

Many times while making any decision, you come across some factors which prompt you to take the decision while some points pop up in your mind which tell you not to do so.
As an example, Consider a situation. It’s a beautiful and peaceful weekend and a new concert ground has been opened in your city 30 kms away. Your favourite international artist is coming here. But you are that kind of a person who hates long drives and traffic jams (Ughhhh). Will you go to that concert? Or would you just binge watch your favourite Netflix series considering your hectic routine earlier this week?
You learn from the past experience, generalise the pros and cons, and then apply them to your present life. But you may be surprised to know that there is a special Computational Learning Theory behind this!
This branch of Machine Learning/ statistics, is known as Computational Learning theory and is slightly different from the other theories and algorithms of Machine Learning like Regression, Support Vector Machines etc.
Goal of Computational Learning Theory
The goal of the Computational Learning Theory is to answer the following questions:-
- Understand from the different tasks, what tasks are exactly learnable?
- And in order to learn the different tasks, what type of data is required? How much data is required? Or what is the size of the training set (which by the way in CLT is known as sample complexity).
- Also the resource requirement for an algorithm(Space and Time Complexity), if the task is learnable with the help of the available data.
- Develop the Algorithms and this should meet our predefined criteria. And prove the confidence(how well it will perform on future data).
For attaining this task we will require a setting or a learning model. This is setting is known as PAC Settings
PAC Setting:-
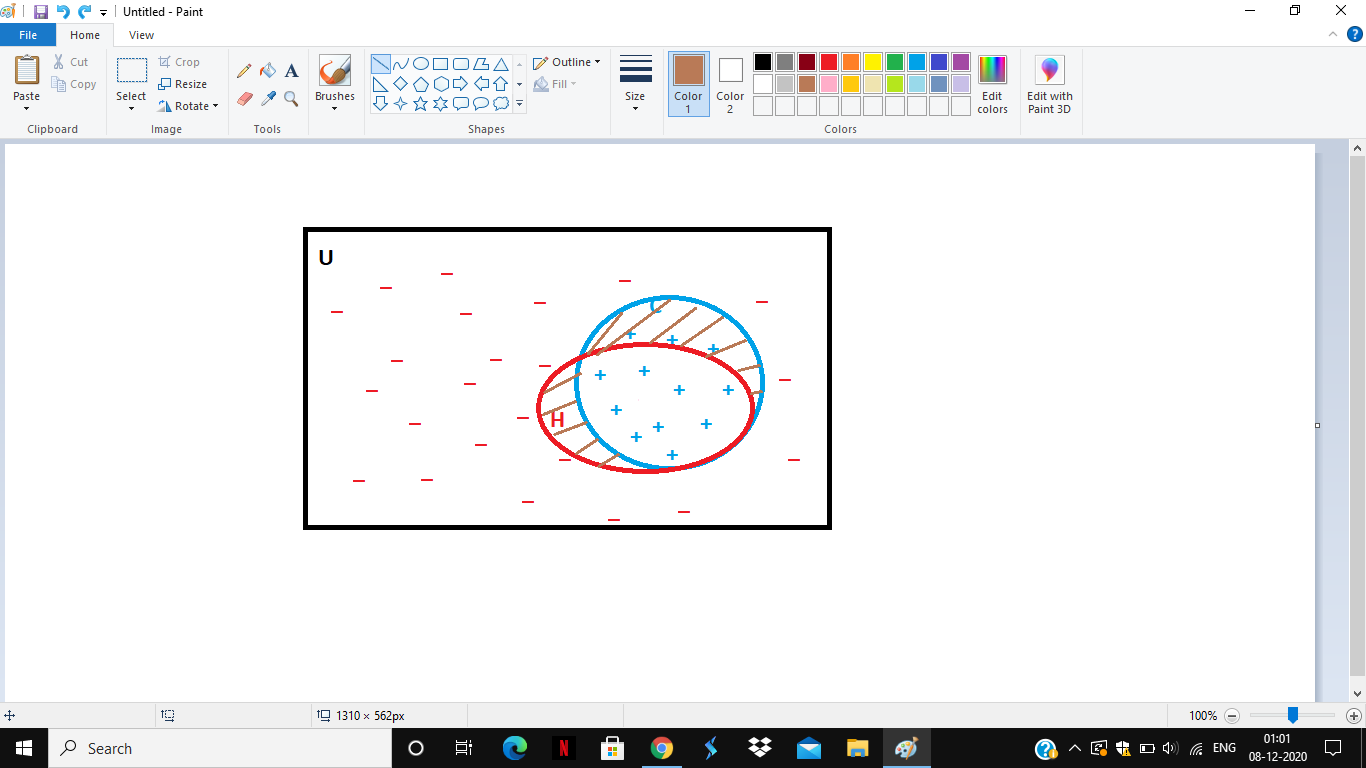
PAC stands for Probably Approximately Correct setting. Consider the following figure where the rectangle means the universe, C is the target function which needs to be learned. The members of the rectangles are the instance space, and the instances which are inside the circle, represent the members of the class. The aim is to learn C. To do so, some training examples are given (+ and -). Also for this, one needs to come up with a hypothesis H (different from C both in size and examples). The error region is given by
CH
The error region is shown with brown lines. The aim is that the probability of this error region to be small.
P(CH)
The value of must be between 0 and ½ . If the error lies between this range, then the hypothesis is Approximately Correct.
There could be certain times where the learning algorithm may not give the correct hypothesis. So to avert this, equation 1 is bound by a confidence parameter . It is given by
Pr (P(CH) )(1-)
Where also lies between 0 and ½.
Prototypical Concept Learning Task
In the concept learning task, there are instances X. If features are real numbers, X can come from Rd and if they are boolean then X=(0,1)d, where d is the dimensions of the instance space or the number of features.
Let D denote distribution over the instance space, C being target function, H the hypothesis space.
The training examples (xi,yi). Since C is the actual concept yi is replaced by C(xi), with xi being identically independently drawn. We have to determine
- A hypothesis h H, such that h (x)=C(x) for all x in S?
- A hypothesis h H, such that h (x)=C(x) for all x in X?
Consistent Hypotheses
The first glance will be on the situation, where, given a training example, the hypothesis which agrees with the training example is found. That is correct labelling is produced for training examples. These are termed as Consistent hypotheses.
The algorithm does optimization over S, and determines h. The ultimate goal is to determine h which has a small error over D.
Will the hypothesis label the instances correctly? We are unable to know this. But how well the hypothesis will generalise, one can estimate. If the hypothesis is correct, all instances must be labelled correctly. In order to do so, one has to have a look at all the instances. There is no shorter way. Thus it is called No free Lunch Model.
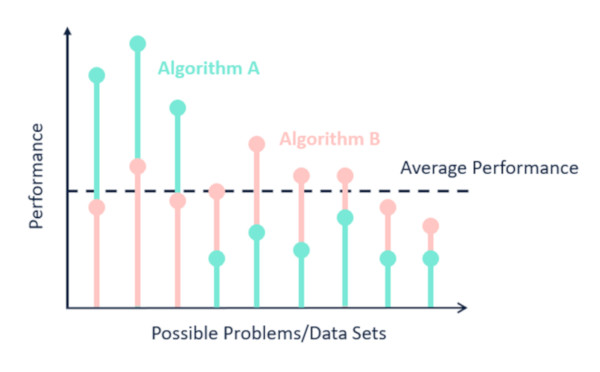
SOURCE: https://www.kdnuggets.com/wp-content/uploads/Firmin-fig1-no-free-lunch.jpg
{kind=link}
In inductive inference, where generalisation has to be made beyond the training example, unless more assumptions are added, it is not possible to do this generalisation. An example could be priors over H. In such cases, a bias is must.
The error of h on S can be measured. But the point of consideration is the true error of h .It can be however defined as
errorD(h)=Pr[C(x)h(x)] xD
The above equation can never be determined only the sample error whose values are labelled. For h to be close to C, that is
P(CH)
errorD(h)
How frequently C*(x)h(x) differ over instances of the future drawn from D?
To do so training error is used which is given by (as true error cannot be determined)
errorS(h)=1miI(C*(x)h(xi)
For computing the sample Complexity, the errorD(h)in terms of errorS(h)needs to be bounded. To address this, PAC learning is brought into picture.
PAC learning focuses on efficient learning. It can be proved that,
If the probability is high, then an (efficient) Learning Algorithm will find a hypothesis, that is approximately identical to the hidden target concept.
Here efficient algorithm means that algorithm, whose running time and space requirement is polynomial in certain parameters. Two parameters will be specified, and and require that with the probability at least (1-) a system learn a concept with error at most .
Space Complexity Theorem for Supervised Learning
This theorem states that,
If the size of the training sample m, is greater than equal to logarithm of the size of the hypothesis in addition to the logarithm of reciprocal of confidence parameter divided by the error parameter, then if there are that many number of training example, it is appropriate to PAC learn the hypothesis.
Mathematically
m1[ln(| H |) + ln (1)]
If a learner determines the hypothesis which is consistent with m training examples and outputs a consistent hypothesis, the other way to look is the Statistical Learning Way.
With the probability atleast (1-), all h Hsuch that errS(h)=0then the true error of the hypothesis can be bounded. This is given as
errD(h)1m[ln(| H |) + ln (1)]
There are situations where one cannot get a hypothesis, but the hypothesis one outputs is inconsistent, that is it has error on the training set. In order to handle that the notion of finite Hypothesis space is used. From that the derivation is bound for the number of samples needed. This is given by
m122[ln(| H |) + ln (1)]
Generally this notion of complexity is criticised that it does not represent the practical learning problem( like the dilemma of going to the concert!!!!). But nonetheless there is a lot of room for debate.
Written By: Aryaman Dubey
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs