

Image Source: www.trainingjournal.com
In the real world, nothing is 100 percent perfect. So, the case in the data world. A perfect and balanced dataset is nearly impossible to find. Balance dataset in the sense 50 percent of one type and 50 percent of other types. What we find is an imbalance dataset.
But now one may be thinking what is the problem with imbalanced datasets. Even if there is a problem with imbalanced datasets, what is the solution for the problem?
Here in this article, I will be discussing Imbalance datasets, complications associated with that, different resampling techniques to deal with imbalanced datasets, advantages, and disadvantages of each of the resampling techniques.
What is an imbalanced dataset?
The classification problem in which the output classes are not equally distributes is refer to an imbalanced dataset. The proportion of one class will be much higher than the other class. The class having a high proportion is refer as the majority class and the class with a low proportion is refer as the minority class.
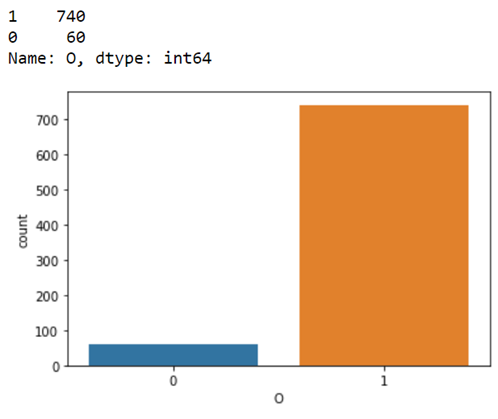
For example, we have a dataset with “v1”, “v2”, “v3”, and “v4” as input variables and output variables as “O”. The “O” variable has two categories of 0 and 1. If we consider the dataset as imbalance then, the distribution of categories of the output variables is show in the figure below.
Total no. of observations = 800
No. of “0” = 60
No. of “1” = 740
Problems with Imbalanced Dataset
The model built on an imbalanced dataset faces an accuracy crisis as it is bias towards the majority class. It fails to measure accuracy correctly. It will only be able to predict the majority class and fails to measure the minority class. If any new dataset is having only a majority class, the model will predict with 100 % accuracy but if the new dataset is having only a minority class, the model will predict with 0 % accuracy.
So, it is consider that in the case of imbalanced datasets accuracy is not an appropriate parameter to measure model performance. There are some other evaluation measures like precision, recall, F1 score, etc. that can help evaluate model performance instead of accuracy score in case of an imbalanced dataset.
The following are a few of the domains where imbalances classes can be observed
- Disease Screening
- Spam Filtering
- Fraud Detection
- Identification of customer churn rate
- Electricity theft and pilferage
There are several techniques to deal with an imbalanced dataset. This process of handling imbalance in the dataset is refer the resampling technique. The main focus of this technique is to obtain the same number of occurrences for both the majority class and minority class.
I will be discussing here two of the resampling techniques along with advantages and disadvantages.
1. Under Sampling
The process of reducing the majority class by randomly eliminating instances from majority class is called under-sampling. This process is done still the minority and majority class approximately becomes equal in numbers.
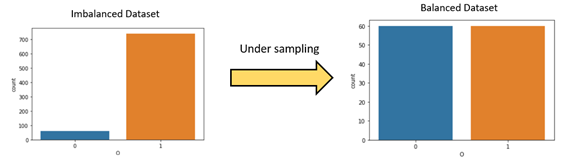
The above figure represents the under-sampling technique. Initially, the imbalanced dataset is having 60 instances of minority class “0” and 740 instances of majority class “1”. After applying the under-sampling technique, the minority class instances remain 60 but the majority class instances reduce to 60 instances.
Advantages:
- This can be helpful when the training data set is large, and runtime problems can be
- improved by reducing the number of training data samples.
Disadvantages:
- Reducing majority class data can eliminate useful information and thus encounter the problem of underfitting.
2. Oversampling/ UpSampling
The process of increasing minority by randomly replicating instances from minority class is called oversampling. This process is done still the minority and majority class approximately becomes equal in numbers.

The above figure represents the over-sampling technique. Initially, the imbalanced dataset is having 60 instances of minority class “0” and 740 instances of majority class “1”. After applying the oversampling technique, the minority class increases to 740 which is equal to the majority class instances.
Advantages:
- Three is no information loss as faced during undersampling.
Disadvantages:
- Since minority class is replicated, the model probably faces the risk of overfitting.
Conclusions
Here I have discussed only two resampling techniques. Besides this, there are other synthetic techniques like SMOTE, MSMOTE algorithms outperform the oversampling and undersampling method.
Written By: Nabanita Paul
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs