
One of the common downside and information science skilled face is to avoid overfitting. Have you ever come across a scenario where your model performs exceptionally well on train information, but wasn’t ready to predict check information otherwise you were on the highest of competition publically leaderboard. Regularization in Machine Learning is a form of regression, that compels or shrinks the coefficient guesses towards zero.
Or only to fall hundreds of places within the final ranking? Well, this text for you. Avoiding overfitting will improve our model’s performance.

What is regularization in Machine Learning?
Before we tend to deep dive into the subject , take a glance at this image.

Have you ever seen this image before? As we tend to move towards the proper during this image our model tries to be told too well the small print and also the noise from the coaching the information , which ultimately ends up in poor performance on the unseen information.
In alternative words whereas going towards the proper ,the quality of the model increases such time coaching error reduces however the testing error doesn’t .
In logistic regression in all {probability|most likely} no sensible distinction whether or not your classifier predict probability .99 or .9999 for a label ,but weights would wish to be abundant larger to succeed in .9999
The quality of options towards rising the loss should outweigh the value of getting massive options weights.
What is generalization | Regularization in Machine Learning ?
Prediction functions that job on the coaching information won’t work on alternative information.
Minimizing the coaching error could be an affordable thing to try to do ,but it’s potential to reduce it to well.
your performance matches the coaching information well however isn’t learning general rules that may work for brand new information this known as over fitting.
How will we outline whether or not weighted squares measure massive ?

This is often known as the L2 variety of w. A norm could be the life of a vector length. Conjointly known as the euclidean type.
New goal of minimization :
d(W,X)+lambda||W||2
This is often no matter loss perform we tend to square measure using(for a knowledge set X) on minimizing this. we like solutions wherever w is nearer to zero.
It eliminates the square root easier to figure scientific discipline calculations. Lambda could be a hypo parameter that changes the trade between having low coaching loss and having low weights.
Overfitting in logistic regression :
Suppose you’re a pursuit engine and you build a classifier. to put down whether or not a user – over the age of sixty-five supported what they need to search-
One person in your information set searched the subsequent typo:
This person was over age sixty five.
Optimizing the logistical regression loss performance, we might learn that anyone UN agency searches sdfgsdg is over sixty-five with likelihood one.
Onerous to conclude abundant from one example. Don’t actually need to classify all people that build this literal within the future this manner .
10 individuals searches following within the term:
All 10 individuals were over age sixty five. Optimizing the logistical regression loss performance , we might learn that anyone UN agency searches this question is over sixty five with likelihood one.
* This question is perhaps smart proof that somebody is older than sixty five.
* Still: what’s somebody who searched this UN agency otherwise had hundreds of questions that steered them were younger?. they might still classified >65 with likelihood one the likelihood one override alternative options in logistic regression .
* Risk of overflowing if weights get overlarge . Recall the logistical functions.

L2 regularization- Machine Learning
When the regularize is the square l2 norm ||w||2 regularization. this is often the foremost common varieties of regularization In Machine Learning.
Once used for simple regression this is – ridge regression. Logistic regression implements typically use l2 regularization by default.
The perform r(w)=||w||2 is biconvex, thus if it’s value-added to biconvex loss performance,the combined performance can still be biconvex.
How to select lambda?
You shall play with it within the school assignment, and that we shall conjointly come back to the current later within the semester once we discuss hyper parameter improvement.
Other common names for lambda:
- Alpha in sklearn.
- C in several algorithms.
- Typically c truly refers to the inverse regularization 1/lambda.
- Make out that one your implementation is using(whether this can increase or decrease regularization).
L1 regularization
Another common regularization in Machine Learning is that the l1 norm:
Biconvex however not differential once wj=0.
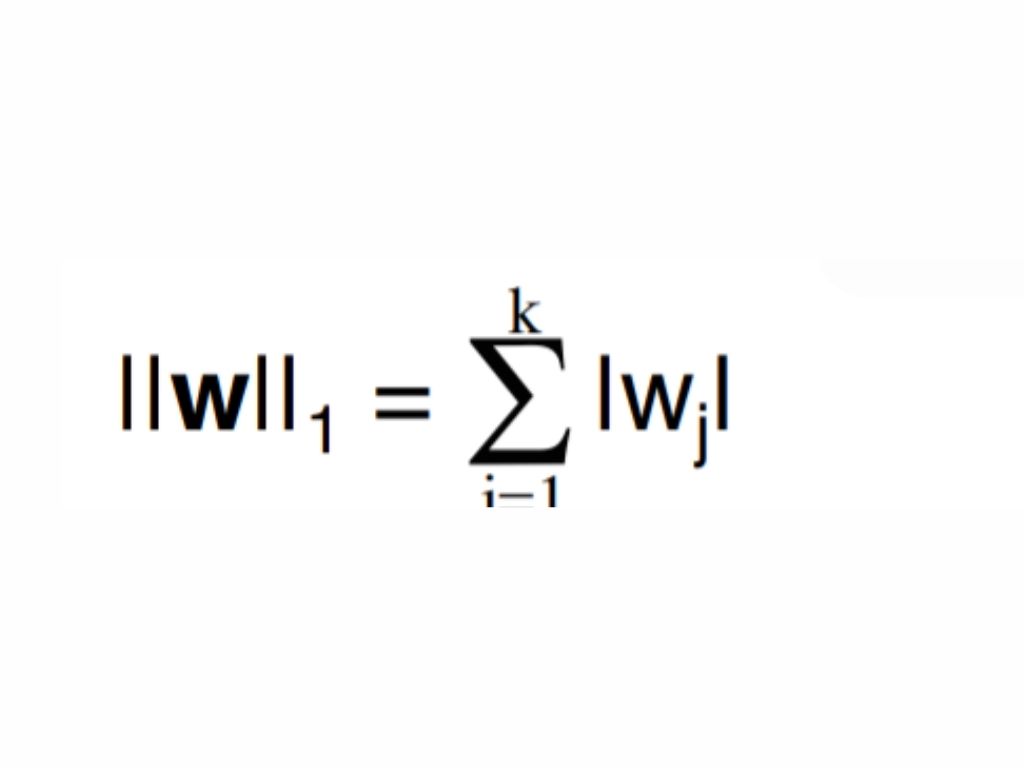
However zero could be a valid sub gradient for gradient descent. Usually ends up in several weighs being specifically zero.
L2 + L1 regularization
L2 and L1 regularization will be combined:
R(w)=lambda1||w||2
Conjointly known as elastic internet. Will work higher than either sort alone.
Will changing hyper parameters to regulate that of the 2 penalties is a lot of necessary.
Feature social control
- the size of options values matters once victimization regularization In Machine Learning.
- If one option has a value between [0,1] and another between [0,10000],the learned weights could be on terribly completely different scales. however, no matter the weights square measure naturally larger square measure planning to get fined a lot by regularization.
- Feature social control or standardization refers to changing the values to be a customary vary.
Bias vs Variance
The goal of machine learning is to learn a performance which will properly predict all information it’d hypothetically encounter within the world. We tend to don’t have access to all or any potential information,so we tend to approximate this by doing well on the coaching information.
After you estimate a parameter from a sample ,the estimate is biased if the expected worth of the parameter is completely different from truth value.
The excepted worth of parameter is that the theoretical average worth of all {different|totally completely different|completely different} parameter you’d get from different samples.
Example: sampling is unbiased as a result of if you recurrent the sampling over and over on the average your answer would be correct(even though every individual sample would possibly give a wrong answer).
The variance of associate estimate refers to what proportion the estimate can vary type sample to sample. if you systematically get a similar parameter estimate despite what coaching sample you utilize ,this parameter has low variance.
Variance is error thanks to randomness however your coaching information was selected. Bias is error thanks to one thing, systematic , not random.
High bias
Can learn similar functions although given completely different coaching examples. Eventually, they at risk of the underneath fitting.
High variance:
The learn functions depend a bit on the precise information employed to coach. Prone is over fitting.
Conclusion:
Regularization is a lot of work. It will build a giant distinction for obtaining smart performance. You always can need to tune the regularization strength after you build a classifier.
Article By: Somay Mangla
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs