When a statistical model fits more data than its need, it starts catching noise data & inaccurate values in data. As a result of which efficiency & accuracy of the model decreases.
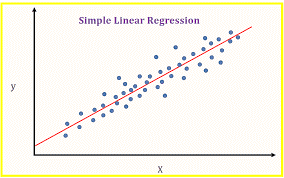
For example, in simple linear regression training the data is all about finding out minimum cost between best fit lines & data points. This goes to a number of iterations to find out optimum fitted lines. So, there is point where overfit comes into picture’
Here line in regression graph can give an efficient outcome for new data points
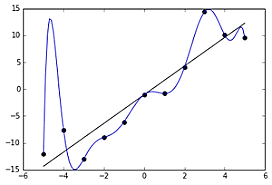
In case of overfitting, when we run training algorithm, we allow the cost to reduce for each number of iterations, so running this algorithm for too long will mean a reduce cost but it will also fit the noisy data from dataset the result is like this:
This might look efficient but not really but the main goal of the algorithm is to find the dominant trend & fit the data points accordingly but in this case all the line fits all the data point which is irrelevant to the efficiency of the model in predicting optimum output for the new entry data point.
Let’s see with an example:
Let’s say we have a problem to consider like we want to predict if a soccer player will land a slot in the tier 1 football club-based on his/her current performance in the tier 2 league.
So, now imagine we train and fit the model with 10000 such players then try to predict the outcome on original datasets let’s we got a 99% accuracy that the accuracy of the different dataset comes around 50% this means the model is not generalized well for training dataset and unseen data so this is what overfitting looks like.
It’s very common problem in machine learning
Reasons of Overfitting
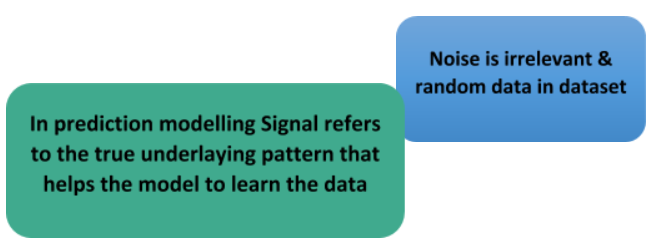
Signal & Noise:
For example,
Let’s suppose we want to model age Vs literacy carrying adults and if we sample a large part of population, we find a clean relationship between the two, this is signal, Whereas noise in phase of data.
So, the relationship between age & literacy if we do it in a small population like city, district the relationship between them slightly more so it would be affected by outlier, randomness irrelevant data e.g. (one adult want to school early, some adult cannot actually afford education or could not afford education)
So, there is the outlier and randomness picked as noise data hence the outfit model.
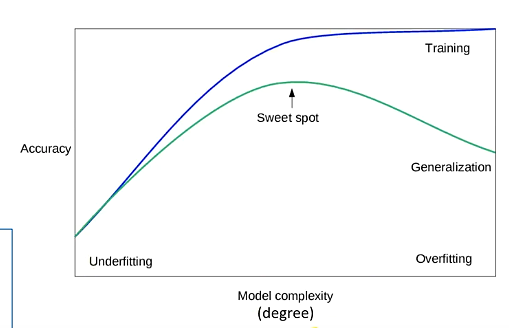
Underfitting:
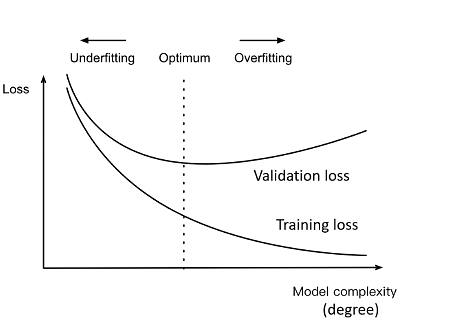
In order to avoid overfitting, we could stop training at an earlier stage but it might also lead to the model not being able to learn enough from training data, that it may find it difficult to capture the dominant trend. This is known as underfitting.
The result is the same as overfitting like it will cause inefficient in predicting the outcomes but its goanna takes a little less. That it needs to you know actually recognize the dominant trend inside the dataset.
Reasons of Underfitting
How we can detect Overfitting
The main challenge with overfitting is to estimate the accuracy of the performance of our model with new data. We address this problem by splitting the data into train & test data.
With this technique we accurately estimate how our model will perform with new data.
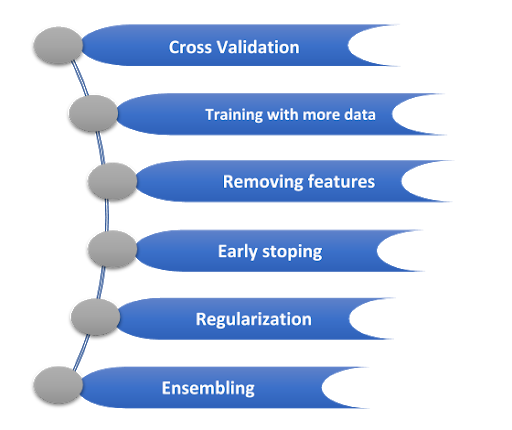
How to avoid overfitting
By using these techniques, we can avoid overfitting:
It is one of the most powerful feature to avoid overfitting,
The main idea behind this is to use the initial training plates and then use these to generate mini training plates and then use these plates to tune models.
In standard k fold validation data partitioned into k subsets also known as folds. After this algorithm is trained iteratively on (K-1) Folds while using the remaining fold as a test set which are also known as the holdout fold.
Cross validation helps us to tune the hyper parameters with only the original training set and it keeps the test set separately as true unseen data. Which will be selected for the final model hence avoiding overfitting as well.
This technique might not work every time as we have also discussed the example of population.
But it’s basically important to identify signal data, but in some cases increase in data can increase more noise but when we train models with more data, we have to care about data that is clean & free from any randomness and inconsistency then only works for you.
Some algorithms have an automatic selection of features for a significant number of those who don’t have a built-in feature selection. We can manually remove few irrelevant features from input features to increase generalization.
We are stopping the training process before the model passes that point where the model begins to over fit the training data so this technique is mostly used in deep learning, we can use in machine learning as well.
It basically means artificially forcing a model to be simpler by using a broader range of technique. So, it can totally depend on type of learners, we are using, e.g.
we can prune a decision tree and we can use a dropout in Neural networks or we can actually add a penalty parameter to the cost function in regression as well. So quite often regularization is a hyper parameter as well.
This technique basically combines prediction of different machine learning models.
The common methods are:
Bagging: attempts to reduce the chances of overfitting. It uses a complex model and tries to smooth out their prediction.
Boosting: attempts to improve flexibility of simpler models. It uses a simple based model and tries to boost aggregate complexity.
Goodness of Fit:
In statistical modelling, the goodness of fit refers to how closely the outcomes match the observed or true value.