
Index
- Introduction
- Significance of Balanced Dataset
- Techniques to Handle Imbalanced Data
- Choice of Right Evaluation Metrics
- Resampling the Training Set
- Cost-Sensitive Ensembles
- Use Tree-based Algorithms
- Summary
Introduction
Every Machine Learning enthusiast knows the importance of Datasets which are use for training the machine learning model. Steps such as data preprocessing, data preparation are all taken to ensure that the dataset is fault-free. Here, in this article, we are going to discuss yet another problem with the datasets that leads to ineffective model training and performance.
Significance of Balanced Dataset over Imbalanced Datasets
Imagine creating a model that predicts, based on various features, the possibility of a person suffering from ‘Bronchial Asthma’. After training the model, you get an accuracy of 96.7% and thus declare your model to be a success. However, when the model is tested on real data, it is find that the model is of no use as it predicts every individual to be healthy. so, the question here is: where did you go wrong?
Well, after some analysis it is find up that the dataset you uses only 3.3% of people suffering from Bronchial Asthma (i.e. unhealthy), and your model just always answers “healthy”, leading to a 96.7% accuracy. This kind of inappropriate result is due to the use of an imbalanced dataset. Hence, it’s very important to maintain a balance between the class labels in classification problems.
Techniques to Handle Imbalanced Datasets:
Now, we do have a basic understanding of what an imbalanced datasets is and it can be problematic when creating a model, using this dataset. Let’s discuss the methods that can be implements to handle this issue.
- Choice of Right Evaluation Metrics
As seen in the introductory example, accuracy, though supremely important, can be misleading and therefore should be used carefully along with other metrics.
Confusion Matrix:
thus, It is a table that should always be use to understand the performance of a classification model. so, We can draw interesting observations from the confusion matrix about how well the model is doing.
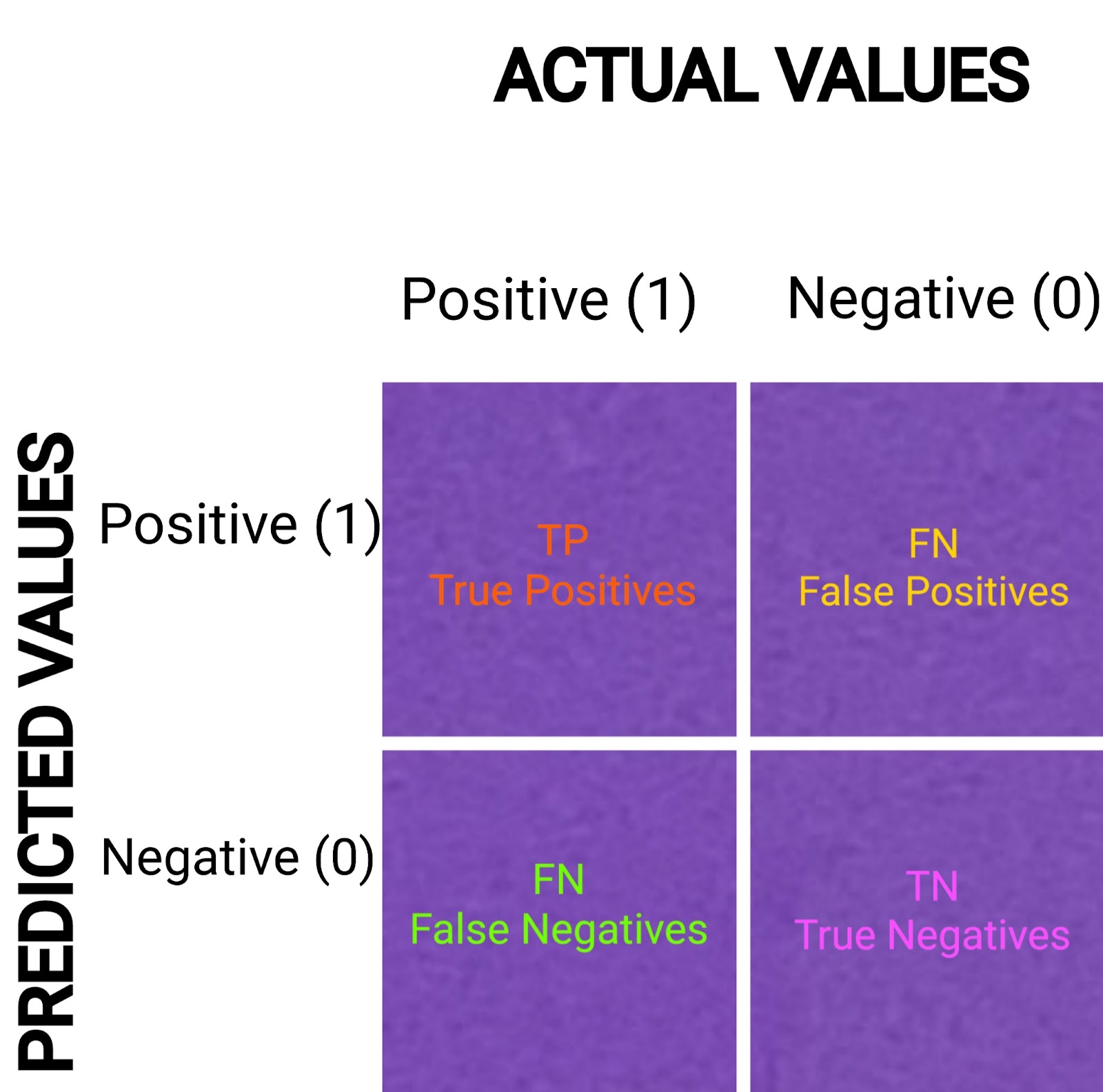
Precision:
Precision(Positive Predicted Values) of a class label is calculated by dividing the correct positive predictions by the total predicted positives. It defines how many instances from the predicted class are true.
Recall:
so, It is the ratio of true value in the predicted label to the total number of true values of the class. It helps observe how well the model is able to detect that class.
F1 Score:
however, F1 score combines the precision and recall of a class label in one metric. It is the harmonic means of precision and recall.
AUC-ROC Curve:
The AUC(Area Under the Curve) ROC(Receiver Operating Characteristics) curve is a very important evaluation metric. It measures the performance of a classification problem at various threshold settings. therefore, ROC is a probability graph that plots TPR(True Positive Rate) against the FPR(False Positive Rate) at various threshold points. The AUC is the area under the ROC curve. so, The higher the value of AUC, the better the model is at distinguishing class labels.
- Resampling the Training Set
Another fine approach to handle the problem of imbalanced data in a classification problem is to randomly resample the training dataset. Two main techniques in this approach are- Undersampling and Oversampling.
Undersampling:
This method of resampling is use when the dataset is large enough. Here, samples of the majority class are randomly deleted to maintain a balance with the minority class.
Oversampling:
In oversampling, duplicates are created of the minority class label to balance with the abundant class. This method is used when the dataset isn’t large enough for us to carry out undersampling. SMOTE(Synthetic Minority Over-Sampling Technique) is a popular example of this approach.
- Cost-Sensitive Ensembles
This group covers techniques designed to filter the predictions from traditional machine learning models to take misclassification costs into account.
There are cost-sensitive algorithms as well that increase the cost of classification mistakes on the minority class.
One such technique is penalized-SVM.

- Use Tree-based Algorithms
Tree-based algorithms often perform well on an imbalanced dataset. It is because of the hierarchical structure that allows them to read signals from both classes. Decision trees fit the criteria, however, ensemble algorithms like Random Forest Classifier, Gradient Boosted Trees, etc always outperform single decision trees.

Summary
We saw different approaches for handling imbalanced datasets in a classification problem. Some techniques focused on the data(like the resampling technique) while some focused on the model(using penalized-SVM). Creating our model to deal with imbalanced datasets can be a great approach. Designing a cost function that penalizes the wrong classification of the minor class more than the wrong classifications of the major class, would make it possible to design models that generalize in favor of the minor class.
Thus, we need to be creative and think of different approaches to model this problem as there is no best method that works on every imbalanced dataset.
Written By: Jagriti Prakash
Reviewed By: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs