
Introduction: Bootstrapping And Bagging
When using ensemble templates, bootstrapping and bagging can be very helpful. Bootstrapping is in effect, random sampling with the substitution of the training data available. For each bootstrapped dataset, Bagging (= bootstrap aggregation) executes it several times and trains an estimator.
(https://hackernoon.com/hn-images/0*jW2hAGmYEFH0RP9W.)
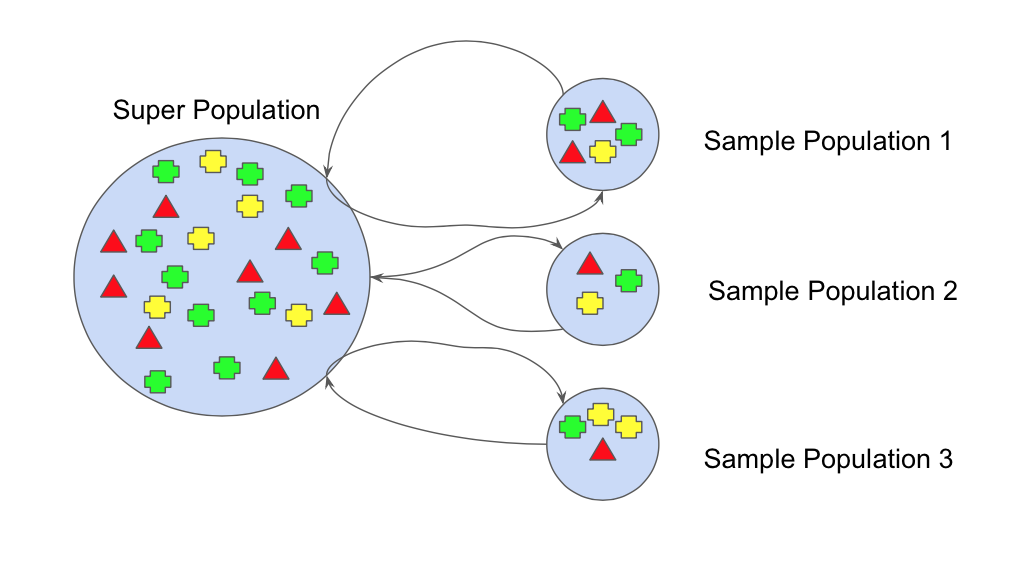
In the diagram above, there is a dataset of many elements (as we can see in the figure above). We need to draw three sample populations of the same size in order to start. Let’s randomly draw the sample population 1 and assume that the green element turns out to be the first element. Until we draw the second element of sample population 1.
however, the green element choose earlier is return to the dataset. For the whole draw, a related procedure takes place. This is refer Sampling by Replacement. Therefore in a collection, we have a probability of choosing the same object many times. We have drawn three sample populations, that is, sample population 1, sample population 2, and sample population 3, by following this method.
We find a mean or an average of all statistics to infer something about the dataset as we take a step further down, which defines the statistics (various metrics) on Sample 1, Sample 2 and Sample 3 (population). This entire process is refer bootstrapping and the drawn samples are term bootstrap samples. This can be define with the following equation:
Inference about the Dataset(Population) = Average(sample 1,sample 2,…………,sample N)
This concept is refer bagging (short for bootstrap aggregation) when sampling is carry out with replacement.
Bagging
Bagging is compose of two parts: bootstrapping and aggregation. Bootstrapping is a method of sampling where, using the replacement method, a sample is select out of a collection. Then the learning algorithm is carry on several samples.
Bagging is a means of reducing the error of variation originating from a formula. Often the poor learning algorithms are very sensitive; a subtly different input leads to very offbeat outputs. Random forests minimize this variability by running many examples, resulting in lower variance. In order to prepare random samples from training datasets, this approach utilizes a random sample with replacement models (bootstrapping process).
To make the collection process absolutely random, the bootstrapping strategy employs sampling with replacements. The subsequent choices of variables are often based on the previous selections when a sample is chosen without replacement, thereby rendering the criterion non-random.
Models are built for each specimen using supervised learning methods. Finally, by combining the predictions or picking the best forecast using the majority voting process, the outputs are combine. Majority voting is a system in which the estimate of the ensemble is the class with the largest number of predictions in all the classifiers. There are also several other processes, such as weighing and rank averaging, for obtaining the final data.
Aggregation
In order to take into account all the future effects, model predictions undergo aggregation to integrate them for the final forecast. Based on the total number of effects or on the likelihood of projections obtained from the bootstrapping of and model in the process, the aggregation can be performed.
Ensemble Method
In the Ensemble method, we group multiple models together. method. Ensemble methods are consider as the best model approach for better performance and accuracy of actual outputs.
Stages of Bagging
- Bootstrapping: This is a mathematical method used to produce random samples or bootstrap samples with replacement.
- Model fitting: We create models on bootstrap samples at this point. Usually, to construct the models, the same algorithm is use. Nevertheless, there is no limitation on using multiple algorithms.
- Combining models: This step entails all models being mixed and an average is taken. For eg, if a decision tree classifier has been implemented, then the probability that comes out of each classifier is averaged.
Out Of Bag Error
In the diagram discussed above, there may be a case in which a few components of the dataset have not been chosen or are not part of the three samples. These non-sampled training instances are refer out-of-bag (OOB) instances. OOB instances are not used in the training set. By averaging each predictor’s OOB evaluations, the ensemble method can be analyzed.
OOB = Dataset – Boot_Sample
Set oob_score=True, when creating a Bagging Classifier to request an automatic OOB evaluation after training
Pros and Cons of Bagging.
Pros:
- When we face variation or overfitting in the model, the bagging process supports. This creates an atmosphere by the use of N learners of the same size on the same algorithm to deal with variance.
- During the sampling of train data, there are many observations which overlap. So, the combination of these learners helps in overcoming the high variance.
- Bagging uses the Bootstrap sampling method.
Cons:
- In the case of bias or underfitting in the data, bagging is not helpful.
- Bagging ignores the value, which may provide a large difference and have an average outcome for the highest and lowest result.
Written By: Chaitanya Virmani
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs