
Train, Test And Validation Dataset For Model Building, We Need To Divide The Dataset Into Three Different Datasets. These Datasets Are As Follows:
- Training dataset
- Validation dataset
- Test dataset
1. Training dataset
Training Data is the subset of the whole dataset which is use up for training the model. i.e. In model-fitting, we use a training dataset.
2. Validation of Dataset
Validation Dataset is the subset of the whole dataset that is extract from training data for better evaluation of model performance. As it is extraction from the training data so validation dataset can also be part of the training dataset.
So, basically, a validation dataset is used to achieve good performance of the model and also it helps to reduce overfitting of the model. The validation dataset is also used to tune hyperparameters to the model by using k-fold cross-validation with the training dataset.
3. Test Dataset
Test Dataset is the subset of the whole dataset which is use for the final evaluation of the trained model. So test data is use after the model is successfully training and validation. The test dataset is independent of the training dataset but test data must have to follow the same distribution as the training dataset.
Because if test data contains a totally different range of values then the model will never give good results. So this is the main constraint of a train, test, and validation dataset that they have to share the same distribution.

How to split the dataset into Train, Test, and Validation Dataset?
The ideal way of splitting is to divide the dataset into two-part trains and test into (80:20) ratio. Then from the training dataset, we can select the validation dataset to let’s say 20% of the training data is select as a validation dataset and the remaining data is use for training the model.
If a model has very few hyperparameters then there is no need for a validation dataset but if the model has a higher number of hyperparameters then a larger validation set is required.
We can also use the k-fold cross-validation to validate our model.
In k fold, cross-validation train data is divide up into k fold and training is complete iteratively into k times. Each iteration, k-1 fold data is treat it as a training dataset, and the remaining 1 fold acts as a validation dataset and this goes to k times to train and validate the model. Cross-validation is also use to avoid overfitting problems.
The library used for splitting train and test Dataset:-
In Python, From scikit learn model selection library there is a predefine method to as train_test_split() used for splitting the dataset into train and test set. Here is the code:
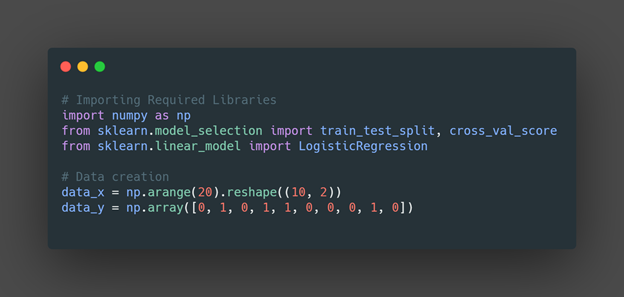
After splitting the data into train and test sets we have to apply some modeling techniques to fit the model on the training dataset.
In the training phase, we apply the cross-validation technique to partition the train set into n fold where training will be done for n iteration having n-1 fold for actual training, and 1 fold is use for testing. Here is the complete code:
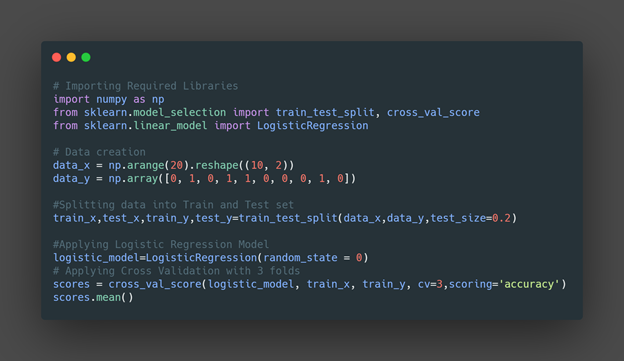
Result:
So, our aim is to build a model that performs well on unseen data. The common way to evaluate all the models is to see their error rate by their test data. So Various models are build by different minimization techniques with the help of training data set.
thus, the performance of the model is then compare by evaluating the cost function using an independent validation set and the model having the smallest error with respect to the validation set is select upon. And finally, the performance of the selected network should be confirm by measuring its performance by the test set.
Note: It is very important to note that we can’t skip the test phase as a model building because the algorithm that performed well during the training and cross-validation doesn’t mean that it is the best model and will provide good accuracy in the test phase. We can skip the validation phase on small dataset problems but don’t the test phase. It is recommended to use a validation set on a large set.
Conclusion:
In this section, we look at what are train, test, and validation of dataset. Additionally, how they train, test, and validation sets are different. thus, also how they are use in model building?
written by: Pooja Keshri
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs