
What is KNN?
K-Nearest Neighbor is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions). KNN has been used in statistical estimation and pattern recognition already in the beginning of 1970’s as a non-parametric technique.
So, these KNN are use in various fields , like if we consider an example in the field of recommender systems. So, let’s consider an industrial application of KNN algorithm, So this K-Nearest Neighbor is use in Amazon, Netflix, etc.
when you ask a counter guy for a product, he will not only show that product, he shows you various different types of product, which are relevant to your taste or the product you choose for.
however, amazon is able to generate more than 35% of its revenue from these recommender systems in which they are using one of the technique KNN.
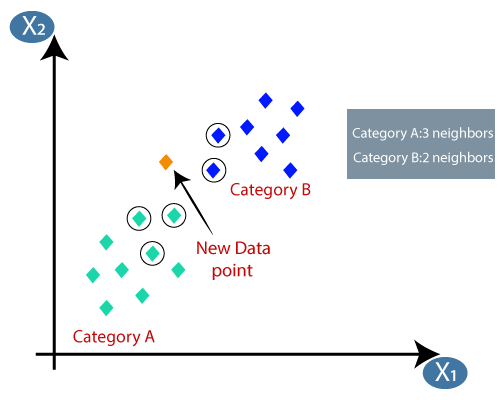
Intuition of K-Nearest Neighbor:
The K-NN working can be explained on the basis of the below algorithm:
- Step-1: Select the number K of the neighbors
- Step-2: Calculate the Euclidean distance of K number of neighbors
- Step-3: Take the K-Nearest Neighbor as per the calculated Euclidean distance.
- Step-4: Among these k neighbors, count the number of the data points in each category.
- Step-5: Assign the new data points to that category for which the number of the neighbor is maximum.
- Step-6: Our model is ready.
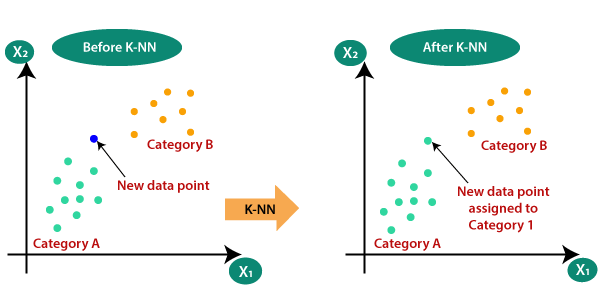
How It Works?
- So, basically, these steps can be explained in other words as follows:
- firstly, we will plot our data set onto a graph, where the various and different classes are colored according to their respective classes.
- Then comes our step, to select our value of k, where this optimum value of k can be found by randomly experimenting with the value of k, which ensures that accuracy on our test data is maximum.
- So, when we take our new data point then we will find the euclidean distance between every data point in our data set and let these distances be stored in an optimum format.
- thus, in that optimum data, let us sort out the data concerning euclidean distances from minimum to maximum, and then let’s select the first k values in that sorted data.
- So, after picking out those k nearest points than in that points, count the classes those points belongs to and make a detailed entry of those categories or classes
- Finally, Assign the new data points to that category for which the number of the neighbor is maximum.
- So, this is how the K-Nearest Neighbor algorithm works and outputs the best and optimum category that the new data belongs to.

How to select the value of k?
Below are some points to remember while selecting the value of K in the K-NN algorithm:
- There is no particular way to determine the best value for “K”, so we need to try some values to find the best out of them. The most preferred value for K is 5.
- A very low value for K such as K=1 or K=2, can be noisy and lead to the effects of outliers in the model.
- Large values for K are good, but it may find some difficulties.
Advantages of KNN:
- It is simple to implement.
- also robust to the noisy training data.
- It can be more effective if the training data is large.
Down Sides of KNN:
- Always needs to determine the value of K which may be complex some time.
- The computation cost is high because of calculating the distance between the data points for all the training samples.
Summary
So, in this article we have seen the in depth of K-Nearest Neighbor and the use cases of KNN and the optimum way to find the value of K and even advantages as well as disadvantages of KNN.
written by: Naveen Reddy
reviewed by: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs