
Decision Tree is a Supervised Learning technique wherein the data is label. Decision trees are majorly in use for classification purposes and sometimes to solve regression problems.
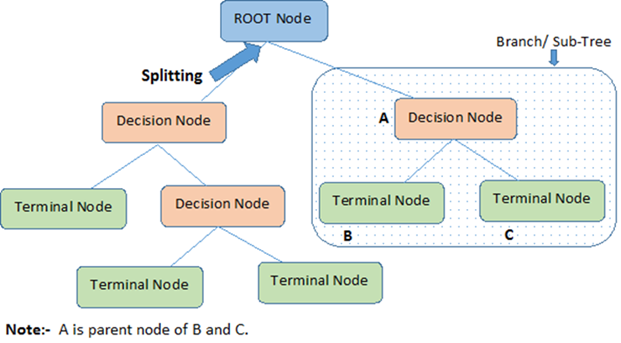
Terminologies in Decision Tree:
- Root Node- This contains all the observations of training data.
- Decision Node– When the root node further splits up into right and left nodes, its a decision node or child node. A decision node is a parent node to a terminal node.
- Terminal Node– A node that does not split further is a terminal node.
- Pruning of Tree- To ensure that the tree is not overgrown.
- Leaf/Terminal Node: Nodes that do not split further are called Leaf/Terminal nodes.
- Branch / Subtree: A subsection of the entire tree is a branch or sub-tree.
Data Checks Before Proceeding with Decision Tree Model:
- Data should have both 0s and 1s in it.
- Remove the NAs values.
- Checking for the default values like 0000, 999 etc., is essential. In this case, we can convert them into missing values and remove them, if necessary.
Classification Techniques:

- It is important to note that:
- o For a perfectly ‘pure node’, GINI Index will be 0.
- or o Highly ‘impure node’, GINI Index will be 0.5
- o Lesser the GINI Index, more is the ‘purity of the node’ and vice versa.
- GINI calculation is easy for binary variables. But what if we have a continuous variable?: In that case, different binary cut-offs are select upon and the best GINI Gain cut-off is shortlist, this is also the Greedy Algorithm- the decision which is not optimal.
- To overcome this problem of Greedy Algorithm, we can use the ‘Cross-Validation’ technique.
How does Cross-Validation (CV) Technique Work?:
- Assume k-fold cross-validation technique
Step-1: Decide on the value of ‘k’
Step-2: Data is then split into k-equal folds
Step-3: (k-1) out of k-parts are taken for the ‘training’ set, and the last part is for ‘testing’.
Step-4: Then one out of the (k-1)-parts becomes a part of ‘testing’ and the remaining goes into the ‘training’ set.
- This is executed k times and each time different ‘test’ data is used.
- Within the training data, the proportion of 0s and 1s keeps changing.
- Then the average of these 5 iterations can be considered and this helps in avoiding the Greedy Algorithm issue.
Advantages of CV:
a. Helps overcome Greedy Algorithm problem
b. Helps us in evaluating how good the model is with the unseen (test) data
c. Helps address the problem of over-fitting
Model Performance Measures:
- Confusion Matrix- A 2X2 matrix reflecting the performance of the model in 4 blocks.

- Accuracy- How accurately does the model classify the data points. Lesser the false prediction, the higher the accuracy.
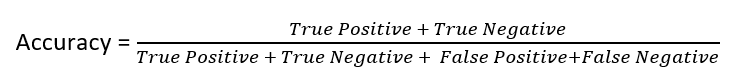
- Sensitivity/Recall- The actual true data points in the models that are identified as true data points.

- Specificity- The actual negative data points in the model that are identified as negative.

- Precision- Among the positives identified as positives by the model, how many are actually positives.

Few Important Points:
- The higher the Sensitivity, the lower the False Negative/Type-II Error in the model.
- The higher the Precision, the lower is the False Positive/ Type-1 Error in the model.
- Depending on the business problem at hand, we can decide on the importance of Accuracy, Precision, and Recall.
- Both Type-I and Type-II Errors cannot be decreased at the same time and there is always a trade-off.
- Receiver Operating Characteristics (ROC)- This a graph that shows the trade-off between True Positive (Benefits) and False Positive (Cost) and is plotted as True Positive Rate versus False Positive Rate.

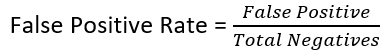

- The point (0,1) is perfectly classified where True Positive Rate (TPR) = 1 and False Positive Rate (FPR) = 0.
- The classifiers on the left lower side of the above graph are ‘conservative models’ which have low TPR.
- The classifiers on the top right are ‘liberal models’ with high TRP and FPR.
- Steeper the curve, the stronger the model, and better the classification and vice versa.
Area Under the ROC Curve (AUC)- Larger the area under the curve, the better is the model.
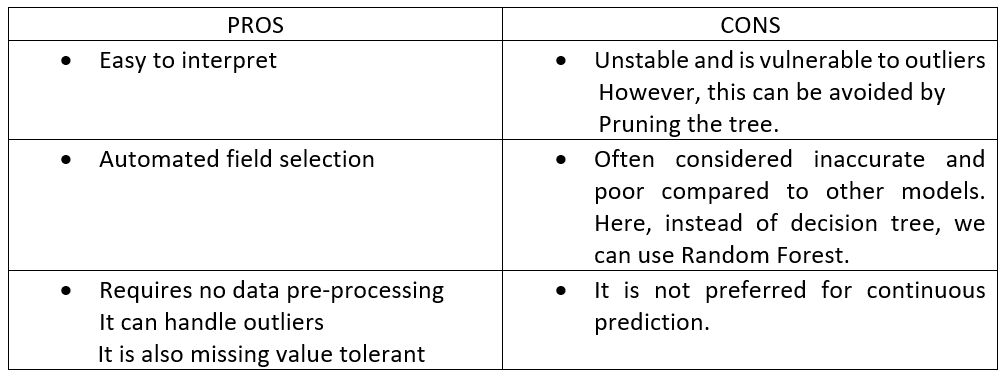
Pros and Cons of Decision Tree:
written by: Srinidhi Devan
reviewed by: Kothakota Viswanadh
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs