
We all take photos with our smartphone cameras but often they come out blurry due to various reasons, but what if there was a way to make them clear. That is where super resolutions come in. We will be looking at some Super Resolution frameworks in this blog.
Super Resolution
Super Resolution is a method of retrieving a high-resolution image (HR) from the low-resolution image (LR). We can relate to HR and LR using LR = degrade(HR).
Of course, we get an LR image from the HR image while using a degradation function. But, can we do the other way around? In the best scenario, yes! By applying its reverse to the LR frame, we can recover the HR image if we know the exact degradation function. However, the dilemma is there. Usually, we do not know beforehand about the degradation function. The inverse degradation function is an unstable problem precisely done. Deep learning methods have nonetheless proved influential for Super-Resolution.
 |  |
Using the degrade function on HR image to get LR (Photo by Tim Hüfner on Unsplash)
For this deep learning model, we will be using supervised learning.
Supervised learning
Supervised learning is the task of machine learning to learn a feature that maps an input based on example input-output pairs to an output. It infers a feature consisting of a collection of training examples from labelled training data.
To estimate the high resolution (HR) image given a low resolution (LR) image, deep learning can be used. We may treat this as a supervised learning problem with the use of the HR image as a target (or ground-truth) and the LR image as an input.
We can make our dataset by blurring adding some noise into the HR image to get the LR image.
Researchers have now proposed several super-resolution models of deep learning. These models concentrate on supervised SR, i.e. all LR images and corresponding HR images learned. Although the discrepancies
There are very broad models among these, generally some combinations of a set of components such as model structures, methods of upsampling, network architecture, and learning strategies. From this viewpoint, these components are combine by researchers to create an interactive SR model for specific purposes. In this section, instead of presenting each model in isolation, we focus on modularly evaluating the fundamental components and Summarizing their advantages and limitations.
We will be looking at some of the super-resolution frameworks.
Frameworks
Since the image super-resolution is an ill-advised issue, performing upsampling (i.e. to produce HR output from LR)
Input) is a crucial problem. Although the architectures of current models differ widely. they can be link to four model frameworks, based on the up-sampling operations used and their positions in the model.
1. Pre-upsampling Super-resolution
We use LR images to get HR image, and CNNs are used to do the mapping from the interpolated LR images to HR images. Our intuition is upscaling LR image using interpolation and then direct mapping using CNN layers from low-dimensions to high dimensions. The benefit is that because upsampling is done using conventional techniques, CNN just needs to learn how to refine a larger picture, which is easier.

Pre-upsampling (Source)
2. Post-upsampling Super-resolution
In this, we pass our LR images through the CNNs and the upscaling is done by learnable layer at the end. The advantage of this framework is that complexity is reduced by doing feature extractions in the lower dimensional space.
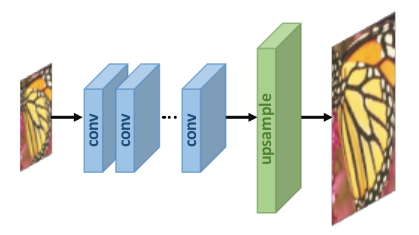
Post-upsampling (Source)
3. Progressive Upsampling Super-resolution
In the above category, while the computational complexity was diminished, only a single upsampling convolution was used. This makes the learning process more difficult with large scaling variables. Works such as Laplacian Pyramid SR Network and Progressive SR (ProSR) have introduced a progressive upsampling system to fix this downside. The models, in this case, use the CNN cascade to gradually recreate high-resolution images with smaller scaling factors at each stage.
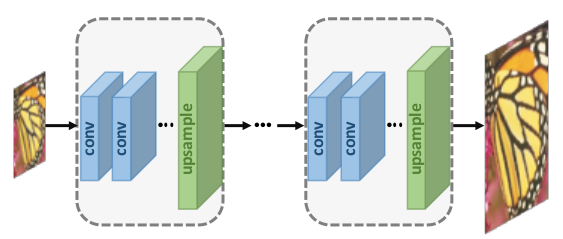
Progressive upsampling (Source)
4. Iterative Up and Down Upsampling Super-resolution
The hourglass (or U-Net) framework is another typical model architecture. Some versions, such as the Stacked Hourglass network, use multiple hourglass systems in succession, essentially switching between upsampling and downsampling. Models within this paradigm will better weaken the profound relationship between LR-HR image pairs and thus have higher-quality reconstruction performance.
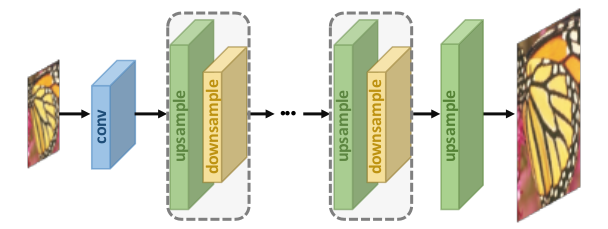
Iterative Up and Down upsampling (Source)
Conclusion | Super Resolution
However, We have looked into four frameworks, and the efficiency is different for each of them as mentioned—each with other pros and cons regarding complexity and time.
Written By: Mrunmay Shelar
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs