
Human beings have a marvellous tendency to duplicate or replicate nature. For example:- We saw birds flying in the sky , and we wanted to have flying objects that we create on our own like Airplanes, which were first such objects which was created that could fly, were the result of that observation and the willingness to replicate what we saw and found worthwhile . Nature is the centermost part of every such innovative innovation.
But science has tried to replicate the human brain. Many professionals and researchers have gone into grasp how the human brain works and how it holds everything easily without mess , also interprets and manages a wide range of information .
Then the idea of artificial neural networks brings out innovation from and is the appropriate representation of the biological neural networks of the human brain. As we know this very well that machines replicate the working of a brain – not every function but at least of a few functions. Artificial intelligence has given us machines that communicate with us,play games better than us, and can classify objects ,not in every function but in some they work better than humans .
What is a neural network?
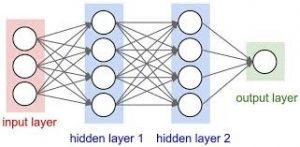
A neural network is created when a collection of nodes or neurons are interlinked through synaptic connections.Artificial neural networks are estimating models that work similar to the functions of a human nervous system.
There are three layers in every artificial neural network – input layer, hidden layer, and output layer. The input layer that is formed from a collection of several nodes that receives inputs,a hidden layer is placed between the input and output of the
method, in which the function puts weights to the inputs and channels them through an activation function as the output. The output layer gives the final outputs.
Look how a normal neural network works:-

About Perceptron
A perceptron, a neuron’s computational model , is graded as the simplest form of a neural network. Frank Rosenblatt invented the perceptron at the Cornell Aeronautical Laboratory in 1957.

The theory of perceptron has an analytical role in machine learning. It is used as an algorithm or a linear classifier to ease supervised learning for binary classification. A supervised learning algorithm always consists of an input and a correct/direct output. The aim of this learning problem is to use data with right labels for making more accurate predictions on future data and then helps for training a model. Some of the common problems of supervised learning built on the top of classification to predict class labels.
So , in simple terms ,‘PERCEPTRON” so in the machine learning , the perceptron is a term or we can say, an algorithm for supervised learning intended to perform binary classification Perceptron is a single layer neural network and a multi-layer perceptron is called Neural Networks.Perceptron is a linear classifier (binary) as discussed above . Also, it is used in supervised learning. It helps to classify the given input data given
WHAT IS BINARY CLASSIFIER?
It is one of the most frequently used problems in machine learning. In simplest form the user tries to classify a unit into 1 of the 2 possible categories. For example, take the attributes of the fruits like color, peel texture, shape etc.
A linear classifier that the perceptron is classified as is a classification algorithm, which depends on a linear predictor function to make the predictions and predictions are based on the union that includes weights and feature vector. The linear classifier recommends 2 categories for the classification of training data( means we can say entire training data will fall under these two given categories)
As discussed above , the perceptron is a linear classifier — an algorithm that classifies the input by dividing the 2 categories with a straight line. Here , Input is basically a feature vector x multiplied by w( i.e weights) and added to a b (bias)
y = w * x + b
In some framework and machine learning related problems, the perceptron learning algorithm can be found out. It could show limitations that you knew never existed. At one point, the perceptron networks were also found to be not competent enough to carry through some of the basic functions. However, this problem was share-out with as soon as multi-layer perceptron networks and ameliorate learning rules came into the concept.
So Perceptron today has become a major learning algorithm as in the world of Artificial Intelligence and Machine Learning . It examines a very reliable and fast solution for the classification of all the problems it has the potential of solving. Also we can say , if you develop a grip on the working of perceptrons ,.you will then find out the easier way in understanding more complex networks fast.
What are the main components of a perceptron?
Input value : In the perceptron algorithm, features are taken as InputsInputs are denoted as x1, x2, ……. xn ,‘n’ the total instances of these features. Weights: Values that are calculated during the training of the model. With every error i.e training error , the values of weights are updated. Weights are denoted as w1, w2, ……wn.
Bias: It allows the classifier to move the decision dividing line around from its initial position in the direction (right, left, up, or down). The purpose of the bias is to shift each point in a specific direction for a specified distance. Bias allows for the higher quality and training of the model is faster .
Activation/step function: Activation or step functions are used to generate non-linear neural networks.
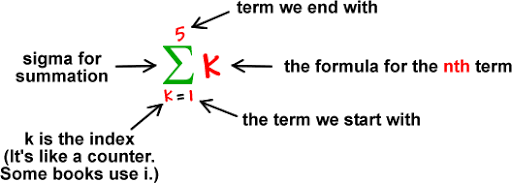
Weighted summation: The multiplication of every feature or input value (xn) associated with related values of weights (wn) gives us a sum of values that is known as weighted summation. Weighted summation is denoted as ∑wixi (i -> [1 to n])
Perceptrons put together a single O/P based on various real-valued Inputs by set up a linear combination using Inputs weights that are given In mathematical terms:
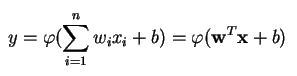
Where,
w represent the vector of weights
x is the vector of Inputs
b is called bias
φ is the non-linear activation function which sometimes used

As you can see in the given picture , it has multiple layers.
The perceptron mainly consists of four parts, they are:-
Input values or One input layer
Weights and Bias
Net sum
Neural Networks work the similar method as the perceptron. So, if you want to know how neural networks work , firstly we learn about how perceptron work?
Look at the below diagram to understand the working of perceptron :-
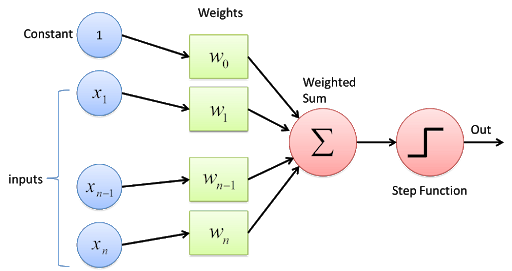
Understand the working of perceptron with the help of diagram:-
The perceptron works on these simple steps:-
1. All the inputs values x are multiplied with their respective weights w. Let’s call it k.
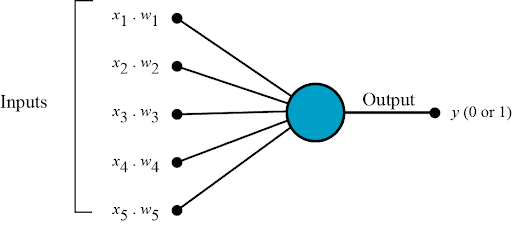
2. Add all the multiplied values and call them Weighted Sum.
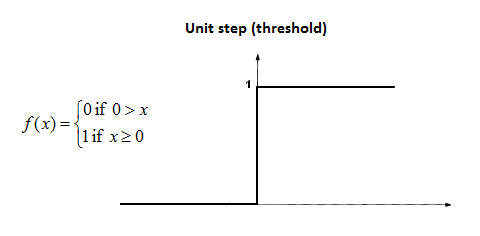
3.Apply that weighted sum to the correct Activation Function.
For Ex : Unit Step Activation Function.
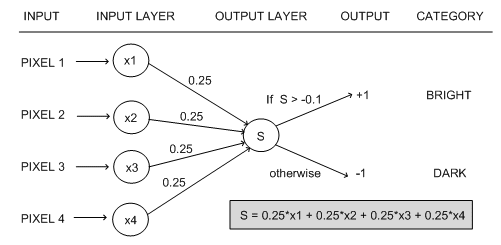
Use of Weights and Bias?
Weights indicate the strength of the particular node as already explained above .
A bias value permits you to shift the activation function curve up or down.
Why do we need Activation Function?
In short, the activation functions are used to map the input between the required values like (0, 1) or (-1, 1).
Fast forward to 1986, when Hinton, Rumelhart, and Williams published a paper “Learning representations by back-propagating errors”, found backpropagation and hidden layers concepts — then Multilayer Perceptrons (MLPs) came into existence :
Backpropagation, a method to repeatedly modify the weights so as to decrease the difference between actual O/P and desired O/P
Hidden Layers which are neuron nodes put together in between Inputs and outputs, allowing neural networks to learn more complex features .
An MLP therefore, known as a deep artificial neural network. It is a collection of more than one perceptron. They are composed of an input layer to receive the signal, an output layer that makes a choice or prediction about the input, and in between, an random no. of hidden layers (True computational engine of the MLP)
Multilayer perceptrons train on a set of pairs of I/O and learn to model the connection between those inputs and outputs. Training requires adjusting the framework , or the weights and biases, in order to decrease the error. Backpropagation is used to make those given weight and bias adaptation relative to the error, and the error itself can be used to measure in a variety of ways , including by root mean squared error.
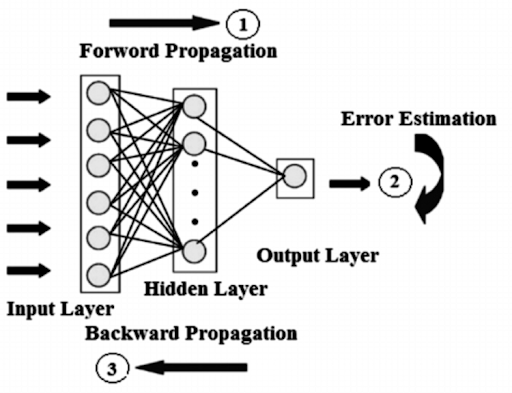
In the above diagram , the forward pass, the signal flow movement is from the input layer through the hidden layers and then to the output layer, and the conclusion of the output layer is measured against the truth labels.
And in the backward pass, by using backpropagation and the chain rule of calculus, biased derivatives of the error function concerning the dissimilar weights and biases are back-propagated through the Multilayer perceptron.
In this network game of ping -pong keep going on until the error can go to a lower stage . This state is known as convergence.
I hope this blog gave you a meaningful and clear understanding of these commonly used terms and their use/roles in a better understanding of neutral networks ,Perceptron and terms related to machine learning .
Article By : Shivangi Pandey
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other technical and Non Technical Internship Programs