
What is a Recommender system?
Many of you might have used e-commerce sites like amazon, flipkart etc. and there you may have seen recommender systems working. Or you might see something like “Recommended songs” on your Spotify app. Or for that matter the advertisements you see while surfing on Facebook or your Instagram feed. so, How does the system “recommend” something to you?
The short answer is that when we login to the system, the system recommends certain items to us based on browsing history or cookies. A recommender system looks at the past behaviour of the users and the other data it has. thus, This recommender system has been the source of revenue of all the big tech giants you see nowadays, from Google to Facebook.
So much so that they are able to even influence the elections, the US election of 2016 is the best and recent example. But how does this system work? then, Before diving into the world of the recommender system let us look at some terminologies.
so, Let us now formally define a recommender system.
types of recommending methods
1. Item recommendation:
In this recommender system, based on the past history of this user or however other user or maybe the type of content, the Recommender System recommends a list of items to the user which the user is likely to purchase or likely to consume.
2. Rating Prediction System:
As an example, consider the rating movies by the users. The scale of users rating the movies is from 1 to 5. Total number of movies is very large and thus the user rates only some of the movies. The objective in this case is to predict that given a new movie, what rating will be given by the user to the new movie. This is an example of a rating prediction system.
Both of these are used to decide whether a person will go and watch a movie, buy or read a book, etc.
therefore, We are familiar with search. In search the user is looking for something and to find the desired result, he/she gives a query and the system outputs the result as required. The user is trying to pull some information from the system. On the other hand Recommender System is a push system, that is where the system pushes the items to the user, based on the user’s history.
Let
- U be the set of users,
- S be the set of items,
- P be a utility function that finds out the rating of the user for an item.
P: U×SR
That is P is a function from U ‘cross’ S to a real number (rating). Our objective is to learn P from data. The training data is the ratings given by the user in the past for a particular movie. This will be used in the rating prediction problem. The same will apply for users on social media websites, thus wherein the browsing history of the user will be captured. Using P, we can predict the utility value of each item to each user.
There are 2 broad types of recommendation system.
1. Content Based Recommendation Systems:
In this system, the rating prediction is based on the content of the current item and the content of the previous items that the user recommended or liked. So based on the similarity of the content of those items we can try to predict whether the new item will be liked by the user or not. So if Netflix recommends me a movie, it checks my profile, finds out certain features about the movies I like, for example the genre, who was the director, who were actors and then creates a recommendation list.
2. Collaborative Clustering/Filtering Based Recommendation System:
In this system, in order to predict movies for the user, the system looks at what similar users liked. The system then looks at the ratings of these similar users and using them, it predicts the rating of current users
thus, The method of finding similar users is done with the concept of instance based learning or K nearest neighbour. We first construct our data which is a matrix where the different items S1, S2, S3, S4,…….,Sn are the
columns and U1, U2, U3,……,Um are the different users.
| S1 | S2 | S3 | S4 | …… | Sn | |
| U1 | 5 | — | — | 2.5 | 3 | |
| U2 | 3 | 4 | — | — | 4 | |
| U3 | — | — | 2 | — | — | |
| .. | ||||||
| Um | 2.5 | 3.5 | — | — | — |
TABLE (MATRIX) OF DIFFERENT ITEMS VS DIFFERENT USERS
We see that a particular user may have rated some movies and have not rated some of the movies. Like user U1 has rated movies S1 and S4 but not others.
so, Our aim is that given a user item pair, consisting of a movie which the user has not rated, we will predict the rating that will be given by the user.
Let us consider U3 and U2 to be similar. Thus we can predict that the pair U2,S3 will have a similar value as compared to U3,S3 (because U3 and U2 are similar).
Types of Collaborative Filtering
Collaborative filtering methods are of 2 types ;
- User based nearest neighbour: In user based nearest neighbours, given a user, finds a similar user and then prediction is made(Movie example discussed above).
- Item based nearest neighbour: In item based methods, the different items are compared; so similarity between items are obtained by looking at, how the users have rated for the item, who are the users who have rated. For example if there are two items which users have rated in a similar way, then those items are considered to be similar. This is a different from content based similarity of items. In the above matrix, we can compare the vectors column wise and then find items similarity in pairs.
| S1 | S2 | S3 | S4 | …… | Sn | |
| U1 | 5 | — | — | 2.5 | 3 | |
| U2 | 3 | 4 | — | — | 4 | |
| U3 | — | — | 2 | — | — | |
| .. | ||||||
| Um | 8 | 9 | — | — | — |
Pairwise item similarity
We can use it for recommendation in this way; for a user we look at those items the user has liked and find out items which are similar to these items.
Mathematical treatment of User based Nearest neighbour
PHASE 1: Neighbourhood formation Phase.
Suppose the record of the target user is U. The target user U is represented by a vector, and this vector is the rating the user gave (in the matrix (S,U)) to the items. So the user U2 is nothing but the entire second row of the matrix. Thus <3,4,…..,4> represents U2. And, we find the similarity between the target user u and potential neighbour v, by using some similarity measure. A popular similarity measure is Pearson’s Correlation Coefficient, given by:
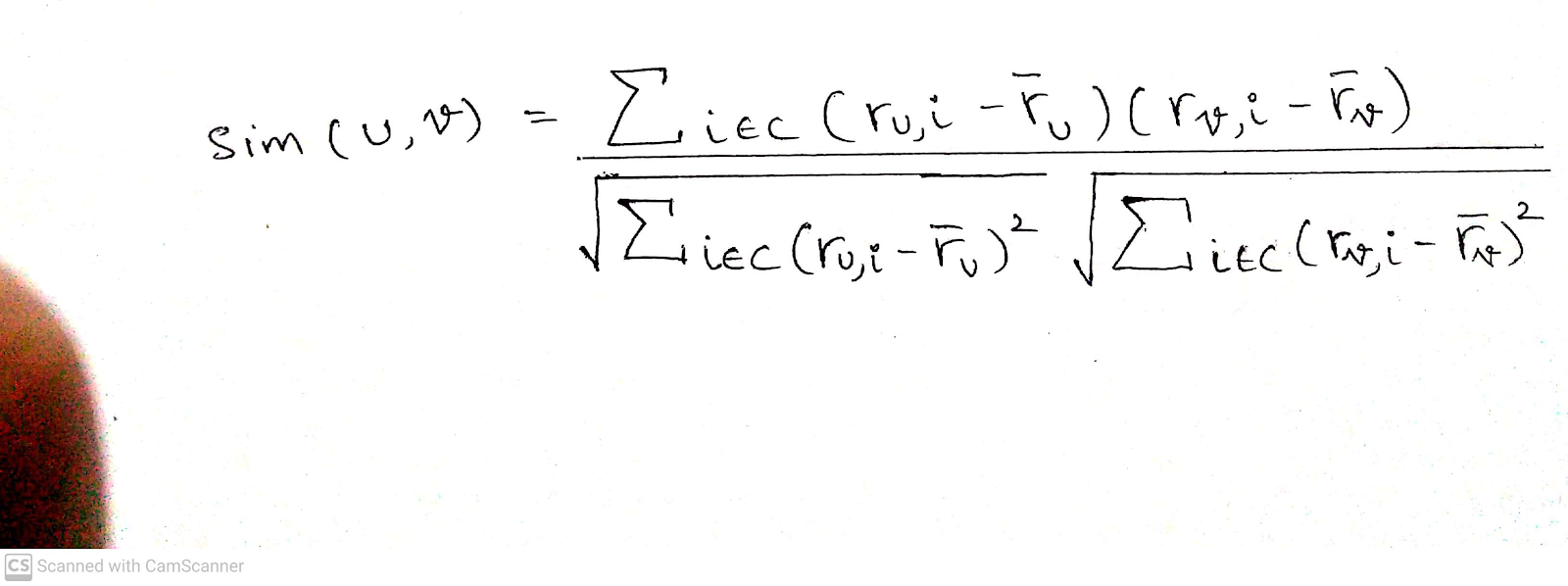
sim(u,v)= …..1
In the numerator we have
- summation over all items,
- ru,i is the rating of u for item i minus the average rating(r with a bar on top) of the user for an item.
- rv,i is the rating of user v for item i minus the average rating of the user v.
Why is there the average value of ru, rv in this equation?
Different users have different standards for rating. There are some users who are reluctant to give a 5. That is, their marking may be strict even though the movie may be an oscar winning! Others may be more liberal and may give a full 5 even though the movie may not be upto the mark. So to normalise the different standards set by different users, we use the average value to check how much the above is the rating of the movie from the average. The summation is done over all items.
In the denominator we have also an expression involving average value of ru,rv.
It incorporates the deviation from the average value. It is also a normalising factor.
This method is used to score the similarity between 2 users ‘u’ and ‘v’. After the similarity of u with all the users has been computed, we find the k-nearest neighbours, that is k most similar users according to formula 1.
PHASE 2: Recommendation Phase.
In the recommendation phase, we use the ratings of those similar users on the test item to recommend the item to the user.
So for this, in the recommendation phase we use the following formula to compute the rating prediction of items i for target user u. Thus;
P(u,i)= v V sim (u , v) (rv,i – r) v V sim (u , v) …2
Where, p(u,i) is the predicted rating of user u for item i for target user u.
It is equal to the average rating of the user (r with a bar). We want to predict whether it will be below average, or how much will it exceed or be different from the average. So this is computed as sigma v ∈ V. V is the set of nearest neighbours and sim(u,v) is as we computed in the previous phase. So for a user v, which is similar to user u, we look at the rating of v for i minus the average rating of the user. Thus if the rating item i for user v and greater than the average rating of that user, we get a positive value of the expression, otherwise it is negative.
Intuitively suppose we have a user who is our target user and i is our target item.
(0.3=) V2 U V1 (= 0.6)
V3 (=0.25)
We find the neighbours, let us say v1 ,v2, v3 and they are the most similar users and with each of them we have value (as indicated in parentheses). Then we look at the prediction of the user v1 for item i and we weight that by 0.6 by the similarity of v1 with u. Similarly we look at the rating of v2 for item i weighted 0.3 and same for v3. To overcome the bias factor because different users have different standards of rating, everything we are doing in terms of average.
In denominator, we have for all the nearest neighbours the summation of similarities.
Mathematical Treatment: Item Based Collaborative filtering
The problem of user based collaborative filtering is the lack of scalability. If there are many users on popular sites like Amazon, Netflix or spotify, it is not possible in real time to find the most similar users because algorithms like instance based are lazy and without the use of good data structures it is not at all efficient.
An alternative to this is item based collaborative filtering. If there are 2 items i, j the similarity is given by:-
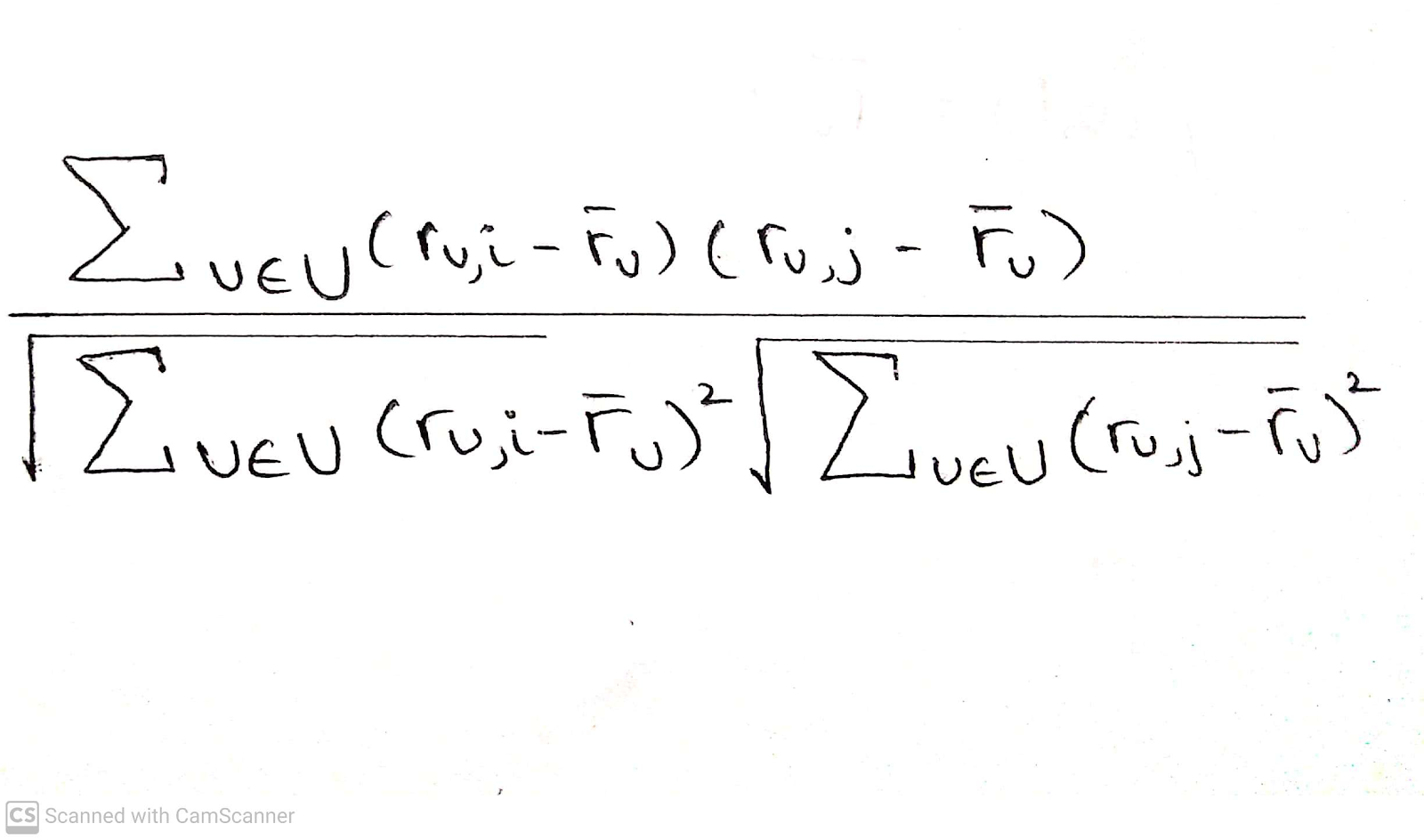
sim(i,j)=
…3
The above formula is very similar to the user based nearest neighbour.
Recommendation Phase:-
In the recommendation phase,we select the set of k most similar items to the target items.
i2 i i1
i3
So for the target item i we find the k most similar neighbours by formula 3 and then based on that we make prediction (similar to that in user based):-
P(u,i)= jJru, j sim (i , j) j Jsim (i , j)
Where J is the set of k similar items.
So this is how recommendation/suggestion is done by the tech giants. Collaborative filtering and recommendation system is an application of K-nearest neighbours. Both the types of filtering (user and item based ) have their importance in the industry and both are equally popular. Thus next time you see your recommendation feed, thank machine learning.
written by: Aryaman Dubey
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs