
Identification Of High Credit Risk
Identification of high credit risk customers has become necessary for financial organizations like banks to detect safe borrowers for lending out the money and to follow up the high credit risk customers. These high credit risk customers can be identified with help of various parameters such as their age, education, marital status, balance & previous payment transactions.
Here, I have experimented with two different supervised machine learning algorithms i.e. Support Vector Machine (SVM) & Artificial Neural Network (ANN) thus for identification of high credit risk customers.
Algorithms & Justification:
I. Artificial Neural Network (ANN):

In this system, I have thus used Artificial Neural Network (ANN) having one input layer, one hidden layer & one output layer. Activation functions used by me are Sigmoid & Relu.
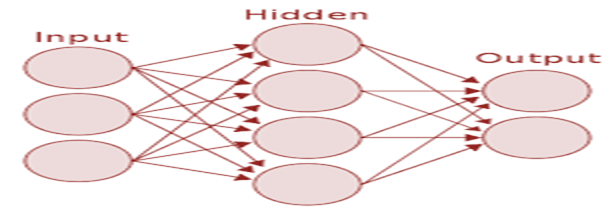
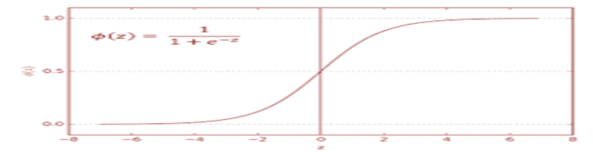
a) Sigmoid activation function (F2)
Range : 0 to 1.
Advantages :
- It can be easily used at the output layer of the neural network for binary classification problems as the value of sigmoid function lies between 0 and 1 and output can be predicted by keeping some threshold value between 0 and 1.
- It has Smooth gradient, also preventing jumps in output values.
Disadvantages :
- For very high or very low values of X, there is almost no change to the prediction, causing a vanishing gradient problem. Due to this, the learning rate of a network may decrease & it cannot predict the accurate output.
- It is computationally expensive.
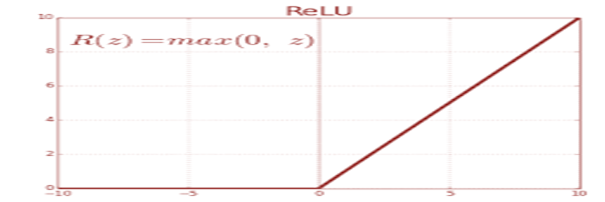
b) ReLU activation function:
Range: 0 to infinity
Advantages:
- It is more computationally efficient than other functions like Sigmoid as it has to just pick up max(0, x) value and do not need to perform expensive computations like exponentials.
- It has good convergence performance as compared to Sigmoid.
Disadvantages:
- ReLU is not differentiable at zero and it is unbounded.
- The gradients of negative inputs are zero, it means for activations in that particular region, the weights aren’t updated during backpropagation. This process may create dead neurons which will never get activated. To handle this situation, we can reduce the bias & learning rate.
- The output of ReLU is not centred at zero and this affects the performance of the neural network. The gradient of the weights during backpropagation can either be all positive or all negative. however, This may indulge undesirable irregularities for updating the gradients of weights. To handle this, we can also use batch norm method.
Justification:
Here, I have chosen ANN because:
- It demonstrates the ability to model complex relationships.
- however, It works well for missing values.
- It is thus capable of processing multiple tasks parallelly.
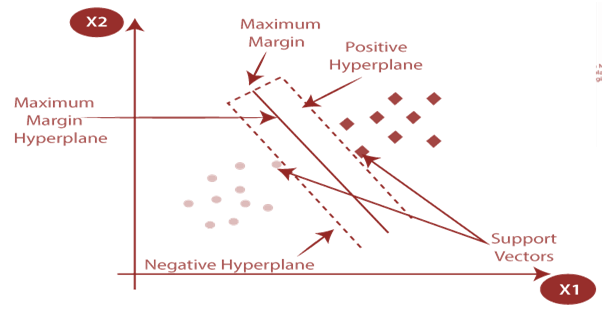
II. Support Vector Machine (SVM):

In SVM, the hyperplane with maximum margin is however drawn based on parameters such as age, education, marital status, balance & previous payment transactions.
so, to classify the customers into two categories i.e. high credit risk customers and low credit risk customers based on the values of these parameters.
Justification:
Here, I have chosen SVM as a classification algorithm because,
- It also works well for binary classification problems having clear class separation margin.
- though, It works well in high dimensional spaces.
- It’s efficient in terms of memory.
Results & discussion:
| ANN | SVM | |
| Accuracy | 81.95 % | 100 % |
| Precision | 66.94 % | 100 % |
| Recall | 36.32 % | 100 % |
| F1 Score | 47.09 % | 100 % |
Results are evaluated based upon various performance metrics such as accuracy, precision, recall & f1 score.
Accuracy = ( TN + TP ) / ( FP + FN+TN + TP )
Precision = TP / ( FP + TP)
Recall = TP / ( FN + TP)
F1 Score = 2(Recall*Precision) /( Recall + Precision)
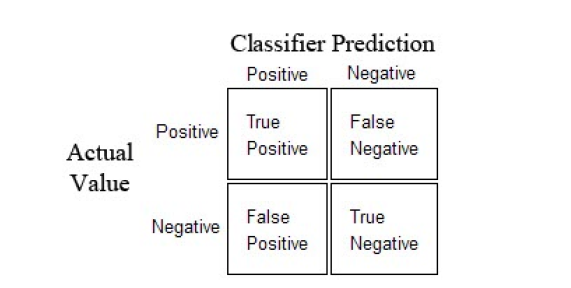
Where,
TP = True Positive
FP = False Positive
FN = True Negative
TN = True Negative
Conclusion:
SVM gave the highest accuracy of 100 % for the Identification Of High Credit Risk and low customers for the given dataset.
Written By: Priyanka Shahane
Reviewed By: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs