
Naïve Bayes comes under a supervised machine learning approach. It is a classifier machine learning model that’s in use for classification task. This probabilistic algorithm is on the Bayes theorem.
Why is it called Naïve Bayes?
The entire algorithm is based on Bayes’s theorem to calculate probability. So, it also carries forward the assumptions for Bayes’s theorem. But those assumptions(that the features are independent) might not always be true when implemented over a real-world dataset. So, those assumptions are consider to Naïve and hence the name.
Bayes’s Theorem
Bayes’s theorem mainly shows the probability of an event, based on previous knowledge of conditions that might be related to the event. Mathematically, it can be written as:

Where A and B are the events & P(B)≠0
- P(A|B) is a conditional probability: the likelihood of event A occurring provide that B is true.
- P(B|A) is also a conditional probability: the likelihood of event B occurring conferthat A is true.
- P(A) and P(B) are the probabilities of observing A and B respectively and are also as the marginal probability.
We’ll extend this same understanding to understand the Naïve Bayes Algorithm.
Algorithm steps:
- Let’s consider that we have a binary classification problem i.e., we have
two classes in our data as shown below.

- Now suppose if we are given with a new data point, to which class does that point belong to?
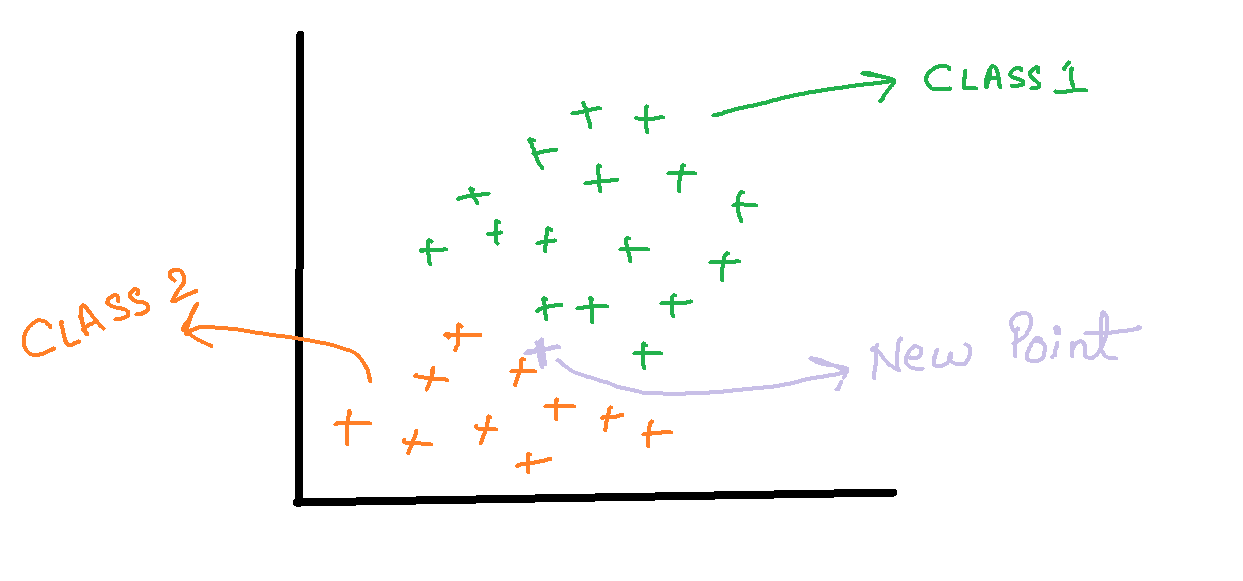
- The formula for a point ‘X’ to belong in class1 can be written as:

- Where the numbers represent the order in which we are going to
- calculate different probabilities.
- A similar formula can be utilise for class 2 as well.
- Probability of class 1 can be confer as:
P(Class1)=Number of Points in class/Total Number of Points=1626=0.62
- For calculating the probability of X, we draw a circle around the new point and see how many points(excluding the new point) lie inside that circle.
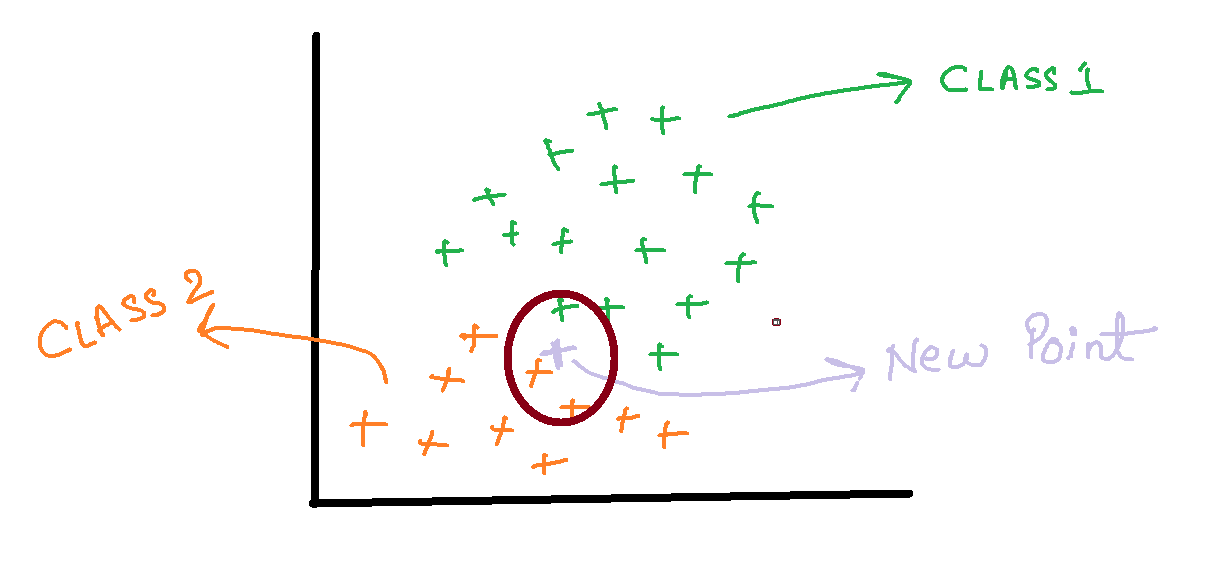
The points inside the circle are consider to be similar points.
P(X)=Number of similar observations/Total observations=3/26=0.12
- Now, we need to calculate the probability of a point to be in the circle that we have made given that it’s of class 1.
P(X/Class1)=Number of Points in class1 inside the circle/Total numbers of points in class=116=0.06
- We can substitute all the values into the formula in. step 3
We get: P(Class1 /X)=0.06∗0.62/0.12=0.31
- And if we calculate the probability that X belongs to Class2, we’ll get
0.69. It means that our point belongs to class 2.
The Generalization for Multiclass
The approach discussed above can also be generalise for multiclass problems. Suppose we have ,
P1, P2, P3…Pn are the probabilities and for these probabilities we have classes C1,C2,C3…Cn, then the point X will belong to the class for which the probability is maximum.
Mathematically ,the point belongs to this result that is : argmax(P1,P2,P3….Pn)
The Difference
You can easily see the difference in the way that in which the Naïve Bayes algorithm works form other classification algorithms. It’s not first to try to learn how to classify the points. It directly uses the tag to identify the two independent classes and then it predicts the class to which the new point shall belong.
Types of Naïve Bayes Classifier
Multinomial-
This is mainly use for multinomial distributed data, and is one of the two classic Naïve Bayes variants use in text classification that is whether a text might belong to the category of sports, politics, technology etc.
Bernoulli-
Basically, This is similar to the multinomial Naïve bayes but the predictors are binary valued variables(Bernoulli, boolean) and it implements the Naïve Bayes training and classification algorithms for the data that is distributed according to multivariate Bernoulli distributions.
that is there may be multiple features but each one is assume to be a binary-value variable. Therefore, this class requires samples to be represent as binary-valued feature vectors; if handed any other kind of data, a Bernoulli Naïve Bayes instance may binarize its input.
Gaussian Naïve Bayes
When we deal with continuous data then we will typically assume that the continuous values associate with each class are distributed according to a Gaussian distribution.
Let’s take an example of using the Gaussian Distribution, Suppose we have a training data which contains a continuous attribute that is x. Now, We will follow few steps:
1. Slice the data by the class, and then compute the mean and variance of x in each class. Let μc and σ2c are the mean and the variance of the values in x associated with class c.
2. Then, the probability distribution of some value given a class, p(x=v|c) that can be compute by plugging v into the equation for a Normal distribution parameterize by μc and σ2c. That is:

Advantages of Naïve Bayes
- Naïve Bayes is extremely fast for both training and prediction as they do not have to learn to create separate classes.
- It provides a direct probabilistic prediction.
- Naïve Bayes is often easy to interpret.
- It has fewer (if any) parameters to tune
Disadvantages of Naïve Bayes
- The algorithm assumes that the features are independent which is not always the scenario
- Zero Frequency i.e. if the category of any categorical variable is not seen in training data set even once then the model assigns a zero probability to that category and then a prediction cannot be done.
Conclusion
In this article we have learnt about Naïve Bayes, why is it pronounce as Naïve bayes and how the Naïve Bayes algorithm works . We have also seen the types of Naïve Bayes, advantages and it’s limitations. Naïve Bayes is fast and easy to implement. Naïve Bayes algorithms are generally in use for sentiment analysis, spam filtering, recommendation systems etc.
Written by: Ruchi
Reviewed by: Shivani Yadav
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs