
In this post, we tend to usually concentrate on four elementary aspects of regularization in machine learning.
- What is regularization?
- What is regularization used for?
- How will regularization solve the overfitting downside?
Background info concerning Bias and Variance errors to know previous 3 small print.
In this post, these four totally different aspects of the regularization area unit are analyze at a theoretical level, and a general summary of them is introduce.
3 common regularization techniques applies on the way regularization term influences algorithms are to incontestable to supply geometric intuition.
Background Knowledge of Regularization In Machine Learning?
While working a typical machine learning model, what we’ve got an inclination to do and do is to make ground truth labels of the knowledge set and so the predictions of the model for them be as shut as accomplishable to a minimum of each other.
This operation is perform over the loss operation that we incline to choose for our drawback.
it tends to increase the accuracy of the model across work set in conjunction with minimizing bias in total error. The total error created by machine learning model over its oracular capability consists of unit bias, variance, and irreducible error. Bias is public as to what amount the expected price differs from the correct label.
However, this tendency usually results in cubic centimeter models memorizing the pattern. throughout that info set unfold in a multi-dimensional house rather than understanding.
hence, thereby being generalized to that pattern, that’s term overfitting. this will be an undesirable state of affairs as model actually would not learn things from the knowledge.
when we take a glance at it on unseen info sets. it will extraordinarily all be told to fail. Besides, cubic centimeter models yearning overfitting become so advanced, and hence; their variance is maximize on total error.
Variance
Variance is our second term in total error, and it refers to the quantity of the model’s sensitivity to the knowledge set. in several words.
if the performance of a model is unquestionably litter with small changes inside the knowledge set. that model is extraordinarily tailor. This will be foremost reason why overfit models fail in unseen testing sets whereas in the work set.
The figure illustrate below is actually the definition of all explanations given more than to provide insight regarding the context.

What is overfitting?
Overfitting could also be a development that happens once a model learns the detailed Associate in Nursing noise among the employment information to associate degree extent that it negatively impacts the performance of the model on new information.
So the overfitting could also be a significant downside as a result of it negatively impacting the performance.
Regularization technique to the rescue.
Generally, the associate degree honest model does not supply a great deal of weight to a particular feature. The weights unit is equally distribute. This may be achieve by regularization.
There unit two styles of regularization In Machine Learning as follows:
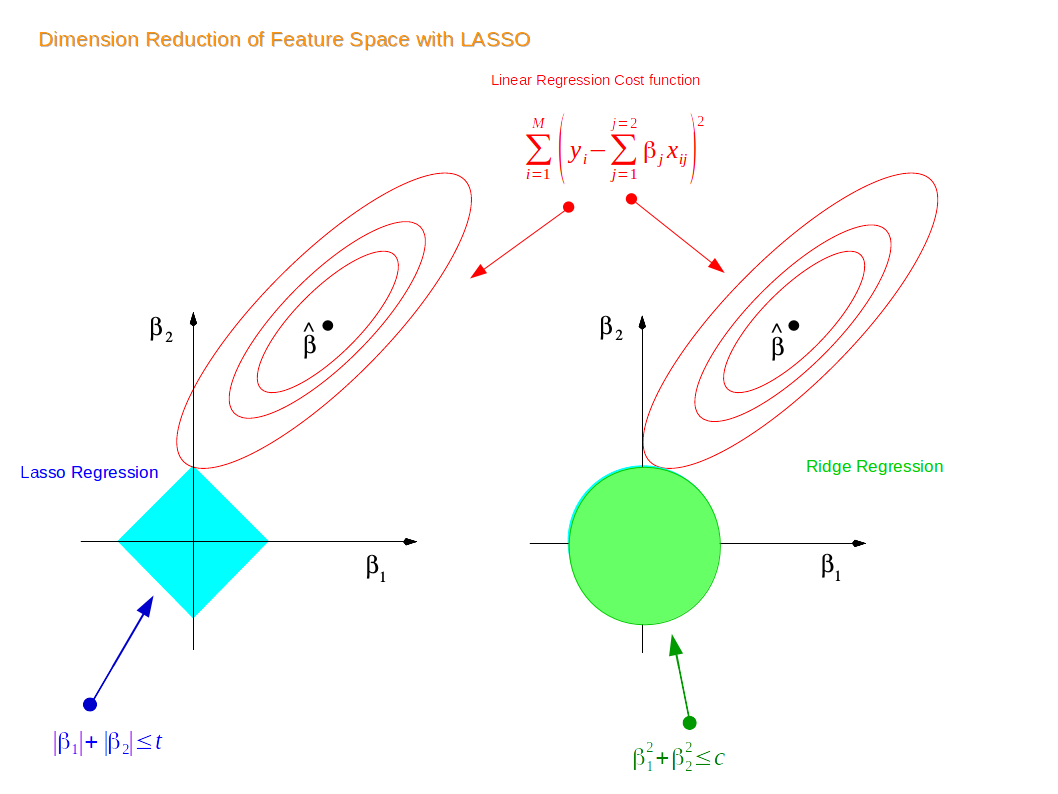
- L1 Regularization or Lasso Regularization
- L2 Regularization or Ridge Regularization
1. L1 Regularization or Lasso Regularization
L1 Regularization or Lasso Regularization adds a penalty to the error operation. The penalty is that the overall of fully the values of weights.

p is that the standardization parameter that decides what proportion we might prefer to penalize the model.
2. L2 Regularization or Ridge Regularization
L2 Regularization or Ridge Regularization to boot adds a penalty to the error operation. but the penalty here is that the overall of the sq. values of weights.

Similar to L1, in L2 also, p is that the standardization parameter that decides what proportion we might prefer to penalize the model.
Challenge in Regularization In Machine Learning
Just like cancer treatment ought to destroy the cancer cells alone and not have an effect on the healthy cells within the body, the regularization approach ought to attack the noise alone and not have an effect on the signal. Intuitively, once a regularization parameter is employed, the training model is forced to decide on solely a restricted set of model parameters.
Instead of selecting parameters from a separate grid, regularization chooses values from a time, thereby disposing of a smoothing result. This smoothing result provided by regularization is what helps the model to capture the signal well (signal is mostly smooth) and filter the noise (noise is rarely smooth) thereby doing the magic of fighting to overfit with success.
What varieties of regularizations square measure out there to use in machine learning?
Two of the normally used techniques square measure L1 or Lasso regularization and L2 or Ridge regularization. Each of these techniques imposes a penalty on the model to attain wetting of the magnitude as mentioned earlier. within the case of L1, the addition of absolutely the values of the weights is obligatory as a penalty whereas, within the case of L2, the addition of the square values of weights is obligatory as a penalty. there’s a hybrid style of regularization known as Elastic web that’s a mixture of L1 and L2.

While optimization algorithms try to reach international minimums on the loss curve, they really decrease the worth of the initial term in those loss functions, that’s a summation half. However, at a similar time, the length of the load vector tends to increase; therefore, the worth of regularization terms rises. optimization algorithms got to produce a balance between summation and regularization terms.
it’s insufferable to decrease the values of each one. The hyper-parameter lambda (λ) is employ to tune balance, and to choose that one is a lot dominant. This balance, in fact, additionally refers to the bias-variance exchange mentioned on top. In alternative words, regularization terms behave like AN handbrake, and since of this.
regularization is additionally capable of shrinking the weights of learning models and thereby reducing instability determine on the model’s thanks to the existence of enormous weights.
this post is why regularization terms don’t have bias (b) parameters, and area units alone outlined on weights. In fact, we can additionally regularize our learning models over bias (b) parameters; there’s no restriction that it’s to conduct on simple weights. However, there’s no would like it.
since learning models usually accommodate a varies with range of weights. thus, regularizing the models over the parameter b can have little or no quantity of contribution to the model compared to its weight vector.
Conclusion
I hope that I might give an informative and helpful context concerning regularization operation. If there’s one thing unclear within the post, you’ll mention it in your comments. the foremost common regularization techniques apply on regression toward the mean and geometric intuition concerning it’ll be line in the next post.
written by: Pramod Panigrahi
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs