
SOURCE: https://miro.medium.com/max/2160/0*ftz0GcJg5BGgdd5D.jpg
Support Vector Machine
The support vector machine is one of the most efficient classifiers, especially among all of those which are linear. Have you ever wondered how your smartphone is able to unlock with the help of your face? Or if you visit a website of any news agency and see their ‘business articles’ or ‘finance section’? All thanks to the Support vector machine. Not only here, even protein fold as well as remote homology observation, SVM algorithms are used almost everywhere.
What is the reason for the popularity of the support vector machine? As it will be notice, the SVM has a unique way of preventing overfitting. Also without requiring too much computation, one can work with a relatively larger number of features.
In logistic regression, one tries to find out,
P(Y=1/ X)= h (X)=g(TX)
The probability or in other words confidence is higher when h(X)>>0.5 or h(X)<<0.5, as one uses the sigmoid function which S shaped. Thus there is more confidence in the output which is farther from the decision surface.
Logistic regression actually gives a linear classifier. Consider two features x1 and x2,
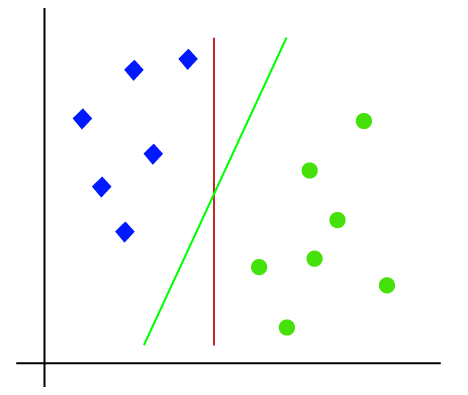
Example: SVMs
Let the lines represent the decision surface. For all the points that are closer to the surface, the confidence in the output of the point is less and vice-versa for the points farther from the decision surface. One can use Bayesian learning if there are a large number of features, but we know it is computationally intractable. Thus an alternative to bayesian learning which is computationally attractive is Support Vector Machines.
In Support Vector Machines, there is a need for a classifier such that it maximises the separation between the points and the decision surface. This brings us to the definition of margin.

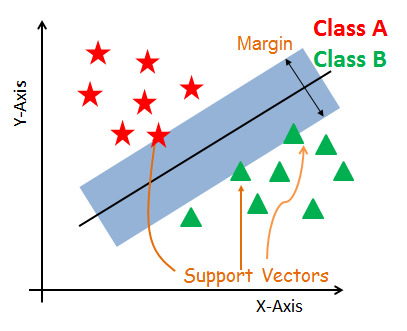
FIGURE 3: SUPPORT VECTORS AND THE MARGIN
SOURCE: https://res.cloudinary.com/dyd911kmh/image/upload/f_auto,q_auto:best/v1526288453/index3_souoaz.png
The distance of the decision surface from the closest point (from the decision surface) is known as the margin. The distance here refers to the perpendicular surface. In the above image, stars represent the negative point while the triangle represents the positive points. If the decision surface could have been shift, such that the perpendicular distance from the nearest positive point and the nearest negative point becomes equal. In this case, the width of the margin will be a little more. The width of the band will be twice the distance from the closest positive or negative point.
However, there will be other decision surfaces for which there could be other margins, and from those plausible surfaces, our aim is to choose that surface for which the width of the margin is the maximum. This is under the assumption that the training instances (that is, positive and negative points) are linearly separable, with the help of a linear decision surface. The points which are closest to the decision surface are considered. In figure 3 two triangles(positive points) and one star (negative points) are equidistant from the decision surface and closest too. These points are called Support Vectors.
There can be two or more support vectors (3 in this case), but usually, their number is very small.
The support vector helps in determination of the equation of the line, typically the support vector number being very small. Let us now look at the types of margin.
Functional Margin
Suppose there is a point (xi , yi) which is arbitrary. Let the equation of the decision surface (or visually it may be consider a line) be
WX+B=0
Where W and B refer to the parameters. The functional margin is measure by the distance of the point xi,yi from the decision boundary, which is state by (W,B). Consider the vector (W1, W2) which is normal to the line. The normal distance of (xi,yi) from the distance from decision surface is
i=Yi (WTXi+B)
If a new point is consider which is farther from the line, it will have a function margin different from and more than the original function margin. More the functional margin, more is the confidence in predicting the class of the point in consideration.
The functional margin for a set of points can also be computed. Suppose there are a set of points
S={(x1 , y1) , (x2 , y2) , ……… , (xm , ym)}
The functional margin for a group of points is define as
set of points=min i ∀ i=(1,2,…. , m)
The smallest functional margin of the different points is known as the functional margin for a group of points.
There is a problem in defining the margin as the distance because W and B can take any values. Let us consider w1=2 and w2=3 thereby making the equation of the line as
2X+3Y+1=0
The same line can be represented as
20X+30Y+10=0
400X+600Y+200=0
The line essentially remains the same but the functional margin becomes more. The functional margin thus not only depends on the line but also on the values of the coefficients of the line. Thus normalisation is carried out.
{kind=link}
{kind=link}
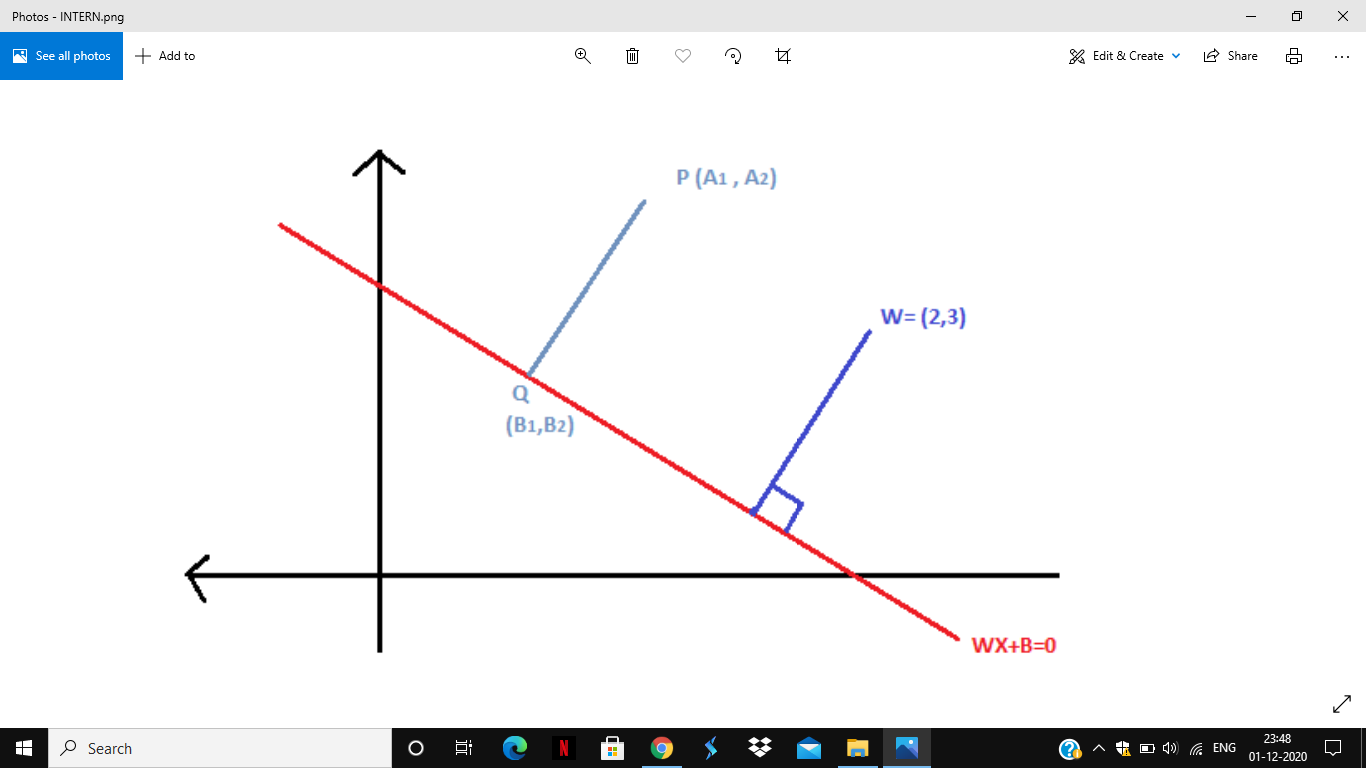
FIG 4: The Functional Margin of W from WX+B=0
Geometrical Margin
Geometrical margin is not affected by the scaling of the equation. Consider the same decision surface
WX+B=0
The normal to this decision surface is the point of interest which is given by
W||W||
Where ||w|| represents w norm. So the same vector w1=2 and w2=3 can be
represented as
W||W||=213,313
Consider a new point P (A1 , A2) and Q (B1 , B2) as shown in the same figure 4. If the distance from P to Q needs to be computed, it can be seen that the distance is in the direction of the normal vector. It is given mathematically as
P=Q +W||W||
Where P and Q represent the coordinates of P (A1 , A2) and Q (B1 , B2). Given the value of w, this equation can be written and can be computed. Since Q (B1 , B2) lies on the line, it can be written that
WT(P-W||W||) +B=0
WT((A1,A2)-W||W||) +B=0
Thus on manipulation,
=WT(A1,A2) +B ||W||
So, for geometric margin, W(that is the weights of the line) will be scaled, so that geometric margin is 1/||W|| and hence the geometric margin will be computed.
For a set of points, the geometric margin can be computed, same as the previous case, that is finding the geometric margin of all individual points and then selecting the minimum of them.
Maximise the Margin Width
The classifier with the maximum width of the margin is robust to the present outliers and thus is able to generalise efficiently.
Let us consider Fig 3 again. If (W,B) characterises the decision surface, then||W|| is the geometric margin. The aim is to learn the values (W,B) such that the margin is largest subject to the constraints
WXi+B
(for positive points)
WXi+B
(for negative points)
Maximising 1||W||is same as Minimising ||w|| which is w . w.
This translates to a quadratic programming problem and there are convex quadratic objectives with m inequality conditions being linear.
This type of quadratic problem is solved with a commercial quadratic solver. In this the problem is converted to dual formation with the help of Lagrange’s duality which allows one to use kernels to get the optimal margin classifier to work efficiently in very high dimensional spaces. It also aids us in deriving an efficient algorithm for solution of the above optimisation problem, that will give mind blowing performance as compared to generic QP software.
This performance of SVM is the reason that it is used extensively in protein fold as well as in remote homology observation because without requiring too much computation, one can work with a relatively larger number of features. This also helps in classification genes and other biological properties of the organism in bioinformatics as they contain mammoth amounts of features which can be computed easily with SVM and Lagrange’s duality.
written by: Aryaman Dubey
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs