Introduction: K-Fold Cross-Validation
Generally, while building machine learning models, the dataset is split into train and test datasets so that model can be trained with the training dataset and can be evaluated with the test dataset. We may obtain very much high accuracy for the test dataset at the first instance. What if, there is a new set of test data. Will the same accuracy be show by the model in the production environment?
Certainly not… therefore, The model may encounter new test data that was not available in the training set. so, As the new data was not available in the training dataset, it could not understand the pattern and fail to predict the correct output in the production environment. So, is there any solution for this anomaly?
Yes, of course. K-fold cross-validation is the solution to this problem.
Here I will be discussing what is k-fold cross-validation, the cross-validation process, and finally K-fold cross-validation on the Iris dataset in Python.
What is K-Fold Cross-validation?
K-Fold Cross-Validation is one of the resampling techniques used to check the performance of the machine learning models. This technique helps to determine whether the model will be overfitting, underfitting, or a generalized model when tested with new unseen data.
During this technique, our dataset is divide up into k- fold, and at each time of K-th iterations, a new section of data is select as a test dataset, so that model can be trained with the entire dataset at different iterations and can understand the pattern of the entire data and performs well with the new data set.
Process of K-Fold Cross-validation
In this process, the entire data is divide up into K-fold/parts (Generally k is select as any value between 5 and 10). therefore, In the first instance, the first set is consider as a test set and the remaining k-1 part as a training dataset. therefore, The model is build on the training dataset and validate on the test set.
however, In the 2nd iterations, the second part is consider as the test set and the remaining set as the validation set. Repeat the process kth number of times and finally, the average score is take from all iterations to derive the accuracy score of the model.
The k-fold cross validation process can be understand from the figure below:

mage Source: Youtube Channel Code Basics
In the above figure, 100 samples are reserve as a dataset. This dataset is divide up into 5 sections. K=5 here. Each set contains 20 samples. At the first iteration, the 1st section is consider as the test dataset and the remaining 4 sections are consider as the training dataset. Model is train on the training dataset and test score is calculate on the test dataset.
The process continues 5 times and each time the test score is calculate by interchanging the train and the test datasets. The scores of all 5 iterations are combine and the average is reserve to declare the Score of the final model.
I hope the process is clear now.
K-Fold Cross-validation on the Iris dataset
Let’s see now how cross-validation is perform in python. Here iris dataset is consider as sample datasets and the cross-validation score is calculate for different models like Logistic regression, Random Forest and Support Vector Machine.
Jupyter Notebook is use as the IDE or Integrate Development Environment.
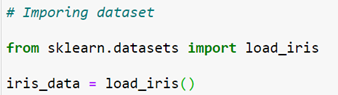
1. Importing Dataset
2. Extracting input and target variables from Iris dataset

3. Import Cross_val_score from
This is for calculating the cross-validation score for each model.

4. Model Building
- Logistic Regression Model

Cross-validation score for Logistic Regression Model

Here CV= 3, means k= 3. i.e., no. of folds is conceive as 3.
- Random Forest

Cross-validation score for Random Forest Model

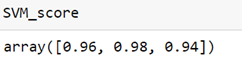
- Support Vector Machine

Cross-validation score for Support Vector Machine model
5. Model comparison
At each model, the average of all the scores is calculate and then compare.
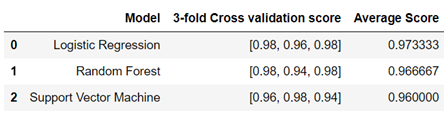
From the above table, the maximum score is for logistic regression that is of 97.33 % and can be consider as the best model for prediction.
The complete code is available in the below mentioned GitHub Link: https://github.com/nabanitapaul1/K-fold-Cross-validation-.git
The above process is one way of calculating the cross-validation scores and finding out the best model. There is another way of performing by importing the KFold function from the sklearn library and calculating cross-validation score which I am not covering here.
Conclusion
In this article, I have explained, what is k-fold cross-validation, the process of cross-validation, and how to calculate cross-validation scores in python for different models.
Thank you all for reading the article. Please post your comments and suggestions.
Written By: Nabanita Paul
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs