
A Gaussian Mixture Model (GMM) is a probabilistic model that accepts that the cases were created from a combination of a few Gaussian conveyances whose boundaries are obscure. All the cases created from a solitary Gaussian conveyance structure a group that regularly resembles an ellipsoid. Each bunch can have an alternate ellipsoidal shape, size, thickness, and direction.
At the point when you notice a case, you realize it was produced from one of the Gaussian distributions yet you are not told which one, and you don’t have the foggiest idea what the boundaries of these conveyances are. There are a few GMM variations: in the least difficult variation, executed in the Gaussian Mixture class, you should know ahead of time the number k of Gaussian conveyances.
The data-set X is expected to have been created through the accompanying probabilistic cycle:
- For each occasion, a group is picked arbitrarily among k clusters. The likelihood of picking the jth cluster is characterized by the group’s weight ϕ(j). The record of the group picked for the i
thcase is noted z(i).
- In the event that z(i)=j, which means the ith occurrence has been relegated to the jth cluster, the area x(i) of this occasion is inspected arbitrarily from the Gaussian distribution with mean μ(j) and covariance network Σ(j). This is noted x(i) ∼ N(μ(j), Σ(j)).

Here is the way to decipher the above figure:-
- The circles speak to random variables.
- The squares speak to fixed qualities (i.e., boundaries of the model).
- The huge square shapes are called plates: they show that their substance is rehashed a few times.
- The number demonstrated at the base right-hand side of each plate shows how commonly its substance is rehashed, so there are m irregular factors z(i) (from z(1) to z(m))and m irregular factors x(i), and k means μ(j)and k covariance networks Σ(j), yet only one weight vector ϕ (containing all the loads ϕ(1) to ϕ(k)).
- Each factor z(i) is drawn from the unmitigated circulation with weights ϕ. Each variable x(i) is drawn from the typical dispersion with the mean and covariance grid characterized by its group z(i).
- The strong bolts speak to restrictive conditions. For instance, the likelihood conveyance for every arbitrary variable z(i) relies upon the weight vector ϕ. Note that when a bolt crosses a plate limit, it implies that it applies to all the reiterations of that plate, so for instance the weight vector ϕ conditions the likelihood conveyances of the relative multitude of arbitrary factors x(1) to x(m).
The squiggly bolt from z(i) to x(i) speaks to a switch:
contingent upon the estimation of z(i), the case x(i) will be examined from alternate Gaussian dissemination. For a model, in the event that z(i)=j, at that point x(i) ∼ N(μ(j), Σ(j)).
Shaded hubs demonstrate that the worth is known, so for this situation, just the irregular factors x(i) have known qualities: they are called noticed factors. The obscure arbitrary factors z(i) are called inactive factors.
So how would you be able to manage quite a model? All things considered, given the dataset X, you commonly need to begin by assessing the wights ϕ and all the dissemination parameters μ(1) to μ(k) and Σ(1) to Σ(k).
Scikit-Learn’s Gaussian Mixture class makes this inconsequential:
from sklearn.mixture import GaussianMixture
g_m = GaussianMixture(n_components=3, n_init=10)
g_m.fit(X)
Let’s take a look at the parameters that algorithm estimated:
>>> g_m.weights_
array([0.20965228, 0.4000662 , 0.39028152])
>>> g_m.means_
array([[ 3.39909717, 1.05933727],
[-1.40763984, 1.42710194],
[ 0.05135313, 0.07524095]])
>>> g_m.covariances_
array([[[ 1.14807234, -0.03270354],
[-0.03270354, 0.95496237]],
[[ 0.63478101, 0.72969804],
[ 0.72969804, 1.1609872 ]],
Extraordinary, it turned out great! Surely, the loads that were utilized to create the information were 0.2, 0.4, and 0.4, and correspondingly, the methods and covariance networks were extremely near those found by the calculation.

Cluster Performance Evaluation | Gaussian Mixture Model:-
Since we don’t have the foggiest idea about the ground reality of our cluster generators, for example, we don’t know about the first appropriation which created the information, our decisions about the presentation assessment of the clustering cycle are restricted and very loud.
In any case, we will investigate three distinct strategies.
Silhouette Scores:- This score, as obviously expressed by the SKLearn designers, think about two measures:
- The mean separation between an example and all different focuses in a similar cluster.
- The mean separation between an example and all different focuses in the following closest cluster.
For example, it checks how much the clusters are conservative and all-around isolated. The more the score is close to one, the better the grouping is.
Distance Between Gaussian Mixture Model:-
Here we structure two datasets, each with a half arbitrarily pick the measure of information. We will at that point check how much the GMMs prepared on the two sets are comparative, for every setup.
Since we are discussing conveyances, the idea of comparability is implanted in the Jensen-Shannon (JS) metric. The lesser is the JS-separation between the two GMMs, the more the GMMs concur on the most proficient method to fit the information.
All the credits on the (wonderful!) Jensen-Shannon metric is determined by going to Dougal, and to its post on StackOverflow.
Bayesian Informative curve (BIC) –
This model gives us an assessment of what amount is acceptable to the GMM regarding foreseeing the information we really have. The lower is the BIC, the better is the model to really anticipate the information we have, and by expansion, the valid, obscure, dispersion. To keep away from overfitting, this strategy punishes models with a huge number of groups.
Following this measure, the greater the number of groups, the better should be the model. This implies that the punishment BIC standards provide for complex models doesn’t spare us from overfit. Or then again, in more common terms, this score sucks. At any rate in this essential structure.
In fact, we need to figure the inclination of the BIC scores bend. Instinctively, the idea of the slope is basic: if two successive focuses have a similar worth, their inclination is zero. In the event that they have various qualities, their slope can be either negative, if the subsequent point has a lower worth, or positive in any case. The size of the inclination reveals to us how much the two qualities are unique.
Final Decision: Change Model:-
We have investigated three distinct strategies to pick the correct number of groups that can be recognized in this dataset. The outcomes are in the table beneath:
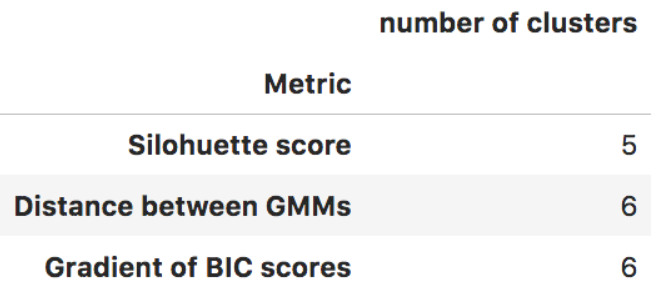
Regardless of whether the choices are comparative, there is no reasonable incentive on which all the systems concur. In this particular case, this implies that the GMM is certifiably not a decent model to bunch our information.
Another symptom you can get is that both the Silhouette and the slope of BIC show a second worth which is nearly tantamount to the pick one: 4 is nearly comparable to 5 for the Silhouette, and 5 is nearly on a par with 6 for the inclination of BIC scores.
Conclusion:
One could state to simply take five (in Medio detail virtus) as the correct number of groups, however, this couldn’t be the ideal decision. Also, incidentally, really it was not for my particular issue.
This on the grounds that the groups don’t show an unmistakable symmetric (oval-like) shape, thus they can not be approximated by a model made out of 2-d Gaussians which are rather symmetric.
written by: Kamuni Suhas
reviewed by: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs