
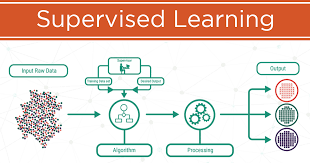
Machine learning is the most emerging field of today’s era. Machine learning is majorly classified into two types one is supervised learning and another one is unsupervised learning. These two are the major categories in which this domain is broadly classified.
Supervised learning is the most and frequent use of machine learning algorithms. This is the most powerful tool to classify and process data with the help of data sets and the dataset is used as the basis of prediction of the classification of another unlabeled dataset.
Basically in this algorithm data is given to the machine to feed it with prior knowledge of the basic example of the function we need and after that machine is provided with a new dataset and taking feedback from the example dataset, it generates the output of the new data.
For example, if I have a basket filled with varieties of candies. Now the first thing is to train it with all varieties of candies one by one like this:
- If the shape of the given object is oblate and the colour is red then it is consider as strawberry candy.
- If the shape of the given object is circular and green in shape then it is an apple candy.

Now after the machine is train with the dataset, if I give a new separate strawberry candy from the basket then the machine will easily identify it as a strawberry candy upon the example dataset which was fed earlier to train it.
Now moving further Supervised learning is broadly classified into further two categories of algorithms namely, classification and regression.

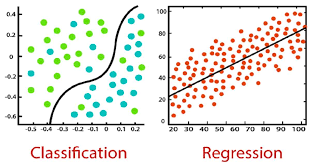
Classification:-
It is one of the types of algorithms of supervised learning. In simple words, it has defined labels or having a discrete value.

Regression:-
It is also one of the types of algorithms of this supervised learning. In simple words, it has undefined labels or continuous. value.
Some other types Of supervised learning classifications are:-
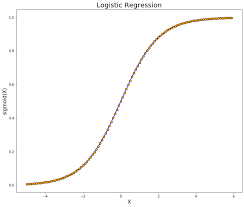
- Logistic regression:- To solve the binary classification problems, logistic regression is one of the most used algorithms. It is one of the simplest and most powerful algorithms.
- Decision trees:- In this algorithm dataset is slice down making questions until they have reach a point to make a prediction through this process.

- Support vector machine:- In this algorithm, it is consider to be an extension of the perceptron algorithm. It can be in use to solve linear as well as nonlinear classification problems. It can separate objects into classes.
Advantages:-
- It allows us to collect data and give a sample dataset for future prediction through algorithms.
- helps to improve the result accuracy with the help of experience.
- It also helps to solve various real-world computational problems easily.
- most often use in learning algorithm of machine learning due to its prediction precision.
Disadvantages :-
- It is very difficult to feed a large set of data earlier to make it give precise predictions.
- takes a lot of time to feed the dataset so it’s really a time- consuming process.
- It is a big challenge to classify huge datasets.
Written By: Anjali Parashar
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs