
To build a perfect Machine Learning Project, there are certain steps that every data science aspirant should follow. These several steps combine to form a cycle called the Machine Learning Project Life Cycle or Data Science Project Life cycle. In this article, I will be discussing the various steps involved in Machine Learning Projects. The different steps involved will be explained by using a sample dataset in my next blog.
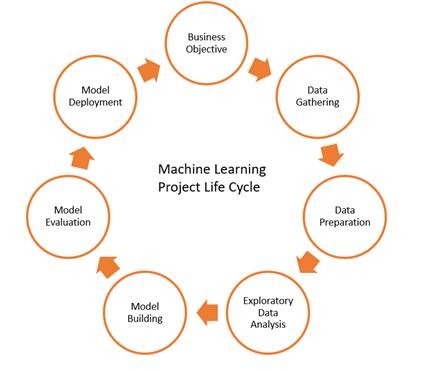
The above figure represents all the steps involved in the ML life cycle required for the successful development and implementation of ML models. It is a cyclical process because the process is continuous and repetitive sequentially follow one step after another step.
I will discuss here each of the following steps one by one in detail.
1. Business Objective/Problem Statement
The first step of every Machine Learning Project is to know and understand the business objective. If business requirements are not clear, it will be futile to go for further steps. Understanding business needs and knowing the customers (end users) is essential to build an accurate model
2. Data Gathering/Acquisition
Data is like fuel for a machine learning algorithm. thus, it may collect from different sources but we need to make sure that we collect correct data relevant to the business need. The data sources can be e-Commerce websites, social media, databases (MySQL, Oracle, DB2, and many others), etc. It is very important to identify Independent variables (x or Input variables) and Dependent variable (Y or Output variable) based on the business needs and to collect data accordingly.
The following are the steps involve in data collection
- Identify different sources
- Extract data from different sources
- Integrate data from different sources to form a dataset required to train a model.
3. Data Preparation
Once the data is collected, it is very essential to clean and pre-process the data to get accurate results from our model. Converting raw data into a usable format is the basis of this step. It involves:
- Missing value treatment,
- Checking out improper data type or invalid data,
- Examining null values.
- Eliminating duplicate records
4. Exploratory Data Analysis (EDA)
In this step, we explore the data deeper for better understanding the data so that insight can be generate so that questions we have in mind can be addressed. We understand how data is distribute, visualize data, identify outliers if any, treat those outliers with different techniques, and analyze the patterns in the data. Different plots like histogram, box plot, scatterplot help to visualize the data.
The following are the steps require in EDA:-
- Visualization
- Statistical Analysis
- Outlier Treatment
- Data Transformation
- Feature Selection
- Creation of Dummy Variables
- Data Partitioning
- Balancing Imbalanced Datasets
The detailed explanation of all EDA steps is beyond the scope of this article. You will be clearer when I will perform the above-mentioned steps with a sample dataset in my next blog.
5. Model Building
Using various machine learning algorithms (regression or classification), a training dataset prepare in the above steps is use to train the model. This is complete so that the model can understand different patterns and relationships in the datasets.
6. Model Evaluation
Once the model is trained, it is very much require to analyze the performance and accuracy of the model. The main goal of any machine learning project is to achieve maximum model accuracy. If the model fails to classify or predict the output correctly, then that particular model is not consider the best model. so, The test dataset is use to analyze the model performance and accuracy.
There are however various evaluation measures criteria (RMSE, Accuracy Score, Precision, Recall, F1 Score, ROC curve, etc.) based on which the best model is selected. Moreover, overfitting and underfitting problems are address so that the model performs well with new data.
7. Model Deployment
Based on the performance of the models, the best model is chosen. The functionality and output of the models should be accessed by the end-users. so, Based on the requirement and business objectives deployment phase should be easy or complex. But we have to make sure that it meets the business objective in terms of minimum accuracy and speed.
The Model build is generally a Blackbox. so, No one closely knows the math behind the model. To communicate the results to the end-user, you thus need to deploy the model in the web servers by generating different web services (flask, AWS, Azure, etc.).
The above-mentioned steps are followed sequentially while developing the ML model. though I will explain all the steps using a sample dataset in my next article.
Thank you, guys, for reading the above Machine Learning Project. so, Feel free to post your queries, suggestions, and feedback.
written by: Nabanita Paul
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs