
Introduction to Gradient Boosting
In general, decision trees are known as an ensemble of weak learners. Gradient boosting is a machine learning strategy in which weak learners iteratively work against error discoveries that were impossible to anticipate in previous iterations and build an ensemble of weak learners.
It builds the model in a stage-wise manner as other boosting methods do, but it generalizes them by allowing optimization of an arbitrary differentiable loss function.
Gradient Boosting operates by adding predictors to an ensemble sequentially, each one correcting its predecessor. This approach attempts to match the residual errors made by the previous predictor with the current predictor. Gradient Boosting also performs well for regression tasks, called Gradient Tree Boosting or Gradient Enhanced Regression Trees (GBRT).
Gradient Boosting being a greedy algorithm can easily overfit a dataset. In such cases, regularization can be use that penalize different parts of the algorithm and typically increase algorithm efficiency by reducing overfitting.
Gradient boosting trains models in a sequential manner, and involves the following steps:
- Fitting a model to the data
- Fitting a model to the residuals
- Creating a new model
If a slight change in a case’s prediction produces a significant decrease in error, so a high value is the next target outcome of the case. The error is minimize by predictions from the current model that are close to its targets.
If no change in error is cause by a small change in the prediction for a case, then the next target outcome of the case is zero. Changing this prediction doesn’t reduce the error.
The name gradient boost occurs because the target results are mark upon the gradient of the error with respect to the prediction for each case. Each new model takes a step in the direction that minimizes prediction error, for each training case in the space of possible predictions.
Ensemble Method
In the Ensemble method, we group multiple models together. method. Ensemble methods are consider as the best model approach for better performance and accuracy of actual outputs.
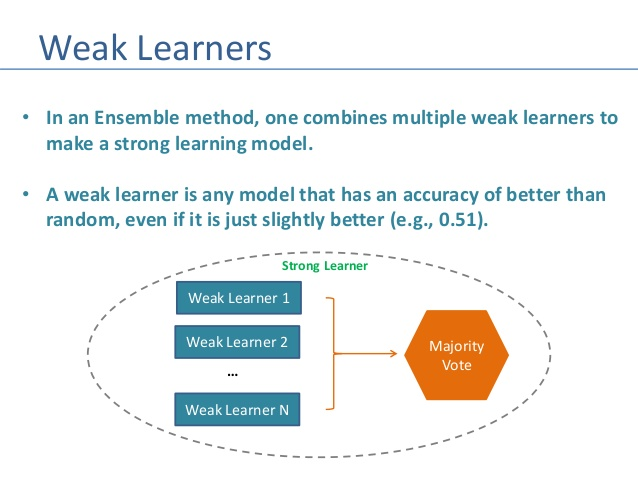
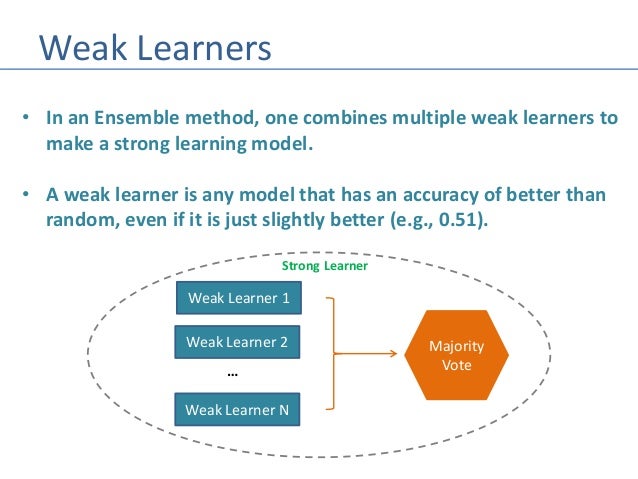
Weak Learners
Until applying gradient boosting, there are a few significant parameters to consider:
- Min_samples_split: min_samples_split is the minimum number of samples require in a node to be consider for splitting.
- Min_samples_leaf: min_samples_leaf is consider as the minimum number of samples required at the terminal or leaf node.
- Max_depth: This is the maximum number of permitted nodes from the root to the tree’s farthest leaf. Deeper trees can however make model more complicated relationships that cause the model to overfit.
- Max_leaf_nodes: The maximum number of nodes at the leaves in a tree. Since binary trees are created, a depth of n would produce a maximum of 2n leaves. Hence, either max_ depth or max_leaf_nodes can be defined.
{kind=link}
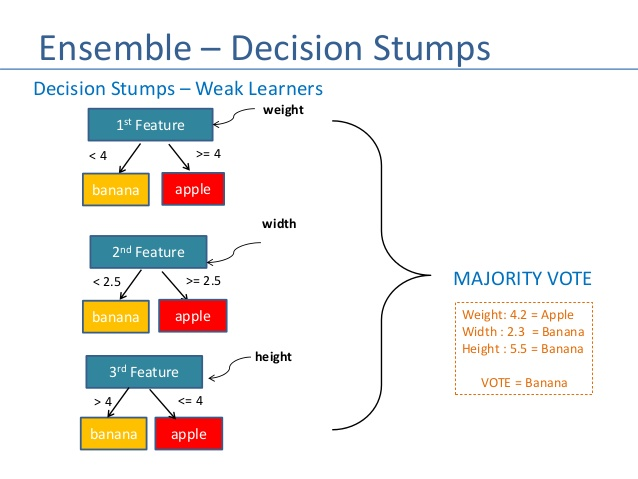
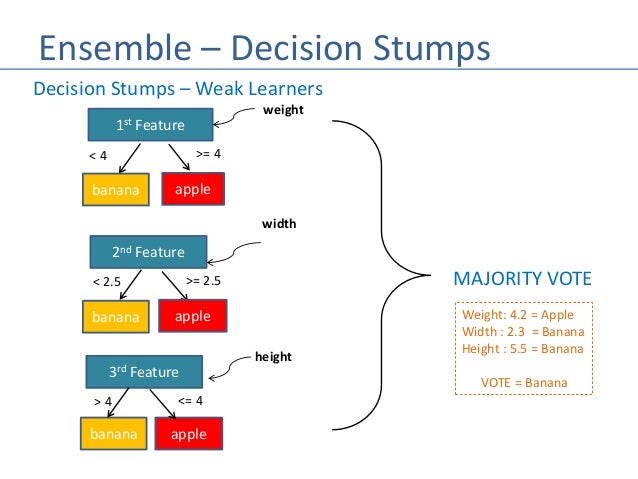
The ensemble consists of very simple base classifiers in boosting, these are often refer to as weak learners, that have only a slight performance advantage over random guessing.
The tree stump in decision making is a typical example of a weak learner. The central idea behind boosting is to concentrate on hard-to-classify training samples, that is, to allow weak learners to benefit from misclassified training samples to enhance the efficiency of the ensemble.
The ultimate aim of Ensemble Approaches is to put together weak learners to create a sophisticated yet more precise model.
Gradient boosting involves three elements:
Optimizing Loss function:
Depending on the problem being solve, the loss function varies. For both regression problems, the mean square error is use as the loss function. Where Log Loss is in use in the event of problems of classification. Instead of beginning from initial iterations, unexplain loss from previous iterations is optimize at each level of boosting.
Predictions are made by weak learners:
In gradient boosting, decision trees are use as a weak learner.
Models adds to increase the number of weak learners that can minimize the loss function:
trees are added one at a time and current trees does not modifies in the model. To minimize the loss when adding trees, the gradient descent technique is use.
{kind=link}
XGBoost
XGBoost is extreme Gradient Boosting. It follows the principle of Gradient Boosting. In this, we use a more regularized model formalization to control overfitting, which gives it better performance. Improved convergence techniques are utilize. Most importantly, the memory error is somewhat resolved in XGBoost. The goal of the XGBoost library is to compute to extreme conditions such that high scalability, portability and accuracy in outputs of the model can be achieved.
AdaBoost
In addressing procedures, AdaBoost is one of the first boosting algorithms to be adapt. Adaboost allows several “weak classifiers” to be merges into a single “strong classifier.” AdaBoost functions by adding more weight on cases that are difficult to identify and fewer on those that have already been handled well. It can be used for both classification and regression problems.
Written By: Chaitanya Virmani
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs