
so, In this blog we’ll discuss:
- What is a Support Vector Machine?
- How does it work?
- Kernel tricks
- How to implement Linear SVM in Python?
- How to fix misclassified data points?
So, let’s get started!
What is a Support Vector Machine?
Support Vector Machine (SVM) is one of the most powerful algorithms in machine learning which is mostly used for classification problems and sometimes for regression problems. It is a supervised machine learning algorithm that gives higher accuracy with minimal computation cost.
How does it work?
Let’s understand the concept of SVM with an example, we have two categories of data: triangles and circles. though I asked you to classify these data or to split these data. What would you do? however, You could split that data in three possible ways by drawing the lines (yellow, red, and black) as shown below. All these ways potentially work.
https://www.canva.com/design/DAENFTqbid4/grwDpflzSJKLrHsyBDTqqg/edit
What if I asked you to split the data in the best possible way? Well, then you will probably say that splitting that data with a black line looks more appropriate than others.
From this, we can say that SVM is the model that helps to find an optimum way of classifying triangles and circle groups.
So why is this the best split?
Assume that the black line in the middle of the path and there are two other lanes of the path as shown below.
https://www.canva.com/design/DAENFUfdgy0/GEosD_ND7bTCuTXmWgsp1g/edit
So in this case this is the widest path that separates these two groups. Another way of saying this is the distance between the data points and the black line.
Now let’s deep dive into some more technical terms, instead of saying path. we can say that this is the widest margin that separates these two groups.
Again instead of saying data points and lines here can also – support vectors and hyperplane respectively.
https://www.canva.com/design/DAENFYB8N1o/fmJqnUinqbxWuzxknrS4Dg/edit
We can summarize from the above discussion that the hyperplane, also known as decision boundary, is the best split that classifies the data and it should be as far as possible from support vectors. Additionally, it should have a maximum margin which is the distance between hyperplane and support vectors.
This type of SVM is also called Linear SVM which is used for linearly separable data, as the given data is classified into two groups using a single straight line.
Kernel tricks
We can separate the data points with SVM using different kernel tricks. It transforms input data into the required format by adding another dimension to it. It makes SVM more accurate, powerful, and flexible. Some of the kernels used in SVM are given below:
- Linear
This type of kernel is commonly used when data is linearly separable. It works very well with text classification problems.
- Radial Basis Function (RBF)
This type of kernel is mostly used when data is non-linearly separable.
- Polynomial
This type of kernel is often used in practice because it is less efficient and accurate than others.
- Sigmoid
This type of kernel is occasionally used in practice to perform a specific task. It is more useful in neural network problems than SVM.
How to implement Linear SVM in Python?
Let us start with a code,
Step 1: Import Libraries

Step 2: Import Dataset

Output:
https://www.canva.com/design/DAENGuPovrE/uahR3-wYg-tvkvsvUJBAxA/edit
Step 3: Prepare the Data

Output:
https://www.canva.com/design/DAENGsKqJoA/TEhG3MxZCXNLcpMl0-tpOQ/edit
Step 4: Fit the Model

Step 5: Visualize the Results

Output:
https://www.canva.com/design/DAENHj6PCMs/Frb2ME-AzJU4IFepc6lblQ/edit
Step 6: Predict New Case
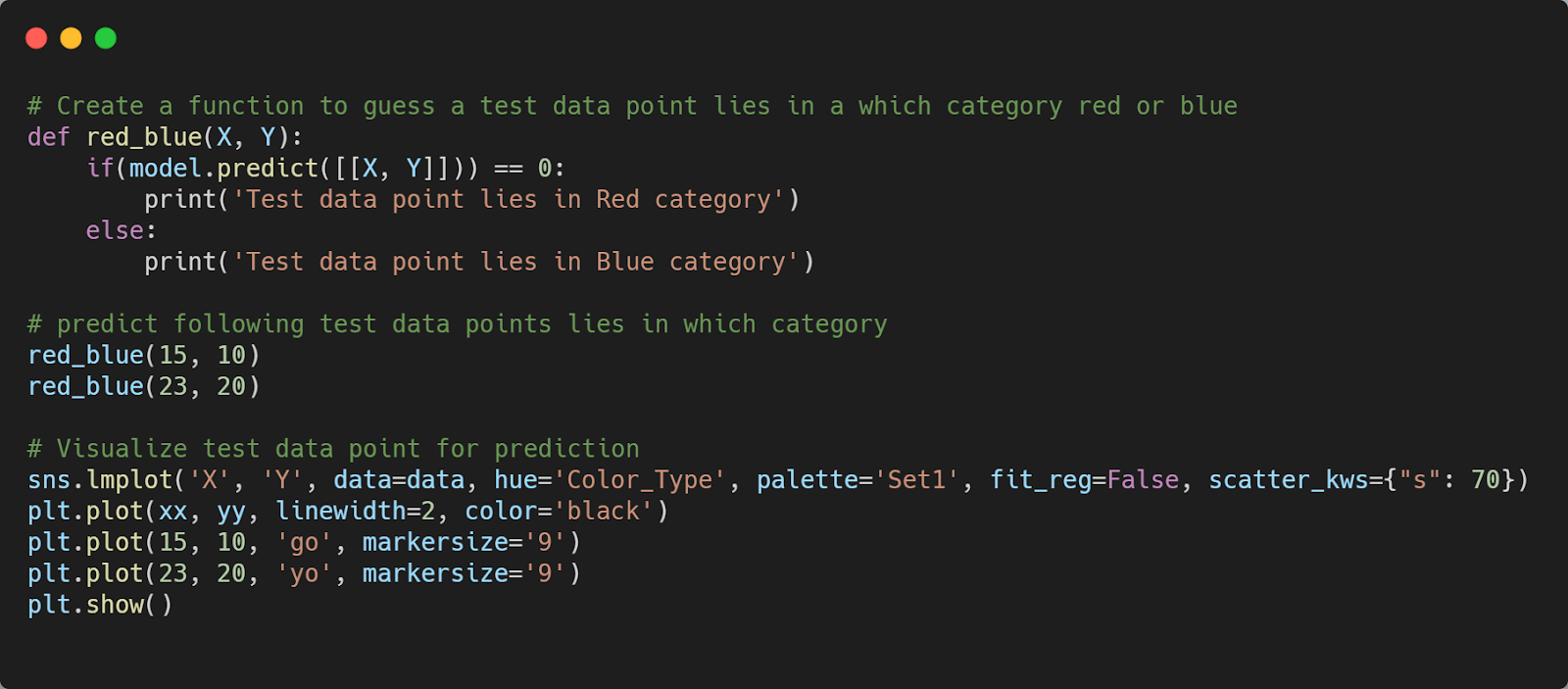
Output:
https://www.canva.com/design/DAENH__U8LE/sZv8LzoIvutF2FJEf4omsg/edit

How to fix misclassified data points?
In the below image the red data point gets misclassified.
https://www.canva.com/design/DAENIGTCyeo/U0Ff9rn3VMGIKZHpeeaQrg/edit
So, we can fix such issues by changing the value of Regularization factor C. The C parameter tells the SVM optimization how much you want to penalize misclassified points. The default value for the C parameter is 1, but we can vary it.
C value: Comparison
SVM Model with low C Value of 2-5. Here you can see misclassification happened. Low C parameter prioritizing simplicity so this line here is also refer as a soft margin.

https://www.canva.com/design/DAENUJ74tC0/v2MLd1wG-u0DCjbL_9tZgg/edit
On the other hand, the SVM Model with high C Value of 25. There is no misclassification. High C parameter prioritizing making few mistakes so this line here is also refer as a soft margin.

https://www.canva.com/design/DAENUC597m0/xbpzbX-cwSizr4ONu3h84Q/edit
Well, then to pick the best value of C, you need to try different values for your model.
Merits and Demerits associated with Support Vector Machine
Merits:
- It provides high accuracy with less computation power.
- can be in use for both linearly and nonlinearly separable data.
- It is good at dealing with high dimensional space.
Demerits:
- requires high training time for the large dataset.
- thus, works poorly with overlapping classes.
- It is also computationally intensive in choosing the right kernel and parameters.
Applications | Support Vector Machine
Some of the real-world applications of SVM are listed below:
- Face detection
- Computational biology
- Text-based applications
- Chaotic systems control
- Handwriting recognition
- Security-based applications
- Image-based classifications
- Geo and Environmental Sciences
- Generalized Predictive Control (GPC)
- Protein fold and remote homology detection
Conclusion
I hope you have found this blog helpful in understanding the basic concept of a Support Vector Machine. You might wonder why I did not go into long, complicated math equations, and their derivatives in detail. It is mainly because it is rare you will write your algorithm and mathematical proofs on a real-time project.
therefore, There are many different packages and libraries available which makes it easier to implement any machine learning applications without knowing deep background in statistics.
hence, In this blog, I discussed kernel tricks, the process of implementation in python with an example, and additional complexities. At last, I talked about the merits and demerits of SVM followed by real-world applications.
written by: Preeti Bamane
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs