
Time series Forecasting model over the years is decide on victimization individual statistics via native models. It’s conjointly supported by the rise of temporal information availability, that LED to several deep learning-based statistic algorithms. Thanks to their natural temporal ordering,
time-series information square measure gift in each task that’s taking account of the character of ordering. From electronic health records and act recognition acoustic scene classification and cyber-security. statistics is encounter in several real-world applications.
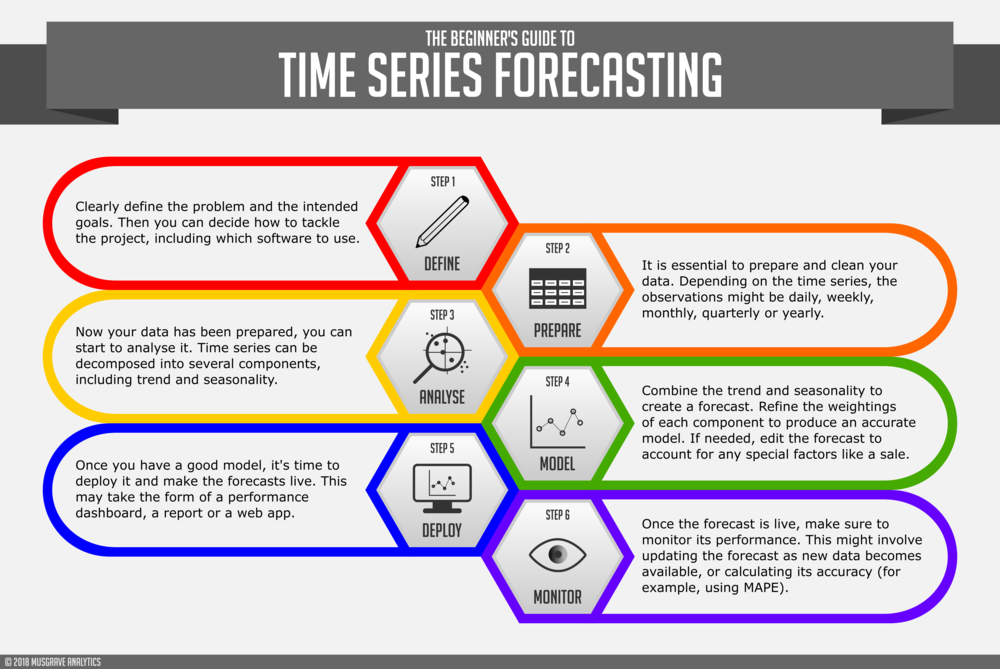
Introduction to Time Series Forecasting

https://i.ytimg.com/vi/wqQKFu41FIw/maxresdefault.jpg
{kind=link}
A statistic can be a sequence S of historical measurements y(t) of associate evident variable y at equal time intervals. statistical square measure measure for many functions like the prediction of the long run support information.
the understanding of the development underlying the measures, or just a compendious description of the salient options of the series. prediction future values of associate discover statistic plays a very important role in nearly all fields of science and engineering, like political economy, finance, business intelligence, meteorology and telecommunication etc.
If the ballroom dance prediction of a statistic is already a difficult task, activity multi-step prediction is harder thanks to extra complications, like accumulation of errors, reduced accuracy, and augmented uncertainty. The prediction domain has been influence, for a protract time, by linear applied mathematics strategies like ARIMA models.
Time Series Forecasting in Last years
within the last twenty years, machine learning models have drawn attention and have establish themselves as serious contenders to classical applied mathematics models within the prediction community. These models are the black-box or data-driven models, square measure samples of statistic nonlinear models that use solely historical information to find out the random dependency between the past and also the future.
As an example, Werbos found that Artificial Neural Networks (ANNs) surpass the classical applied mathematics strategies like statistical regression and BoxJenkins approaches. An analogous study has been conduct by Lapedes and Farber World Health Organization conclude that ANNs will be use for modeling and prediction nonlinear statistics. Later, alternative models appeared like call trees, support vector machines and nearest neighbor regression.
Moreover, the empirical accuracy of many machine learning models has been explore during a range of prediction competitions underneath totally different information conditions (e.g. the NN3, NN5, and also the annual ESTSP competitions) making attention-grabbing scientific debates within the space of information mining and prediction.
Forecasting and Modelling
{kind=link}
Two main interpretations of the prediction drawback on the premise of historical dataset exist. applied mathematics prediction theory assumes that an associate discovered sequence could be a specific realization of a random method, wherever the randomness arises from several freelance degrees of freedom interacting linearly.
However, the nascent read in self-propelling systems theory is that apparently random behavior could also be generated by settled systems with solely a little range of degrees of freedom, interacting nonlinearly. This difficult and non oscillatory behavior is additionally refer to as settle chaos.
we have a tendency to adopt the operating hypothesis that several categories of experimental statistics can also be analyze among the framework of a self-propelling systems approach. so the statistic is understood because the evident of a phase {space} whose state s evolves during a state space area area g, in keeping with the law
s(t) = F^t(s(0))
where F : Γ → Γ is that the map representing the dynamics, foot is its iterated versions and s(t) ∈ Γ denotes the worth of the state at time t.
In the absence of noise the statistic is expound to the phase space by the relation
y(t) = G(s(t))
where G : Γ → D is termed the measuring operator and D is that the dimension of the series. within the following we’ll limit to the case D =1(univariate time series).
Both the operate F and G square measure unknown, therefore normally we have a tendency to cannot hope to reconstruct the state in its original kind.. However, we have a tendency to also be ready to recreate a state area that’s in some sense cherishes the initial.
The state area reconstruction drawback consists in reconstructing the state once the sole obtainable info is contain within the sequence of observations y(t). State area reconstruction introduce into self-propelling systems theory severally by Packard et al. and Takens. The Takens theorem implies that for a good category of settled systems, there exists a mapping (delay reconstruction map) Φ : Γ → n.
Φ(s(t)) = {G(F−d(s(t))),…, G(F−d−n+1(s(t)))} = {y(t)−d,…,y(t)−d−n+1}
between a finite window of the statistic (embedding vector ) and also the state of the dynamic system underlying the series, wherever d is term the lag time and n (order ) is that the range of past values. Takens showed that generically Φ is associated embedding once n ≥ 2g + one, wherever embedding stays for a sleek matched differential mapping with a sleek inverse [17]. The most consequence is that, if Φ is associate embedding then a sleek dynamics f : n → is evoke within the area of reconstruct vectors.
y(t)= f(y(t)−d, y(t)−d−1,…,y(t)−d−n+1)
This implies that the reconstructed states will be wont to estimate f and consequently f will be employed in different to F and G, for any purpose regarding statistical analysis, qualitative description, prediction, etc.
The illustration on top of doesn’t take into consideration any noise element, since it assumes that a settled method f will accurately describe the statistic. Note, however, that this can be merely one doable approach of representing the statistical development which any various illustrations mustn’t be discarded a priori. In fact, once we have a tendency to assume that we’ve got not access to associate degree correct model of the perform f, it’s absolutely cheap to increase the settled formulation of on top of equation to a applied math nonlinear automobile Regressive (NAR) formulation
y(t) = f (y(t)−d, y(t)−d−1,…,y(t)−d−n+1) + w(t))
where the missing info is lump into a noise term w.
The success of a reconstruction approach ranging from a group of ascertained information depends on the selection of the hypothesis that approximates f, the selection of the order n and also the lag time d.
Machine Learning Approaches to Model Time Dependencies

https://miro.medium.com/max/4648/1*ScwIEwLmXPFhBP46QMpy_A.png
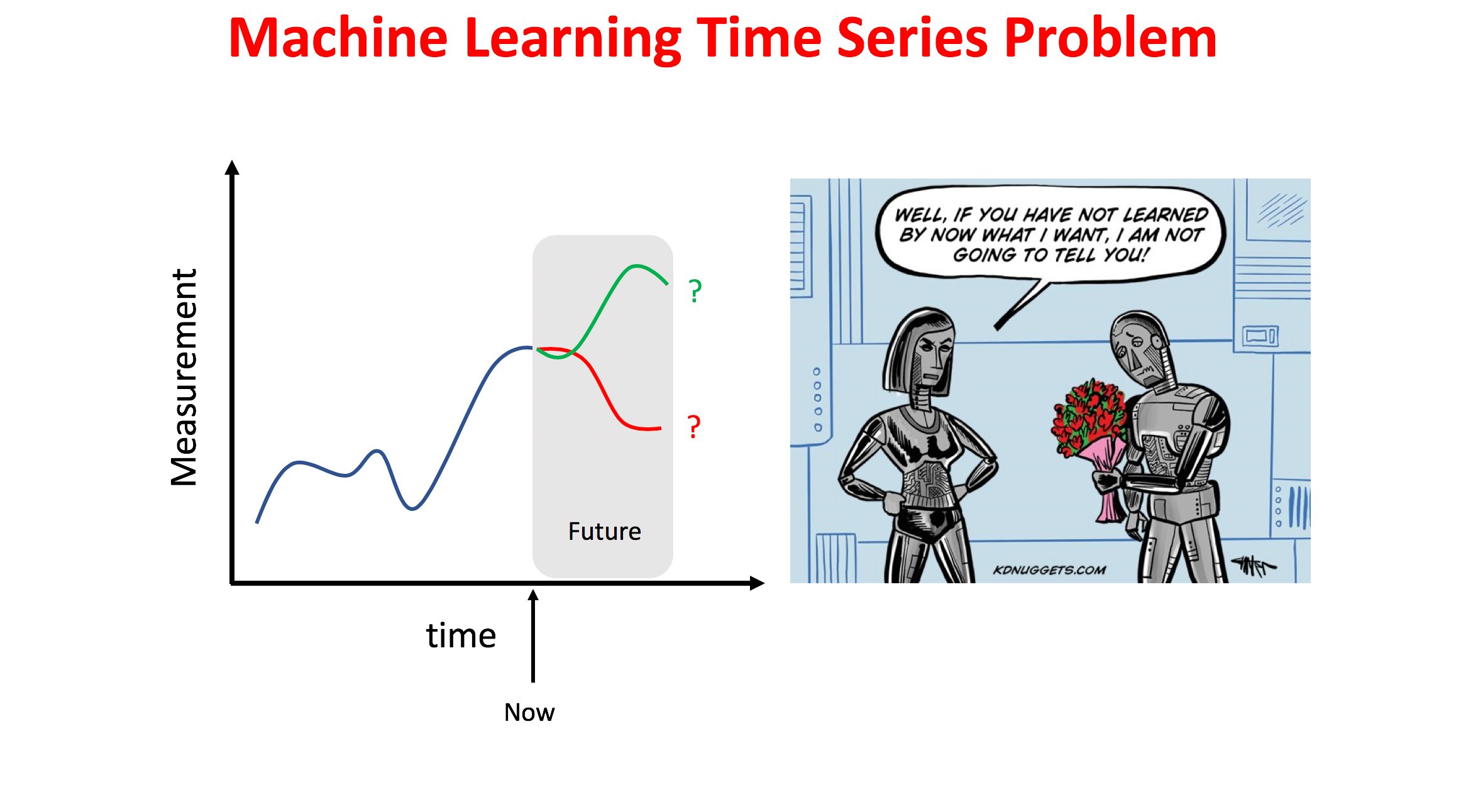{kind=link}
1) Supervised Learning
Supervised learning consists in modeling, on the idea of a finite set of observations, the relation between a collection of input variables and one or additional output variables, that area unit thought-about somewhat passionate about the inputs. Once a model of the mapping is out there, it may be used for ballroom dance prognostication. In ballroom dance prognostication, the n previous values of the series area unit offer and therefore the prognostication downside may be solid within the type of a generic regression downside as shown in figure below.
The final approach to model associate input/output development, with a scalar output and a vectorial input, depends on the supply of a set of ascertained pairs usually spoken as a coaching set. Within the prognostication setting, the coaching set springs by the historical series S by making the [(N − n − 1) × n] computer file matrix.
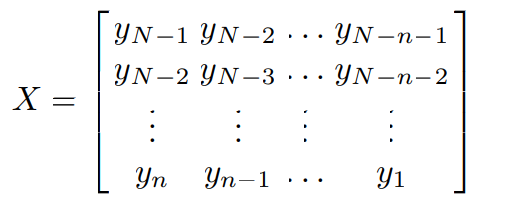

Fig. One-step forecasting. The approximator fˆ returns the prediction of the value of the time series at time t + 1 as a function of the n previous values (the rectangular box containing z−1 represents a unit delay operator, i.e., y(t)−1 = z^−1 y(t)). and the [(N − n − 1) × 1] output vector
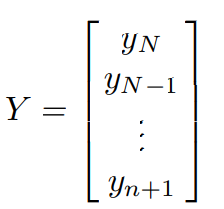
For the sake of simplicity, we tend to assume here a d = zero lag time. Henceforth, during this chapter we’ll sit down with the i th row of X, that is basically a temporal pattern of the series, on the (reconstructed) state of the series at time t − i + one.
Strategies for Multi-step Time Series Forecasting
A multi-step statistic prognostication task consists of predicting consequent H values [yN+1,…,yN+H] of a historical statistic [y1,…,yN ] composed of N observations, wherever H > one denotes the prognostication horizon.
1) Recursive Strategy
The algorithmic strategy trains initial a ballroom dance model f
y(t)+1 = f(y(t),…,y(t)−n+1) + w(t)+1
with t ∈ and so uses it recursively for returning a multistep prediction.
A well known downside of the algorithmic technique is its sensitivity to the estimation error, since calculable values, rather than actual ones, are a lot of and a lot of used once we get more within the future.
In spite of those limitations, the algorithmic strategy has been with success accustomed to forecast several real-world statistics by mistreatment of completely different machine learning models, like repeated neural networks and nearest-neighbors.
Conclusion
Predicting the long run is one in all the foremost relevant and difficult tasks in applied sciences. Building effective predictors from historical knowledge demands machine and applied mathematics ways for inferring dependencies between past and short future values of ascertained values still as acceptable methods to trot out longer horizons. . particularly we have a tendency to stressed the role compete by native learning approximators in addressing vital problems in prognostication, like nonlinearity, nonstationarity and error accumulation. Future analysis ought to be troubled with the extension of those techniques to some recent directions in business intelligence, just like the parallel mining of big amounts of information and therefore the application to spatiotemporal tasks.
Written By: Saurav Majumder
Reviewed By: Shivani Yadav
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs