Assume you pose an unpredictable inquiry to a great many irregular individuals, at that point total their answers. By and large, you will find that this amassed answer is in a way that is better than a specialist’s answer. This is known as the astuteness of the group.
Likewise, in the event that you total the forecasts of a gathering of indicators, (for example, classifiers or regressors), you will regularly improve expectations than with the best individual indicator. A gathering of indicators is refer to a group; along these lines, this method Refer To Ensemble Learning, and a Gathering Learning calculation is Refer To as Ensemble technique.
Ensemble Learning techniques join a few choice tree classifiers to create preferable prescient execution over a solitary choice tree classifier. The primary rule behind the outfit model is that a gathering of feeble algorithms meets up to frame a solid algorithm, hence expanding the exactness of the model. When we attempt to anticipate the objective variable utilizing any AI strategy, the fundamental driver of contrast in genuine and anticipate qualities are noise, variance, and bias. Ensemble always helps to lower these traits (except noise, which can never be lowered.).
Ensemble techniques can be partitioned into two gatherings:-
- Sequential ensemble methods where the base learners are produce successively (for example AdaBoost).
The essential inspiration of successive strategies is to misuse the reliance between the base learners. The general exhibition can be helped by weighing already mislabel models with higher weight.
- Parallel ensemble methods where the base learners creates in equal (for example Random/Arbitrary Forest).
The fundamental inspiration of equal techniques is to abuse freedom between the base learners since the mistake can be diminished drastically by averaging.
Bootstrapping | Ensemble Learning:-
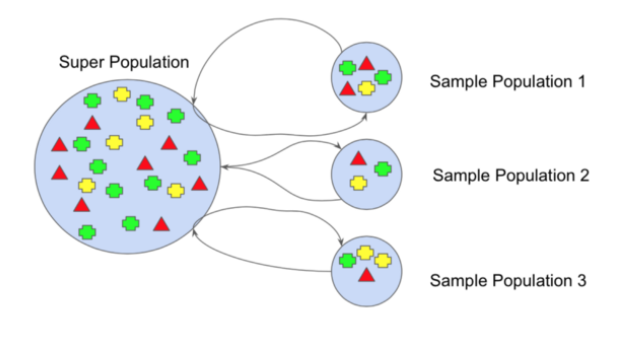
Bootstrap alludes to arbitrary testing with substitution. however, it permits us to more readily comprehend the predisposition and the fluctuation with the dataset. Bootstrap includes arbitrary examining of a little subset of information from the dataset. This subset can be supplant. The choice of all the models in the dataset has an equivalent likelihood. This strategy can assist with bettering comprehend the mean and standard deviation from the dataset.
How about we expect we have an example of ‘n’ values (x) and we’d prefer to get a gauge of the mean of the example.
mean(x) = 1/n * sum(x)
Boosting-
Packing represents bootstrap accumulation. One approach to decrease the change of a gauge is to average together various assessments. For instance, we can prepare M various trees on various subsets of the information (picked haphazardly with substitution) and process the ensemble:
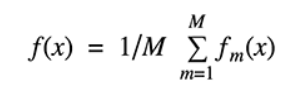
Stowing utilizes bootstrap examining to get the information subsets for preparing the base students. For amassing the yields of base students, stowing utilizes deciding in favor of order and averaging for relapse.
We can contemplate stowing with regards to order on the Iris dataset. We can pick two base assessors: a choice tree and a k-NN classifier. Figure 1 shows the educated choice limit of the base assessors just as their sacking troupes applied to the Iris dataset.
- Decision Tree: Exactness: 0.63 (+/ – 0.02)
- K-NN: Exactness: 0.70 (+/ – 0.02)
- Bagging Tree: Exactness: 0.64 (+/ – 0.01)
- Bagging K-NN: Exactness: 0.59 (+/ – 0.07)
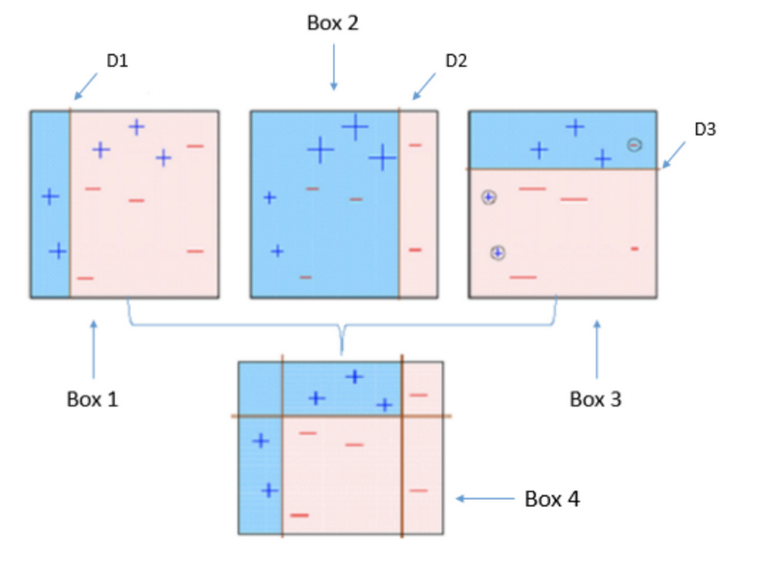
Box 1:
You can see that we have doled out equivalent loads to every information point and applied a choice stump to characterize them as + (in addition to) or — (less). The conclusion stump (D1) has produced a vertical line on the left side to characterize the information focus. We see that this vertical line has inaccurately anticipated three + (in addition to) as — (less). In such a case, we’ll relegate higher loads to these three + (in addition to) and apply another choice stump.
Box 2:
Here, you can see that the size of three inaccurately anticipate + (in addition to) is greater when contrast up with the rest of the information focused. For this situation, the subsequent choice stump (D2) will attempt to foresee them effectively. Presently, a vertical line (D2) at the right half of this case has grouped three misarranged + (in addition to) effectively. However, once more, it has caused mis-grouping blunders. This time with three – (short). Once more, we will relegate a higher load to three — (less) and apply another choice stump.
Box 3:
Three — (short) are apply higher loads. A conclusion stump (D3) applies to foresee these mis-group perceptions accurately. This time an even line creates to group + (in addition to) and — (short) in light of a higher load of mischaracterized perception.
Box 4:
Here, we have consolidated D1, D2, and D3 to shape a solid expectation having complex standards when contrast up with individual feeble students. You can see that this calculation has grouped these perceptions very well when contrasted with any individual powerless student.
Bagging:-
Bootstrap Aggregation (or Bagging for short), is a basic and amazing outfit strategy. Packing is the use of the Bootstrap methodology to a high-difference AI calculation, commonly choice trees.
Assume there are N perceptions and M highlights. An example from perception is chosen haphazardly with replacement(Bootstrapping).
A subset of highlights is pick up to make a model with a test of perceptions and subset of highlights.
Highlight from the subset is pick up which gives the best part on the preparation data. (Visit my blog on Decision Tree to know a greater amount of best split)
This is rehashed to make numerous models and each model is prepare in equal.
The expectation is given depending on the conglomeration of forecasts from all the models.
When stowing with choice trees, we are less worried about individual trees overfitting the preparation information. Hence and for proficiency, the individual choice trees are developed profoundly (for example not many preparing tests at each leaf-hub of the tree) and the trees are not pruned. These trees will have both high change and low predisposition. These are significant descriptions of sub-models when joining forecasts utilizing packing. The main boundaries when sacking choice trees is the number of tests and consequently the number of trees to incorporate. This can be picked by expanding the number of trees on a pursuit until the exactness starts to quit demonstrating improvement.
Bagging Or Boosting:-
There’s no real no-loser in this, it relies upon the information, the simulation, and the conditions.
Bagging and Boosting decline the change of your single gauge as they join a few assessments from various models. So the outcome might be a model with higher strength.
On the off chance that the issue is that the single model gets an exceptionally low exhibition, Bagging will infrequently improve inclination. Be that as it may, Boosting could produce a consolidated model with lower mistakes as it advances the focal points and decreases entanglements of the single model.
On the other hand, in the event that the trouble of the single model is overfitting, at that point Bagging is the most ideal alternative. Boosting as far as it matters for it doesn’t assist with abstaining from over-fitting; indeed, this method is confronted with this difficulty itself. Hence, Bagging is compelling more regularly than Boosting.
written by: Kamuni Suhas
reviewed by: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs