

In the terms of Machine Learning , “BACKPROPAGATION” ,is a generally used algorithm in training feedforward neural networks for supervised learning.
What is a feedforward neural network?
- A feedforward neural network is an artificial neural network where interrelation between the nodes do not form a cycle.
- It’s the first artificial neural network.

Consider the above diagram. Hence, In this network, the information moves in only one single direction as shown in the diagram. in the forward direction from the input nodes and then , through the hidden nodes (if there are any hidden nodes present) and then to the output nodes. Therefore, They do not form a cycle or loop in the network when interconnected to the nodes.
Likewise, in a feed forward network, information every time moves only in one direction; that is forward ,it never goes backwards.
Now, I hope now the concept of a feed forward neural network is clear.
Coming back to the topic “BACKPROPAGATION”
So ,the concept of backpropagation exists for other artificial neural networks , and generally for functions . Also, These groups of algorithms are all mentioned as “backpropagation”.
In simple terms “Backpropagation is a supervised learning algorithm, for training Multi-layer Perceptrons (Artificial Neural Networks)”
But, some of you might be thinking about why we need to train a Neural Network? or what exactly is the meaning of training of the Neural Network ?
So, I will be clearing all the questions in this article .I would like to go over the mathematical process of training. I hope this will help the reader understand why we need to train a neural network , how backpropagation works as well as the importance of backpropagation.
What is the Need of Backpropagation?
In the beginning, plotting or designing a Neural Network, we have to initialize the value of the weight of the connections in the network with some random values or any variable.Now obviously as we don’t have any supernatural power. it’s not mandatory that whatever values of weights we have selected will be correct or accurate, or it fits our model the best. So we have selected some values of weight in the starting, but our model output is different from our initial output i.e. the error value is immense
However, the question arises how will you reduce the error?
In addition to this, what we need to do, we need to somehow explain the model to change the parameters (weights values ),to minimize the error .
Let’s understand in another way, we need to train our model. Hence, One way to train our model is known as Backpropagation. Go through the diagram below:

Lastly, Let me sum up all the steps given in the above diagram to make every term clear:-
- Model:- Model on which we will work upon .
- Calculate the error – How far your output of the model is from the actual output?
MAIN STEP TO MINIMIZE THE ERROR :-
- Minimum Error – We have to check whether the error is minimized/decreased or not.
Now,
- Update the parameters – If the error is immense then, change the parameters ( i.e weights and biases) to minimize the error .Okay , After updating the parameters keep on checking the error. Keep on doing the process until the error becomes minimum.
- Now ,Model is ready to make a prediction – Once the error becomes minimum, you can give some inputs to your model and according to the given inputs it will produce the output.
I am sure now you understand ,What is the need for Backpropagation and what is the meaning of training a model by calculating the error then minimize them by updating the parameters .
however, let’s understand what is Backpropagation.
What is Backpropagation?
Firstly, According to the paper from 1989, what is backpropagation?
Backpropagation is defined as continuously adjusting the weights of the connections in the network so as to minimize/decrease a calculation of the difference between the actual output and the desired output.
In other words, backpropagation aims to minimize the cost function (minimize the error) by modifying network’s weights and biases and the level of adjustment is set by the gradients of the cost function with respect to those weights and biases.
The Backpropagation algorithm focuses basically for the minimum error value function in weight and there is a method/technique used called gradient descent.(Now, In simple terms it is used to find the values of a function’s weights and Biases That Minimize A Cost Function In Full Measure).

The weights that minimize the error function is then considered to be a solution to the learning problem.
So now , Let’s understand basically how it works using an example :
EXAMPLE 1:-
Moreover, You have a dataset, which has labels.
Consider the below table :-
| Input | Desired Output |
| 0 | 0 |
| 1 | 2 |
| 2 | 4 |
Now, the output of your model when ‘W” weight value = 3:
| Input | Desired Output | Model output (W=3) |
| 0 | 0 | 0 |
| 1 | 2 | 3 |
| 2 | 4 | 6 |
subsequently, Look at the difference between the actual output and the desired output:
| Input | Desired Output | Model output (W=3) | Absolute Error | Square Error |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 3 | 1 | 1 |
| 2 | 4 | 6 | 2 | 4 |
let’s change the value of ‘W’ weight . Also notice the error when (W = 4)
| Input | Desired Output | Model output (W=3) | Absolute Error | Square Error | Model output (W=4) | Square Error |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 3 | 1 | 1 | 4 | 4 |
| 2 | 4 | 6 | 2 | 4 | 8 | 16 |
Now look when we increase the value of W ,there is the maximum error . So, there is no point in increasing the value of W furthermore . But, think what happens if I decrease the value of W ? Again, Go through the table given below:
| Input | Desired Output | Model output (W=3) | Absolute Error | Square Error | Model output (W=2) | Square Error |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 3 | 2 | 4 | 3 | 0 |
| 2 | 4 | 6 | 2 | 4 | 4 | 0 |
Now, I explain all the steps :-
- So, firstly initialized some random value to W.
- After that we observe that there is some error.
- So, To minimize that error, we layered backwards.
- Increased the value of weight W.
- After that, we noticed that the error has increased.
- So, we again layered backwards and we decreased weight value W.
- finally, we noticed that the error has lowered.
In other words, We are trying to get the weight value in such a manner that error becomes minimum.
Therefore, We have to find out why we need to increase/decrease the weight value. So, we keep on updating the values of weight until the error value becomes minimum.
After, where if you further update the weight value , the error will increase. At that time you need to stop, and that is your final weight value.
so, Go through the graph given below:-

so, From the above graph we conclude that ,
- When the gradient is negative(-), increase in weight decreases the error.
- When the gradient is positive(+), decrease in weight decreases the error.
Hence, To get the global loss minimum we need to update the weights. Also, We need to reach the ‘Global Loss Minimum’.
Hence, This is how back propagation in neural networks works.
To demonstrate all the math, behind Backpropagation let’s understand the topic.
How Backpropagation Works?
The aim of the back propagation algorithm is to enhance the weights so that the neural network can learn how to accurately depict I/O.
So, Consider the blow Neural Network to understand the complete scenario :

The above network contains:
- 2 inputs
- hidden neurons(2)
- 2 output neurons
- biases(2)
Steps involved in Backpropagation:
- Forward Propagation
- Backward Propagation .
- Also, Placing all the respective values together and calculating the updated weight value.
Step – 1: Forward Propagation
The total net input for h1: The net input for h1 is calculated as the sum of the product of each weight value and the corresponding input values and, finally, a bias value sum to it:-

Furthermore, Using the output from the hidden layer neurons as inputs. Also, Repeat this process for the output layer neurons.

So ,let’s see what is the value of the error:
Then, the total error for the neural network is the sum of these errors:
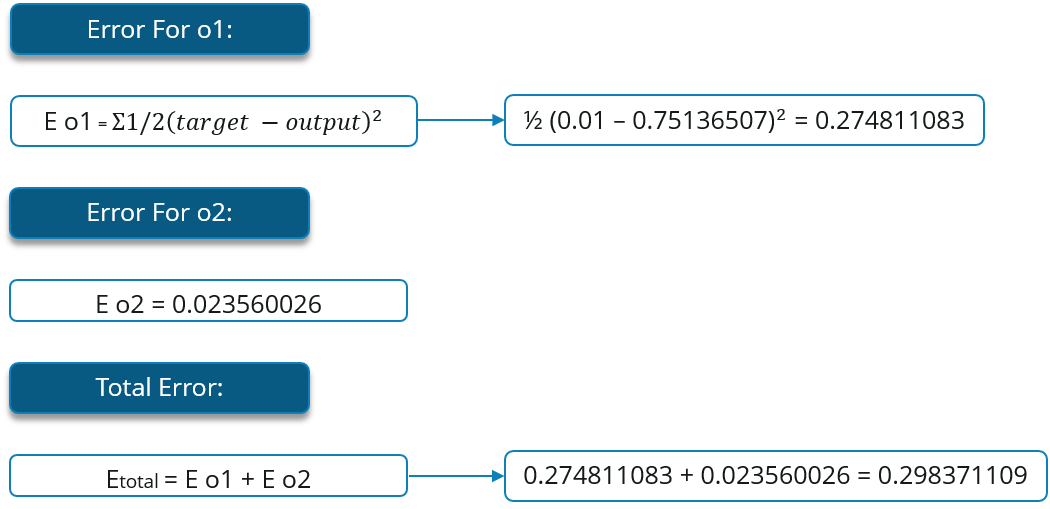
Step – 2: Backward Propagation
So, it’s the time that we will propagate backwards to reduce the error by replacing the values parameters .
Lastly, Consider W5 here, we will calculate the rate of change of error with respect to change in weight value (W5).

Finally, considering we are propagating backwards, the main thing we need to do is, to calculate the change in total errors with respect to the output 1 ( O1 )and output 2 (O2)
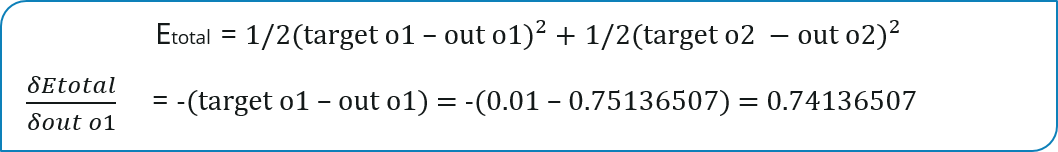

In fact see how much the total net input of O1 changes with respect to weight W5?

Step – 3: Placing all the values together and calculating the updated weight value
finally, put all the values together, sum up them :

Then calculate the upgrade/updated value of W5:

- In the similar way , we can calculate the other given weight values furthermore.
- Secondly, We will again propagate forward and calculate the desired output.
- Again, we will calculate the error., and if the error is minimum we will stop otherwise we will again propagate backwards and update the weight values.
- This procedure will keep on repeating again and again until error becomes minimum.
Backpropagation Algorithm:
Although, A major mathematical tool for making superior and high accuracy predictions in machine learning.
Though, supervised learning methods for training Artificial Neural Networks are used in this algorithm.
Besides that, The entire idea of training multi-layer perceptrons is to calculate the derivatives of the error function towards weights using the backpropagation algorithm.
Conclusion:
Finally, I hope this blog gave you a meaningful and clear understanding of these commonly used terms. Subsequently their use/roles in a better understanding of neutral networks , backpropagation and its working and importance and terms related to machine learning . also, HAPPY LEARNING:-)
article by: Shivangi Pandey
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs