
A decision tree could be a classifier expressed as an algorithmic partition of the instance area. It consists of nodes that are kind of stock-still trees. It implies that it’s a direct tree with a node as “root” that has no incoming edges. All the opposite nodes should have specifically one incoming edge. A node with outgoing edges is largely is an interior.
All different nodes are consider as leaves that are refer terminal or call nodes. Decision tree algorithmic rule, every all the interior node splits the instance area into 2 or a lot of sub-spaces consistent with an exact distinct operation of the input attributes values.
Take a look at one attribute, such as the instance area is partition in keeping with the attribute’s price. Within the case of numeric attributes, the condition refers to a spread. Each leaf is allot to at least one category representing the foremost applicable target value. As an alternative, the leaf could hold a likelihood vector indicating the likelihood of the target attribute having a particular price.
Instances are classified by navigating them from the basis of the tree all the way down to a leaf, in keeping with the outcome of the tests on the trail. The below figure describes the decision tree node model.

How will the dT formula Work?
In a decision tree, for predicting the category of the given dataset, the formula starts from the foundation node of the tree. This formula compares the values of the root attribute with the record (real dataset) attribute and, supporting the comparison, follows the branch and jumps to consecutive nodes.
For consecutive nodes, the formula once more compares the attribute price with the opposite sub-nodes and moves additional. It continues the method till it reaches the leaf node of the tree. the whole method will higher understood victimization the below algorithm:
- Begin the tree with the foundation node, says S, that contains the whole dataset.
- Find the most effective attribute within the dataset using Attribute choice live (ASM).
- Divide the S into subsets that contain attainable values for the most effective attributes.
- Generate the choice tree node, that contains the most effective attribute.
- Recursively create new call trees victimization the subsets of the dataset created in step -3. Continue this method till a stage is reach wherever you can’t additionally classify the nodes and referr to as the ultimate node as a leaf node.
(Let’s draw a complete chart of a person who is an employee of a company by analyzing his salary)
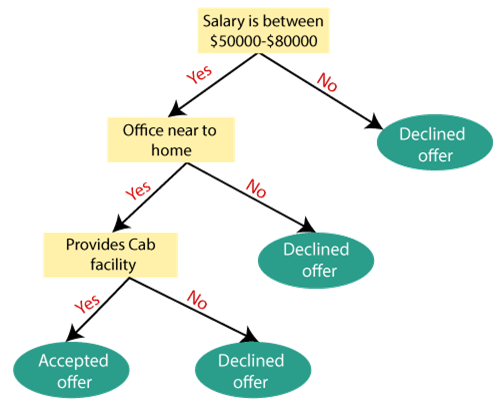
Why use decision Trees?
There square measure numerous algorithms in Machine learning, thus selecting the simplest rule for the given dataset and downside is that the main purpose to recollect whereas making a machine learning model. Below square measure the 2 reasons for victimization the choice tree:
Decision Trees typically mimic human thinking ability whereas creating a choice, thus it’s straightforward to know. The logic behind the choice tree may be simply understood as a result of it shows a tree-like structure.
Algorithmic Framework for Decision Trees
Algorithmic Framework for call Trees Decision tree inducers squares measure algorithms that mechanically construct a call tree. Usually, the goal is to search out the best call tree by minimizing the generalization error. However, alternative target functions may also outline. for example, minimizing the number of nodes or minimizing the average depth.
Induction of the associate best call tree from a given knowledge is taken into account to be a hard task has been shown that finding a negligible decision tree consistent with the coaching set is NP-hard (Hancock et al., 1996).
Moreover, it’s been display that constructing a negligible binary tree about the expect number of tests require for classifying associate unseen instances is NP-complete (Hyafil and Rivest, 1976). Even finding the negligible equivalent call tree for a tree (Zantema and Bodlaender, 2000) or building the best decision tree from decision tables believe to NP-hard (Naumov, 1991). The top of results indicates that victimization best call tree algorithms is feasible solely in little issues.
Consequently, heuristics are the square measure needed for finding the matter. Roughly speaking, these ways may be divided into two groups: top-down and bottom-up with clear preference within the literature to the first cluster. however, There square measure numerous top-down call trees inducers like ID3 (Quinlan, 1986), C4.5 (Quinlan, 1993), CART (Breiman et al., 1984).
Some incorporate two abstract phases: growing and pruning (C4.5 and CART).
Inducers perform solely the growing part. This presents a typical recursive framework for top-down inducement of a call tree victimization growing and pruning. Note that these algorithms are greedy and naturally construct the choice tree in an exceedingly top-down, recursive manner also called divide and conquer.
In every iteration, the algorithmic program considers the partition of the coaching set victimization the result of a separate performance of the input attributes.
Advantages:-
- it’s easy to grasp because it follows constant methods that somebody’s follow whereas creating any decision in real-life.
- therefore, It will be terribly helpful for the resolution of decision-related issues.
- It helps to have faith in all the attainable outcomes for a drag.
- There is less demand for Information improvement compare to alternative algorithms.
Disadvantages:-
- The choice decision contains immeasurable layers, that make it advanced.
- it’s going to have an associate degree overfitting issue, which may be resolved victimization the Random Forest formula.
- For additional category labels, the machine complexness of the choice tree might increase.
- Python Implementation of decision tree classifier.
Example: For the given ‘Iris’ dataset, produce the choice Tree classifier and visualize it diagrammatically. The aim is if we feed new knowledge to the present classifier, it might ready to predict the correct category.
GITHUB LINK of full source code: https://github.com/pramod1998-hash/THE-SPARK-FOUNDATION/blob/master/TSF%20TASK%204.ipynb
CONCLUSION
Decision tree algorithm returns from supervised learning models that may be used for both classification and regression tasks. The task that’s difficult in call trees is to see concerning the factors that decide the foundation node and every level, though the ends up in DT square measure are terribly straightforward to interpret.
written by: Pramod Panigrahi
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs