
Recommender Systems became boon to this earth as well as the most powerful tool for many companies and MNCs. According to the recent research study that happened across many silicon valleys regarding a query “What is your favourite algorithm in Machine Learning?! ”. While among all, many had answered “Recommender Systems” in a quite huge ratio 😉

E-commerce and retail companies are leveraging the power of data and boosting sales by implementing recommender systems on their websites. The use cases of these systems have been steadily increasing within the last years and this is the great time to dive deeper into the “World’s Famous Machine Learning Algorithm”
What exactly are Recommender Systems ?
Recommender systems aim to predict user’s interests and suggest product things that quite seemingly square measure fascinating for them. they’re among the foremost powerful machine learning systems that on-line retailers implement so as to extend the sales within the market.
Recommender systems square measure utilize in a very kind of square measures and are most typically recognize as playlist generators for video and music services like Netflix, YouTube and Spotify, product recommenders for services like Amazon, or content recommenders for
social media platforms like Facebook and Twitter.
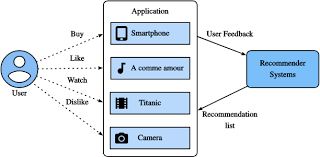

Recommender systems sometimes create use of either or each cooperative filtering and content-based filtering as well as different systems like knowledge-based systems. Collaborative filtering approaches build a model from a user’s past behavior.
furthermore as similar choices created by different users. This model is then accustomed to predict things (or ratings for items) that the user could have an Associate in Nursing interest in. Content-based filtering approaches utilize a series of separate, pre-tagged characteristics of Associate in Nursing items so as to suggest extra things with similar properties.


How does a recommender system work?
Recommender systems perform with 2 styles of information: Characteristic data. this can be data regarding things (keywords, categories, etc.) and users (preferences, profiles, etc.). This can be data like ratings, range of purchases, likes, etc. Collaborative filtering systems, that are supported by user-item interactions. we have a tendency to don’t look to predict the values of a singular column, however rather predict the worth as shown below:

Next, we’ll dig a bit deeper into content-based and cooperative filtering systems and see however they’re completely different. Content-based systems These systems build recommendations employing a user’s item and profile options.
we have a tendency to simply ought to make sure that we have a tendency to assign them a gaggle in keeping with their options. Collaborative filtering systems Collaborative filtering is presently one of all the foremost oft used approaches and typically provides higher results than content-based recommendations. Some samples of this are found within the recommendation systems of Youtube, Netflix, and Spotify.
whereas in these cases we have a tendency to aim to predict a variable that directly depends on different variables (features), in cooperative filtering, there’s no such distinction between feature variables and sophistication variables. Visualizing the matter as a matrix.
Problem Formulation:
Recommender systems are currently a very popular application of machine learning.
Say we are trying to recommend movies to customers. We can use the following definitions
- n_u = number of users
- n_m =number of movies
- r(i,j) = 1 if user j has rated movie i
- y(i,j)= rating given by user j to movie i (defined only if r(i,j)=1)
We can introduce 2 options, x1 and x2 that represent what proportion romance or what proportion action a pic might have (on a scale of 0−1).
One approach is that we tend to do statistical regression for every single user. For every user j, learn a parameter. Predict user j as rating user i with x(i)(θ(j))T stars.

- θ(j)= parameter vector for user j
- x(i)= feature vector for movie i
- m(j)= number of movies rated by user j
For user j, movie i, predicted rating: x(i)(θ(j))T
To learn θ(j), we should do the following:
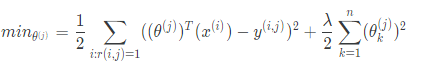
To get the parameters for all our users, we do the following:
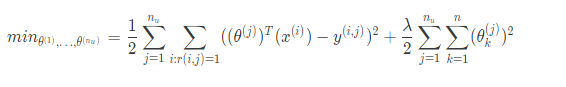
Collaborative Filtering Algorithm:
It will be a terrible tough to seek out options like “amount of romance” or “amount of action” during a movie. to work this out, we are able to use feature finders. We can let the users tell us what proportion they just like the completely different genres, providing their parameter vector directly for users and in order to prevent the model from overfitting we can also use the squared error function with regularization over all the users.
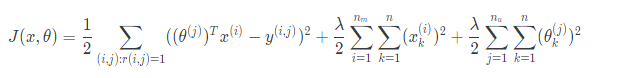
It seems to be very complicated, but we’ve only combined the cost function for theta and the cost function for x.
Because the algorithm can learn them itself, the bias units where x0=1 have been removed
Low Rank Matrix Factorization:
Given matrices X (each row containing options of a specific movie) and Θ (each row containing the weights for those options for a given user), then the total matrix Y of all foreseen ratings of all movies by all users is given merely by: Y= θTX
Predicting how similar two movies i and j can be done merely using the norm distance between the 2 specific movies i and j and we are also striving for the minimum loss i.e we are looking for a least assess of || X(i) – X(j) || over all the Users and Movies.
Summary and Farewell:
As we saw in this blog, It’s better to have a basic recommender system for a small set of users and invest in more powerful techniques once the user base grows.
Business goals can dictate the kind of recommender system you must specialize in at first: whether or not it’s generating a lot of engagement for already active users, or pushing those infrequent customers to become a lot more active.
Besides processing the business goal, it’s key that you’re able to analyze and perceive the knowledge generated from your web site. Given that, there’s nothing that ought to stop you from a productive implementation of your recommender system.
written by: Naveen Reddy
reviewed by: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs