
For example, we have two classes and we need to separate them effectively. Classes can have multiple features, using a single feature to classify them may result in some overlapping. So, we will keep on increasing the number of features for effective classification.
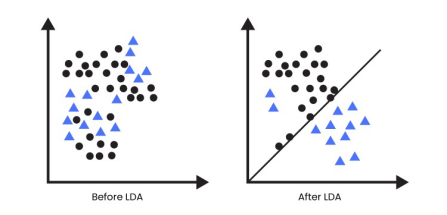
Pic credits: Google
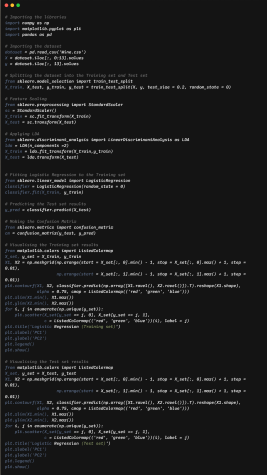
Let’s gets some hands-on by implementing using python
What is the Curse of dimensionality reduction?
When the data dimensionality increases, the volume of the space increases so that the available data become sparse. As a result, to obtain a statistical sound and reliable result, the amount of data needed to support the result often grows exponentially with dimensionality. Due to the curse of dimensionality, all the objects appear to be sparse and dissimilar in many ways, which prevents common data organization strategists from being efficient.
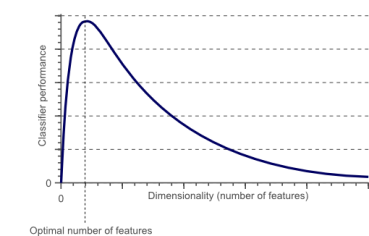
Pic credits: Google
Advantages of dimensionality reduction
Complexity depends on the total number of variables or features. To reduce the memory usage and computational work we have to reduce the dimensionality of the data.
When data can be explained with the fewer features we get the better idea about the process that underlies the data, which allows knowledge extraction.
When an input is decided to be unnecessary, we save the cost of extracting it.
Article By : Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other technical and Non Technical Internship Programs