
In This Blog, We Will Discuss the Following Topics,
- What Is Boosting?
- Adaptive Boosting
- How to implement AdaBoost in Python?
What Is Boosting?
Like A Human Being Learning From Their Mistakes And Trying Not To Repeat Them In The Future, Similarly, The Boosting Algorithm Tries To Build A Strong Learner (Powerful Predictive Model) From Prior Mistakes Of Many Weak Learners. Models Are Sequentially Produced During The Training Phase.
Then The Second Model Is Created Based On The Previous One By Reducing The Errors Which Are Present In The Previous Model. This Process Is Going On Until We Get Accurate Predictions With Minimum Errors.
https://www.canva.com/design/DAENwhFdgeo/_j5sbDsq3SYKHKuPxQJWOw/edit
Adaptive Boosting or AdaBoost
AdaBoost Combines Multiple Weak Learners To Build One Strong Learner Which Makes Better Classification. therefore, The Weak Learners Are Almost Always Decision Stumps. now, Stump Is Usually A One Node And Two Leaves As Shown Below.
https://www.canva.com/design/DAENwpxqfqA/RpIggOEI1Mzq5crgwPPP2g/edit
Weak Learner Performs Better Than Random Guessing But Still Performs Poorly While Making A Decision. For Instance, A Weak Learner May Predict That People Falling Below The Age Of 20 Could Not Drive A Car But People Above That Age Could. Now You Might Get 70% Accuracy But You Would Still Be Misclassifying Lots Of Data Points!
therefore, Each Decision Stump Is Made By Taking The Previous Stump’s Mistake Into Account.
https://www.canva.com/design/DAENwrUDrwQ/FfltR0oA0Wh3LcLNCidj4w/edit
The Classifier Can Be Any Machine Learning Algorithm Such As Decision Tree (By Default), Logistic Regression, Random Forest, Etc. also, AdaBoost Algorithm Applied On Top Of Any Classifier That Learns From Its Flaws Which Makes A More Accurate Model.
https://www.canva.com/design/DAENxHNk9NY/-OCKTixxOi7IHmSP5RU55g/edit
As We See That, The First Decision Stump S1 Is Made Separating The Red Dot And Blue Dot. We Noticed That S1 Has Two Incorrectly Classified Red Dots. The Incorrect Classified Carried More Weight Than The Other Observations And Fed To The Second Learner. The Model Will Continue And Adjust The Error Faced By The Previous Model Until The Most Accurate Predictor Is Built.
How does it Works?
| Row No. | Feature 1 | Feature 2 | Feature 3 | Output |
| 1 | Yes | |||
| 2 | No | |||
| 3 | Yes | |||
| 4 | Yes | |||
| 5 | No |
Above Sample Dataset Consists Of Three Features, And The Output Is In The Categorical Form Yes Or No. This Is A Classification Problem.
Steps for Adaptive Boost:
1. Initialize The Weight As 1/N To Every N Observations
W = 1/N Where, N Is The Number Of Records.
| Row No. | Feature 1 | Feature 2 | Feature 3 | Output | Sample weight |
| 1 | Yes | 1/5 | |||
| 2 | No | 1/5 | |||
| 3 | Yes | 1/5 | |||
| 4 | Yes | 1/5 | |||
| 5 | No | 1/5 |
2. Select The 1 Features According To Lowest Gini / Highest Information Gain And Calculate The Total Error.
| Row No. | Feature 1 | Feature 2 | Feature 3 | Output | Sample weight | Predicted Output |
| 1 | 1 | 0.2 | 1 | |||
| 2 | 0 | 0.2 | 1 | |||
| 3 | 1 | 0.2 | 1 | |||
| 4 | 1 | 0.2 | 0 | |||
| 5 | 0 | 0.2 | 0 |
Suppose We Get 2 Misclassifications And 3 Correct Classification.
Total Error = ⅖ = 0.4
3. Calculate The Performance Of The Stump
Performance Of Stump = 0.5 * [log_e (1-Total Error)/(Total Error)]
= ½ * [log_e (1-0.4)/(0.4)] = 0.5 * [log_e (1.5)] = 0.5 * 0.41
Performance Of Stump = 0.205
4. Calculate The New Weight For Each Misclassification (Increase) And Right Classification (Decrease)
New weights = Old Weights * e ^ (+/- Performance)
- For Misclassification
- For Correct Classification
New Weights For Misclassification = 0.2 * e^+0.205 = 0.2 * 1.22 = 0.244
also, New Weights For Correct Classification= 0.2 * e^-0.205 = 0.2 * 0.81 = 0.162
| Row No. | Feature 1 | Feature 2 | Feature 3 | Output | Sample Weight | Predicted Output | Updated Weights |
| 1 | 1 | 0.2 | 1 | 0.162 | |||
| 2 | 0 | 0.2 | 1 | 0.244 | |||
| 3 | 1 | 0.2 | 1 | 0.162 | |||
| 4 | 1 | 0.2 | 0 | 0.244 | |||
| 5 | 0 | 0.2 | 0 | 0.162 | |||
| 1 | 0.974 |
5. now, Normalize The New Weights So That The Sum Of Weight Is 1
Normalized Weights = Updated Weights / Total Sum Of Updated Weights
| Row No. | Feature 1 | Feature 2 | Feature 3 | Output | Sample weight | Predicted Output | Updated Weights | Normalized Weights |
| 1 | 1 | 0.2 | 1 | 0.162 | 0.166 | |||
| 2 | 0 | 0.2 | 1 | 0.244 | 0.251 | |||
| 3 | 1 | 0.2 | 1 | 0.162 | 0.166 | |||
| 4 | 1 | 0.2 | 0 | 0.244 | 0.251 | |||
| 5 | 0 | 0.2 | 0 | 0.162 | 0.166 | |||
| 1 | 0.974 | 1 |
6. so, now Creating new Dataset with new weights
| Row No. | Feature 1 | Feature 2 | Feature 3 | Output | New Weights |
| 1 | 1 | 0.166 | |||
| 2 | 0 | 0.251 | |||
| 3 | 1 | 0.166 | |||
| 4 | 1 | 0.251 | |||
| 5 | 0 | 0.166 | |||
| 1 |
7. Now Repeat From Step 2 And So On Till The Configured Number Of Estimators Reached Or The Accuracy Achieved.
How To Implement AdaBoost In Python?
however, Income Dataset Is Selected For AdaBoost Algorithm Implementation.
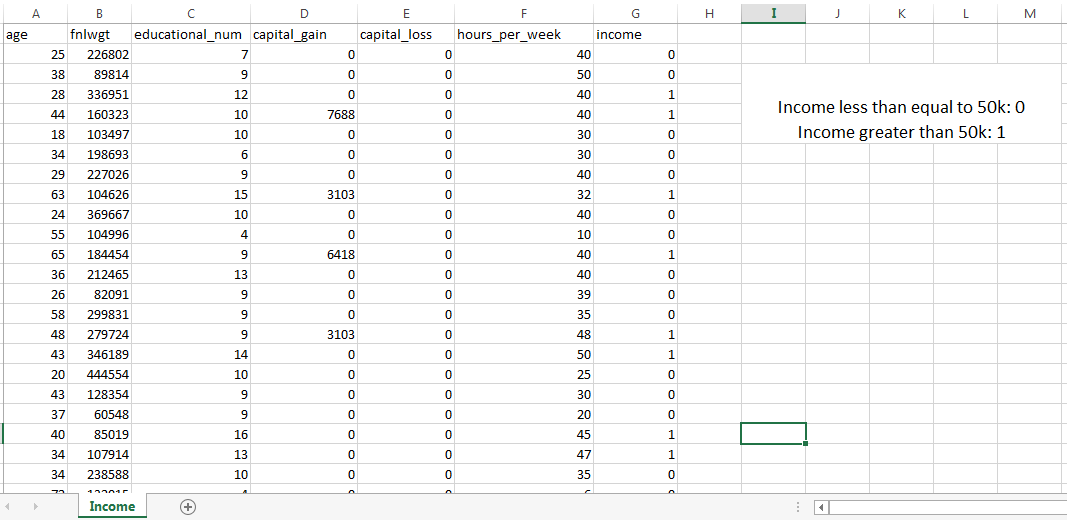
thus, Let’s Take A Look At The Implementation Of AdaBoost() In Python.

Data Preparation

Output:

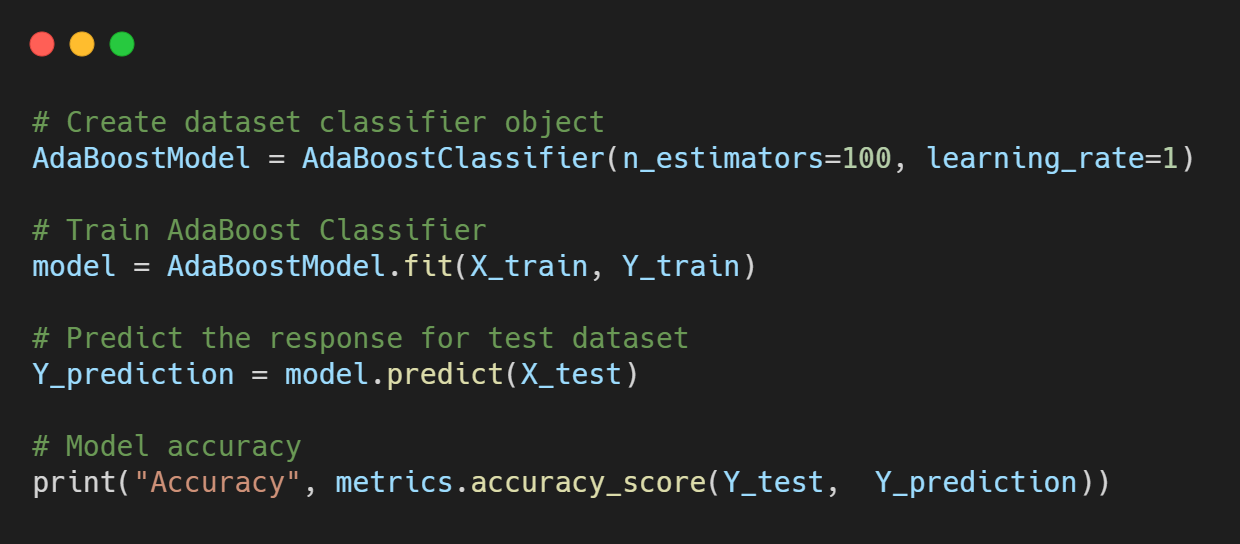
Model training and evaluation
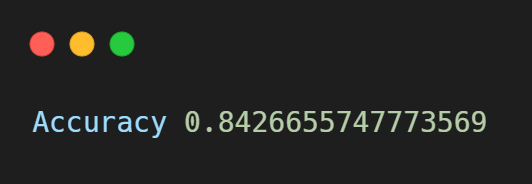
Output:
Merits and Demerits associated with AdaBoost
Merits:
- AdaBoost Is Fast, Simple And also Easy To Implement.
- It thus Iteratively Fixes The Errors Of The Weak Classifier And Increases Precision By Combining Weak Learners.
Demerits:
- It Is Sensitive To Noise Data.
- It Is Vastly Affected By Outliers Since It Attempts To Fit Each Point Perfectly.
- AdaBoost Is Slower Compared To XGBoost.
Conclusion on AdaBoost:
however, This Blog Helps To Understand The Basics Of AdaBoost Algorithm With Easy Explanation. It’s Functioning And Execution, Giving You A Foundation To Explore Further. thus, Hope You Enjoyed The Blog.
Written By: Preeti Bamane
Reviewed By: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs