
Introduction to Gradient Boosting
Gradient Boosting (initially called speculation boosting) alludes to any Ensemble strategy that can join a few powerless algorithms into a solid Algorithm. The overall thought of most boosting strategies is to prepare indicators successively, each attempting to address its predecessor. There are many boosting techniques accessible, however by a long shot, the most famous are AdaBoost13 (short for Adaptive Boosting) and Gradient Boosting.
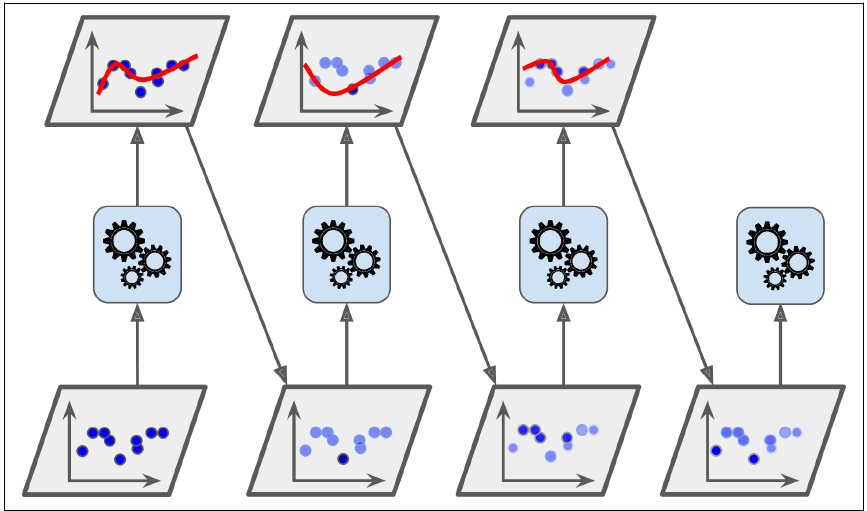
Along these lines, Boosting similarly to any other ensemble algorithm is to join a few powerless learners into a more grounded one. The overall thought of Boosting calculations is to attempt indicators consecutively, where each ensuing model endeavors to fix the mistakes of its archetype.
This is another extremely well known Boosting calculation whose work premise is much the same as what we’ve seen for AdaBoost. Inclination Boosting works by successively adding the past indicators under fitted forecasts to the gathering, guaranteeing the errors made already are remedied.
however, The distinction lies in what it does with the under fitted estimations of its archetype. also, In opposition to AdaBoost, which changes the occasion loads at each collaboration. however, this strategy attempts to fit the new indicator to the leftover blunders made by the past indicator. With the goal that you can also comprehend Gradient Boosting it is essential to comprehend Gradient Descent first.
Bagging:-
basic ensembling strategy in which we thus manufacture numerous autonomous indicators/models/learners and consolidate them utilizing some model averaging procedures. (for example weighted normal, dominant part vote, or ordinary normal)
Boosting:-
troupe method in which the indicators are not made autonomously, however successively.
This strategy utilizes the rationale wherein the resulting indicators thus gain from the slip-ups of the past indicators. In this way, the perceptions have also an inconsistent likelihood of showing up in ensuing models, and the ones with the most elevated blunder show upmost. (So the perceptions are not picked dependent on the bootstrap cycle, yet dependent on the mistake).
The indicators can be looked over a scope of models like choice trees, Regressor, classifiers, and so forth Since new indicators are gaining from botches submitted by past indicators, it takes less time/emphasis to arrive at near real forecasts. In any case, we need to pick the halting models cautiously or it could prompt overfitting on preparing information. Inclination Boosting is a case of boosting calculation.


Reference: https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
Adaptive Boosting (AdaBoost):-
One path for another indicator to address its archetype is to give a touch more consideration to the preparation occasions that the archetype is under fitted. These outcomes in new indicators zeroing in increasingly more on the hard cases. This is the strategy utilized by AdaBoost.
For instance, to construct an AdaBoost classifier, a respectable starting point classifier, (for example, a Decision Tree) is prepared and used to make expectations on the preparation set. The general weight of misclassified preparing cases is then expanded. however, A subsequent classifier is prepared to utilize the refreshed loads and again it makes expectations on the preparation set, loads are refreshed, etc.
When nothing works, Boosting does. These days numerous individuals use either XGBoost or LightGBM or CatBoost to win rivalries at Kaggle or Hackathons. hence, AdaBoost is the first venturing stone in the realm of Boosting.
though AdaBoost is one of the first boosting calculations I have used and walla!! so, to be adjusted in explaining rehearsals. Adaboost causes you to consolidate different “feeble classifiers” into a solitary “solid classifier”.
CSAT & DSAT
Let’s take a look at a simple example where we are trying to establish a model that emulates customer satisfaction (CSAT) and customer dissatisfaction(DSAT) from a dataset that I have gathered from my previous company. I have one hot encoded the levels of the same, CSAT being “0” and DSAT being “1”.
Enough Theory!!, Let’s start looking at some code now.
First off!!, Let’s take a look at Support Vector Machines(SVM) on how it performs on the same training and testing set. I have used mean squared error as my measure of tendencies.
Code:-
In [1] :
from sklearn import svm #importing svm
clf = svm.SVC(kernel=’rbf’) #selecting the model
clf.fit(X_train, y_train) #training our model
y_val = clf.predict(X_test) #that has the predicted dsat’s list.
mse = mean_squared_error(y_val, y_test)
print(“Train set Accuracy: “, metrics.accuracy_score(y_train, clf.predict(X_train)))
print(“Test set Accuracy: “, metrics.accuracy_score(y_test, y_val))
print(“Validation MSE for SVM: {}”.format(mse))
Output:-
Train set Accuracy: 0.8905109489051095
Test set Accuracy: 0.855072463768116
Validation MSE for SVM: 0.14492753623188406
Error:-
In [2]:
#check the error between the actual dsat’s and the predicted dsat’s
a , b= y_val.sum() , y_test.sum() #diving the predicted values
err=a/b
err
Out[2]:
0.3333333333333333
The graph that depicts Support Vector Machines:-

Second!!, Let’s chew on another famous algorithm called Decision Tree Regressor. Like SVMs, Decision Trees are adaptable Machine Learning calculations that can perform both characterization and relapse assignments, and even multi yield undertakings. They are a powerful algorithm, equipped for fitting complex datasets.
Code:-
In [3]:
from sklearn.tree import DecisionTreeClassifier
DTree = DecisionTreeClassifier(criterion=”entropy”, max_depth = 10)
DTree.fit(X_train,y_train)
y_val = DTree.predict(X_test)
mse = mean_squared_error(y_val, y_test)
print(“Train set Accuracy: “, metrics.accuracy_score(y_train, DTree.predict(X_train)))
print(“Test set Accuracy: “, metrics.accuracy_score(y_test, y_val))
print(“Validation MAE for DTR: {}”.format(mse))
Output:-
Out [3]:
Train set Accuracy: 0.8978102189781022
Test set Accuracy: 0.8695652173913043
Validation MSE for DTR: 0.13043478260869565
Error:-
In [4]:
a , b= y_val.sum() , y_test.sum() #diving the predicted values
err=a/b
err
Out[4]:
0.4444444444444444
The graph that depicts Decision Tree Regressor:-

Third and Final, The hero of the blog!! AdaBoost Classifier
Code:-
In [5]:
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=7), n_estimators=900,
algorithm=”SAMME.R”, learning_rate=0.01)
ada_clf.fit(X_train, y_train)
y_val = ada_clf.predict(X_test)
mse = mean_squared_error(y_val, y_test)
print(“Train set Accuracy: “, metrics.accuracy_score(y_train, ada_clf.predict(X_train)))
print(“Test set Accuracy: “, metrics.accuracy_score(y_test, y_val))
print(“Validation MAE for ADA boost classifier is: {}”.format(mse))
Output:-
Train set Accuracy: 0.9306569343065694
Test set Accuracy: 0.8695652173913043
Validation MAE for ADA boost classifier is: 0.13043478260869565
Error:-
In [6]:
a , b= y_val.sum() , y_test.sum() #diving the predicted values
err=a/b
err
Out[6]:
0.8888888888888888
The graph that depicts AdaBoost classifier:-

Conclusion:-
As these models illustrate, true information incorporates a few examples that are direct yet additionally numerous that are most certainly not. Changing from direct relapse to gatherings of choice stumps(aka AdaBoost) permits us to catch a considerable lot of these non-straight connections, which converts into better expectation precision on the issue of interest, regardless of whether that be finding the best wide collectors to draft or the best stocks to buy.
Ideally, this has thus furnished you with a fundamental comprehension of how gradient boosting and how the AdaBoost classifier gives truly necessary exhibition support.
written by: Kamuni Suhas
reviewed by: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs