
Model Selection In Machine Learning is best suited for our dataset is the most crucial thing. So, let’s understand what should be the approach while selecting a model to get the highest accuracy results.
The first and the most important thing to do is Observing the dataset, analyzing the type of output.
Important algorithms in the flow chart | Model Selection In Machine Learning

Firstly, we have to identify whether the dataset belongs to Supervised ML or Unsupervised ML.
- Supervised ML -> Labeled data
- Unsupervised ML -> Unlabeled data
Secondly, we have to check whether the dataset belongs to Supervised ML then identify whether it belongs to Regression or Classification
- Regression -> Continuous Target variable
- Classification -> Categorical Target variable
For a dataset belonging to Regression (Supervised ML), let’s consider an example of one dataset.

In the above dataset,
AT, V, AP, RH -> Independent variable
PE -> Dependent variable
So, from the dataset itself, we get to know that we have to apply Regression.
But now the question is: Which algorithm should be applied?
Let’s apply the most frequently used algorithm on our dataset.
Firstly, I applied Multiple Linear Regression
SUPERVISED MACHINE LEARNING – REGRESSION
MULTIPLE LINEAR REGRESSION

Till here we’ve predicted the results.
Now, the question arises, that there should be a parameter to compare the current result with some other algorithm.
The answer to this question is yes, we do have one method which is known as r2_score function that allows you to evaluate the model performance of your regression model with R^2 coefficient determination.
r2_score(real result, predicted result)
You will find it’s documentation at the following link: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.r2_score.html#sklearn.metrics.r2_score
So, for Multiple Regression evaluation of the model is:

In Multiple Regression, the r^2 coefficient value is 0.932.
Let’s dig up some other algorithms:
POLYNOMIAL REGRESSION

Let’s look at the evaluation parameter now.

In Polynomial Regression the r^2 coefficient value is 0.945, here the r^2 coefficient value is better than the multiple regression.
Remember better the r^2 coefficients, the better is the performance of the model.
SUPPORT VECTOR REGRESSION

Let’s look at the evaluation parameter now.

In Support Vector Regression, the r^2 coefficient value is 0.948, which is better than polynomial regression but the difference hardly makes any difference.
DECISION TREE
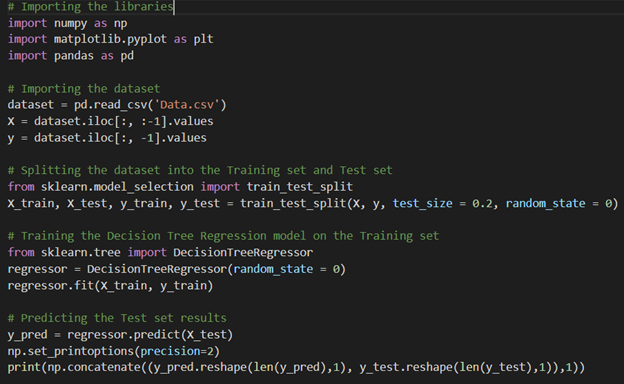
Let’s look at the evaluation parameter now.

In the Decision Tree, the r^2 coefficient value is 0.922, which is worse of all.
RANDOM FOREST
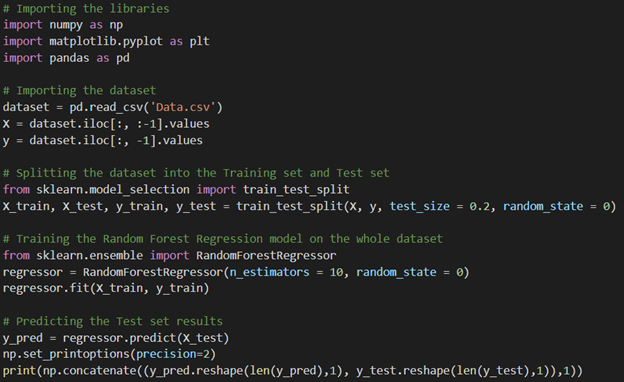
Let’s look at the evaluation parameter now.

In Random Forest, the r^2 coefficient value is 0.961, which is the best of all. So, here we are to the concluding state. The best Model for our dataset is Random forest as it’s giving the best prediction result.
In regression, we can check the performance of the model with the help of the r2_score function and then select the best fit model.
SUPERVISED MACHINE LEARNING – CLASSIFICATION
Now, let’s look at the dataset which belongs to Classification:
The dataset contains different parameters for breast cancer. In class column 2 means malignant cancer and 4 means benign cancer.

Above, I have displayed a few columns of the dataset, so that you will get an idea about the features in the dataset.
LOGISTIC REGRESSION

As, we had an r2_score function for evaluating the performance of a model in Regression, likewise for Classification we have an accuracy_score function for evaluating the performance of the model.
You will find it’s documentation at the following link: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score
Let’s look at the evaluation parameter.
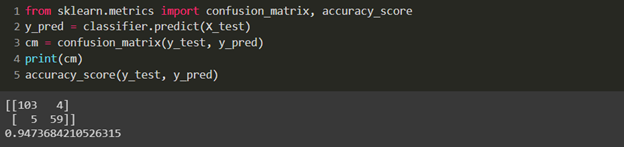
Here, we get an accuracy score of 0.947, which is a pretty good accuracy.
K-NEAREST NEIGHBOR

Let’s look at the evaluation parameter.
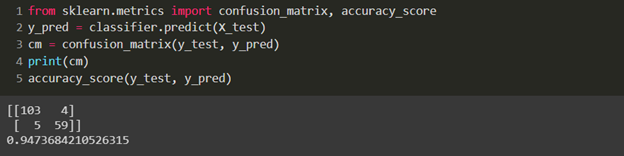
Here, we get an accuracy score of 0.947. We rarely get the same accuracy for 2 algorithms. So, K-nearest neighbor and Logistic regression are giving us the same accuracy score.
SUPPORT VECTOR MACHINE
Let’s look at the evaluation parameter.
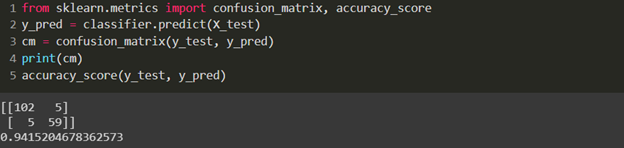
Here, we get an accuracy score of 0.941, which is lower than the above algorithms.
KERNEL-SVM
Let’s look at the evaluation parameter.
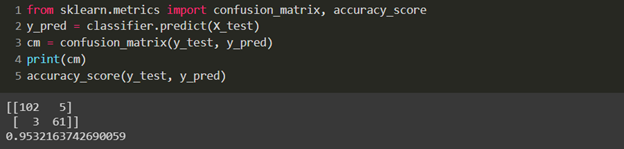
Here, we get an accuracy score of 0.953, which is the best accuracy reached till now. The point to note is: Kernel-SVM performed better than SVM in this Model.
NAIVE BAYES

Let’s look at the evaluation parameter.
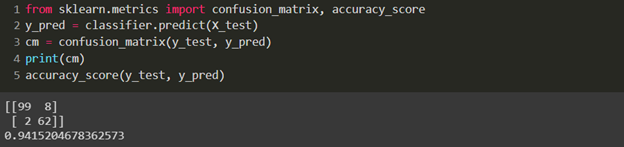
Here, in Naïve Bayes, we get an accuracy score of 0.941, which is okay, but not good.
RANDOM FOREST
Let’s look at the evaluation parameter.

Here, we get an accuracy score of 0.935, which is the worst accuracy scores we have received till now. Generally, the random forest gives good accuracy, that’s why we can’t judge that a particular algorithm will give good results; we have to compare it with at least 3 other algorithms so best the best algorithm fits our model.
DECISION TREE CLASSIFICATION
Let’s look at the evaluation parameter.

Here, we get an accuracy score of 0.959, which is the best accuracy reached till now. As it is best of all, we can go with this algorithm.
General approach for Classification should be, check the accuracy with KNN, if accuracy is not then go for Decision tree, then for Random Forest.
So, till now we have learned how to find the best model for Supervised Machine Learning.
Now, let’s enter into another chapter:
UNSUPERVISED MACHINE LEARNING
The main algorithm in Unsupervised ML is K-Means and Hierarchical Clustering.
It’s not that tough to guess the algorithms in Unsupervised ML, things are clearer.
| Hierarchical Clustering | K-Means | |
| Running Time | Slower | Faster |
| Assumptions | Requires distance metric | Requires distance metric |
| Parameters | None | K (number of clusters) |
| Clusters | Subjective (only a tree is returned) | Exactly K clusters |
I guess now, things are pretty clear from the chart. Depending on your requirement of the Model you can choose the algorithm.
Now, you will be able to distinguish how to approach a model selection in Machine Learning.
Written By: Ketki Kinkar
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs