
When getting started with machine learning, one of the most common and simplest kinds of supervised models you will come across are linear models. Linear Regression is one of the most well-known algorithms in machine learning, generally used for the prediction of continuous variables. However, Linear Regression in itself does not possess enough potency to handle certain tasks. Consequently, we will discuss Ridge Regression, Lasso Regression, and Elastic Net Regression which are regularize variations of Linear Regression.
LINEAR REGRESSION
Linear Regression gives a linear relationship between the independent variable and the dependent variable. The linear model produces the target value depending on the amount of variation in the weighted input.
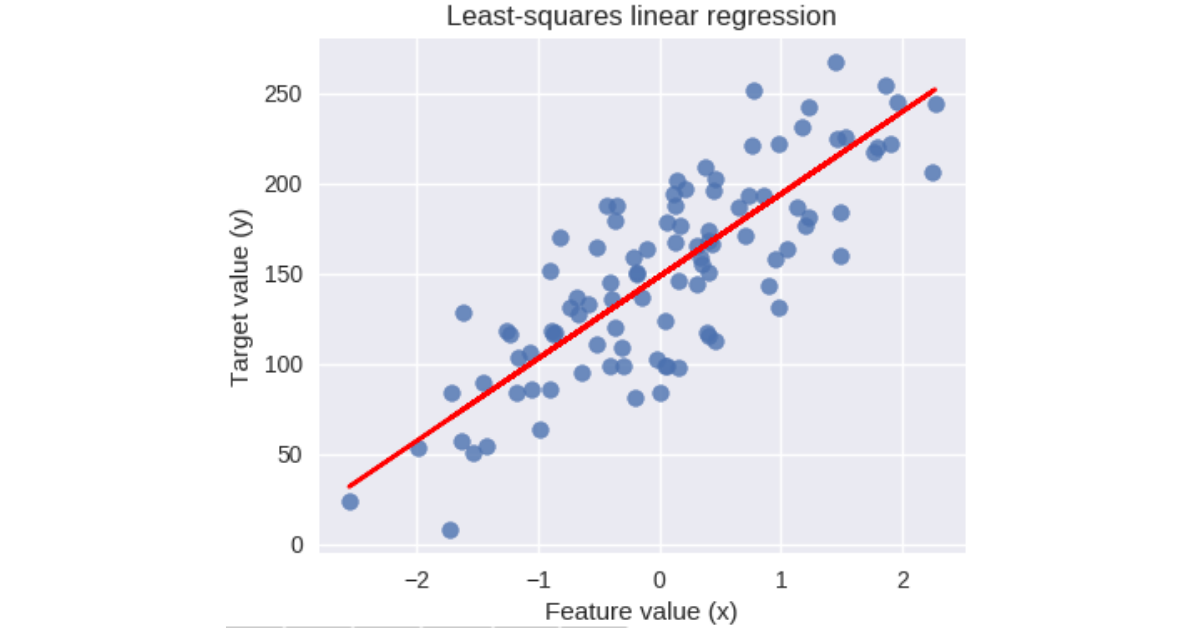
The figure above gives the best fit line based on the linear relation between the feature values and the target values. The best fit line can be describe using the linear equation below.

w0 represents the slope referred to as the model coefficient or feature weights of the independent variable x, b is the intercept and y is the dependent variable or output value. For multiple data points, the equation would look like.

Linear regression works towards reducing the cost function, which is usually the mean squared error divided by the number of data points (n).
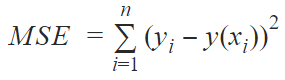
The cost function helps to find the best value for (w,b) that minimizes the sum of squared differences. This minimization can be complete using the gradient descent algorithm.
BIAS-VARIANCE
Bias occurs when the model makes assumptions during training but these assumptions are not be correct when the model applies to testing data. These assumptions by the model to make the target function easier to learn. On the other hand, Variance is the sensitivity of the model towards changes in the data.
however, Variance is when the model memorizes or learns too much from the training data, which hinders its ability to generalize leading to inaccurate predictions when introduced to testing data.

Image Source: Bias-Variance
By analyzing the bias-variance, it is possible to evaluate the performance of a model. An accurate model will have low variance and low bias. High bias is when the model fails to take-in the relation between the features and target, which leads to inaccurate predictions, this is called underfitting. When the complexity of the model increases, the variance increases as well. High variance causes the spread of data, which is also refer overfitting.
The ordinary least squares model performs poorly on a large multivariate dataset which has more variables than samples. To prevent overfitting, we take a penalty approach called regularization, to improve the performance of the model, by restricting the model.
RIDGE REGRESSION | LINEAR REGRESSION
Ridge Regression determines (w,b) using the same least-squares cost function but adds a penalty for large variations in w parameters. It uses the L2 penalty i.e minimizes the sum of squares of model coefficients. The cost function for Ridge regression is below.
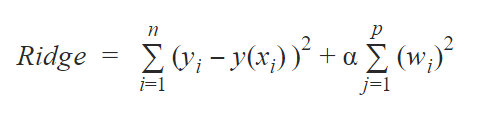
The influence of the penalty term is control by the alpha parameter. The alpha parameter decides the severity of the penalty imposed on the model. Higher alpha increases regularization and leads to less complex models. When =0, the result is similar to the least-squares method. As , the penalty increases and the coefficents move towards zero, however, they will never reach zero. It is also important to know that after a point, higher alpha values, might lead to underfitting. Cross-validation is a great way to find the appropriate value of alpha.
In simpler terms, if ridge regression finds two models that perform equally well on training data, it will prefer the model which has a smaller sum of model coefficients. Ridge regression provides with better grouping effect, in which colinear features are select up together.
LASSO REGRESSION
Lasso Regression is another form of regularized linear regression, similar to Ridge regression with a difference in the penalty parameter. thus, this regression uses the L1 penalty i.e minimizes the sum of the absolute values of model coefficients. The penalty parameter in lasso regression sets the model coefficients to zero for features with less prediction power.
This effect allows for improved feature selection by eliminating less influential features. As a result, it is usually used on datasets having more number of features. The function of the alpha parameter is similar to that in ridge regression. The cost function for lasso regression is given below.
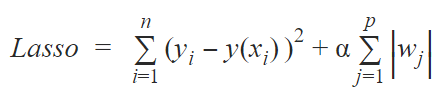
ELASTIC-NET REGRESSION
We can choose Ridge and Lasso regression when we have enough information about the features but it is difficult to choose one when the data has too many features and variables. In such cases, we use Elastic-Net regression which is good at estimating correlations between features. The penalty function of elastic net regression is a combination of both L1 and L2 penalties from lasso and ridge regression respectively. In other words, it combines the power of both ridge and lasso regression. The cost function for elastic-net regression is given below

The elastic net regression has the basic least-squares followed by lasso and ridge penalties with their respective alpha parameters 1and 2. The most optimum combination of alpha parameters can be determined using cross-validation.
CONCLUSION
To sum up, linear regression attempts to map the relation between features and target to make accurate predictions. However, high bias and high variance deteriorate its accuracy. In order to tackle this issue, we use regularized variations of the OLS, Ridge, Lasso, and Elastic Net regression to improve model effectiveness.
written by: Vishva Desai
reviewed by: Vikas Bhardwaj