
What is Naive Bayes?
Naive Bayes algorithm is not just a single classification algorithm but a group of algorithms. These groups of algorithms share the same set of properties.
This algorithm is easy to build and is useful for handling large datasets.
The classification technique in the Naive Bayes algorithm is based on Bayes theorem. The model is built upon a naive interpretation of Bayesian statistics. Naive Bayes is most commonly used for text classification and categorical data models.
Why is it called Naive?
This algorithm is called naive because it works on an assumption that all the features are independent of each other. However, we are pretty sure that the independence of the features might not be common in real-world problems.
Bayes Theorem
Bayes theorem is a simple mathematical formula used for calculating conditional probability when certain other probabilities are known to us. A conditional probability is a probability of occurrence of an event when any other related event has already occurred. In other words, we can say conditional probability helps us finding posterior probability.
Bayes Theorem is formulated as:
P(A|B) = (P(B|A)*P(B)) / P(A)
In this equation, A and B can be consider as target and feature variables respectively.
Where:
P(A|B): Probability of occurrence of A when B has already occurred.
P(B|A): Probability of B given A.
P(A): Prior probability of A.
P(B): Prior probability of B.
Types of Naive Bayes Classifiers
The three popular Naive Bayes Classifiers are:
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Bernoulli.
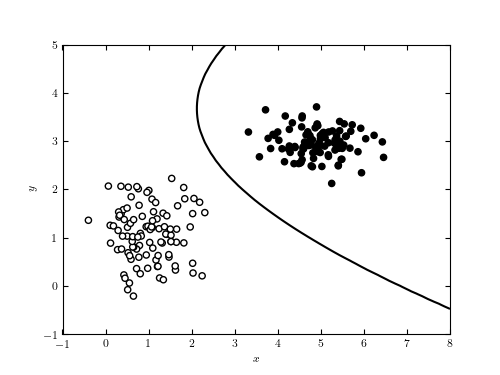
Gaussian Naive Bayes

(https://www.astroml.org/_images/fig_simple_naivebayes_1.png)
{kind=link}
Gaussian Naive Bayes assumes features to be continuous or real-value and is in use for normally distribute data. It calculates for each feature, the mean and standard deviation of the feature value for each class. For prediction, the classifier compares the features of the example data point predicts with the feature statistics of each class and selects the class that best matches the data point.
Multinomial Naive Bayes
This method is used for discrete counts. It is used for multinomially distributed data. This method best suits for classification problems based on text. For example classifying news like sports, politics, business, etc. based on the frequency of certain words present in it.
Bernoulli Naive Bayes
This is a binomial model and is in use if the feature vectors are binary. This is similar to the Multinomial Naive Bayes classifier but the output class is boolean i.e. true or false. For example, it is in use to predict if a certain word is present in a text or not.
Text Classification with Naive Bayes
Text data can comprise of anything whether it is a phrase, a sentence, a paragraph, or a complete document with multiple paragraphs. These textual data can obtains from corpora, blogs, or anywhere from the web browser. For building a text classification system, we need to make sure we have our source of data and retrieve that data so that we can start feeding it to our system.
Text classification includes certain steps that are:
- Prepare train and test datasets
- Text normalization
- Feature extraction
- Model training
- prediction of Model and evaluation
- Model deployment
Training, tuning, and building models are an important part of the whole analytics lifecycle, but even more important is knowing how well these models are performing. The performance of classification models is usually based on how well they predict outcomes for new data points. Usually, this performance is measure against a test or holdout dataset that consists of data points that were not use to influence or train the classifier in any way. This test dataset
usually has several observations and corresponding labels. We extract features in the same way as it follows when training the model. These features were fed to the already trained model, and we obtain predictions for each data point. These predictions are then matches with the actual labels to see how well or how accurately the model has predicted.
For evaluating these classification models a number of evaluation metrics. thus, some of which are:
- Accuracy
- Precision
- Recall
- F1 score
Example of Spam Detection with Naive Bayes
Now we will be using the Naive Bayes classifier to classify emails as spam and ham. This dataset is available on Kaggle.
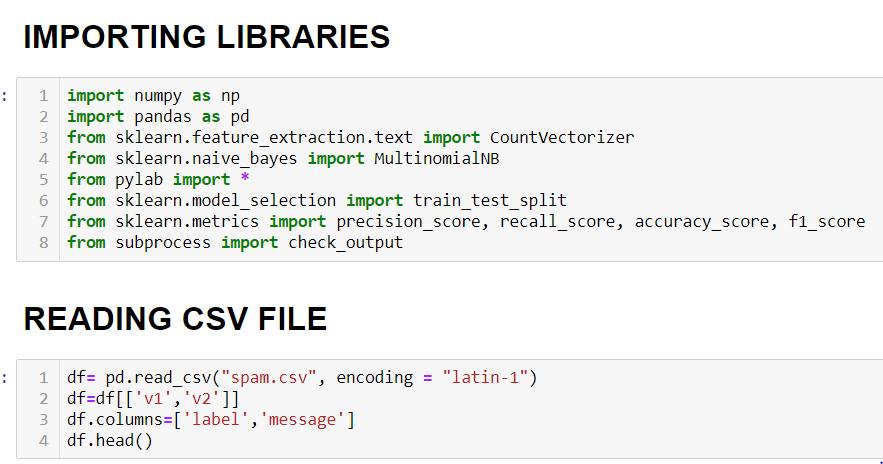
First, we will import the necessary libraries and load the dataset from the CSV file. Here the dataset is load up in a variable – ‘df’. We are using the first two columns of the dataset and we have set the column names as ‘labels’ and ‘messages’
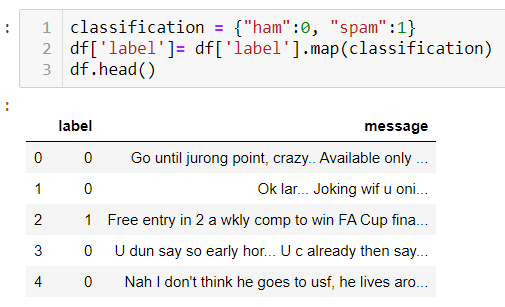
Then we have encoded the categorical variables in numeric values.
Now at last we will be training the model and test it to measure the performance of the model.
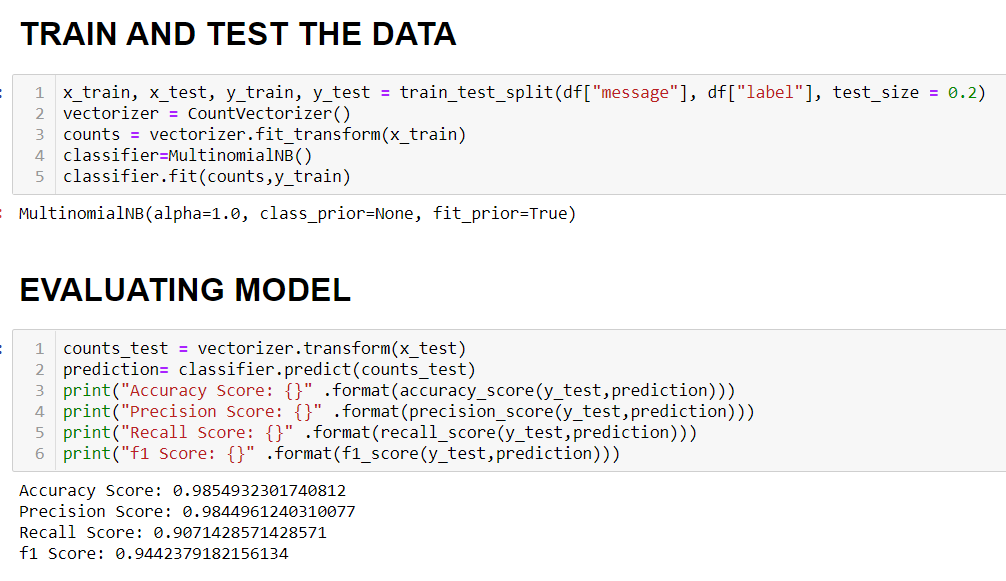
For evaluation, we have used all the metrics that we have named above. We are getting an accuracy of 98.5% on the test data.
Advantages of Naive Bayes Classifier
- It is a simple algorithm and is very easy to implement.
- also, It is fast and can handle large data especially multi-dimensional.
- It can handle continuous as well as discrete data.
Disadvantages of Naive Bayes Classifier
- It assumes all features are independent, which is very rare in real-life problems.
Written By: Chaitanya Virmani
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs