

INTRODUCTION :
Feature Scaling is one of the most important topics in Data preprocessing.
It plays a significant role in boosting the accuracy of models, in which Machine learning algorithms are sensitive to data values.
But why do we need feature scaling?
Machine learning algorithms need feature scaling for making a better decision and to converge to global minima faster i.e in Neural Networks.
Algorithms assume that higher values in features thus represent higher priority and higher weightage to the outcome.
Let us take an example of a Fruit shop, you bought 1 orange of weight 30gram for 10₹. When you feed this data to your model it draws a relationship that weight is more important than the price of orange but in reality, the price is more important, so feature scaling is needed in this case.
Algorithms:
Algorithms which are sensitive to feature scaling are as:
- LINEAR REGRESSION
- LOGISTIC REGRESSION
- K NEAREST NEIGHBOURS
- K MEANS CLUSTERING
- NEURAL NETWORKS
Feature scaling ensures all features lie in the same uniform range which helps in reducing time and space computation.
When to apply feature scaling?
Feature scaling is used whenever we apply distance-based machine learning algorithms like SVM, K Means, KNN, etc.
These algorithms use the distance between data points to draw a relationship, if there is no similarity in values of the dataset then the accuracy of the model is pretty low so in order to boost accuracy, we apply feature scaling.
After applying feature scaling all features contribute equally to our model and hence we get better accuracy and result.
There also exist some algorithms which are insensitive to feature scaling like
TREE BASED ALGORITHMS which are Decision Tree and Random forest as their split is based on the randomness of data rather than values of data.
TYPES OF FEATURE SCALING
1. NORMALIZATION
MIN MAX SCALER
Min-max scaler is a basic scaling technique used in feature scaling.
It makes the range of each value in features between 0 and 1.
It works as

{kind=link}
This scaler is best applicable when the standard deviation is small and features don’t follow a gaussian distribution
This type of scaler is sensitive to Outliers.
2. STANDARDIZATION
STANDARD SCALER
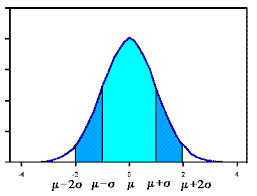
Standard scaler scales data in such a way that it centers around 0 with a unit standard deviation. It is mostly used when the feature follows Gaussian Distribution.
{kind=link}
It works as
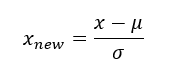
{kind=link}
Here μ = mean of feature values
σ = standard deviation of feature values
This scaler is also useful in the case of sparse CSR matrices by altering parameters and maintaining the sparsity of the data.
3. LOG TRANSFORM
however, Log transform is used whenever a feature follows Power Law Distribution.
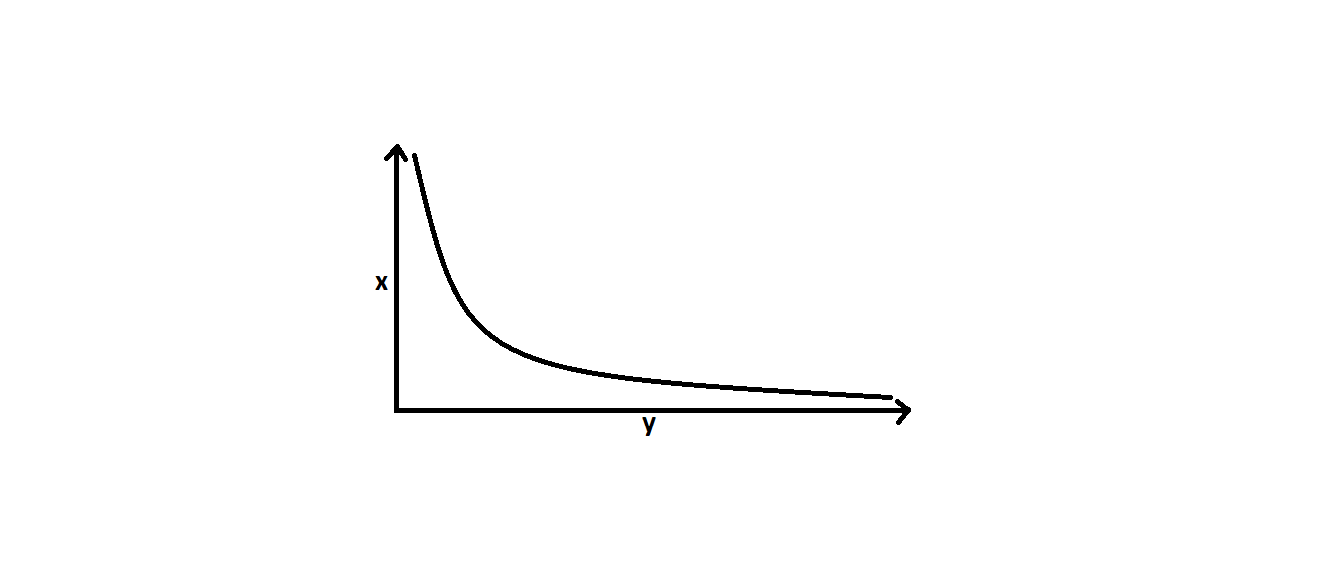
thus, Log transform is also specific to the distribution of features. It is only used when a feature follows Log transform.
Logarithm reduces the dynamic range of a variable so that the difference remains constant while the scale is not that skewed.
IMPLEMENTATION OF FEATURE SCALING IN PYTHON
In this tutorial, we will perform feature scaling on the Housing Prices dataset.
We will perform each feature scaling differently and show accuracy after each scaling.
Let’s start by importing the necessary libraries and packages

Now we will import our dataset.

Output :

We have to predict the price of a house from the above features.
Now we will visualize the dataset.
Output :

Now we will get some information about dataset values.

Output :

Now we will perform
NORMALIZATION OF DATASET

Output :

Now we will apply.
STANDARDIZATION TO OUR DATASET
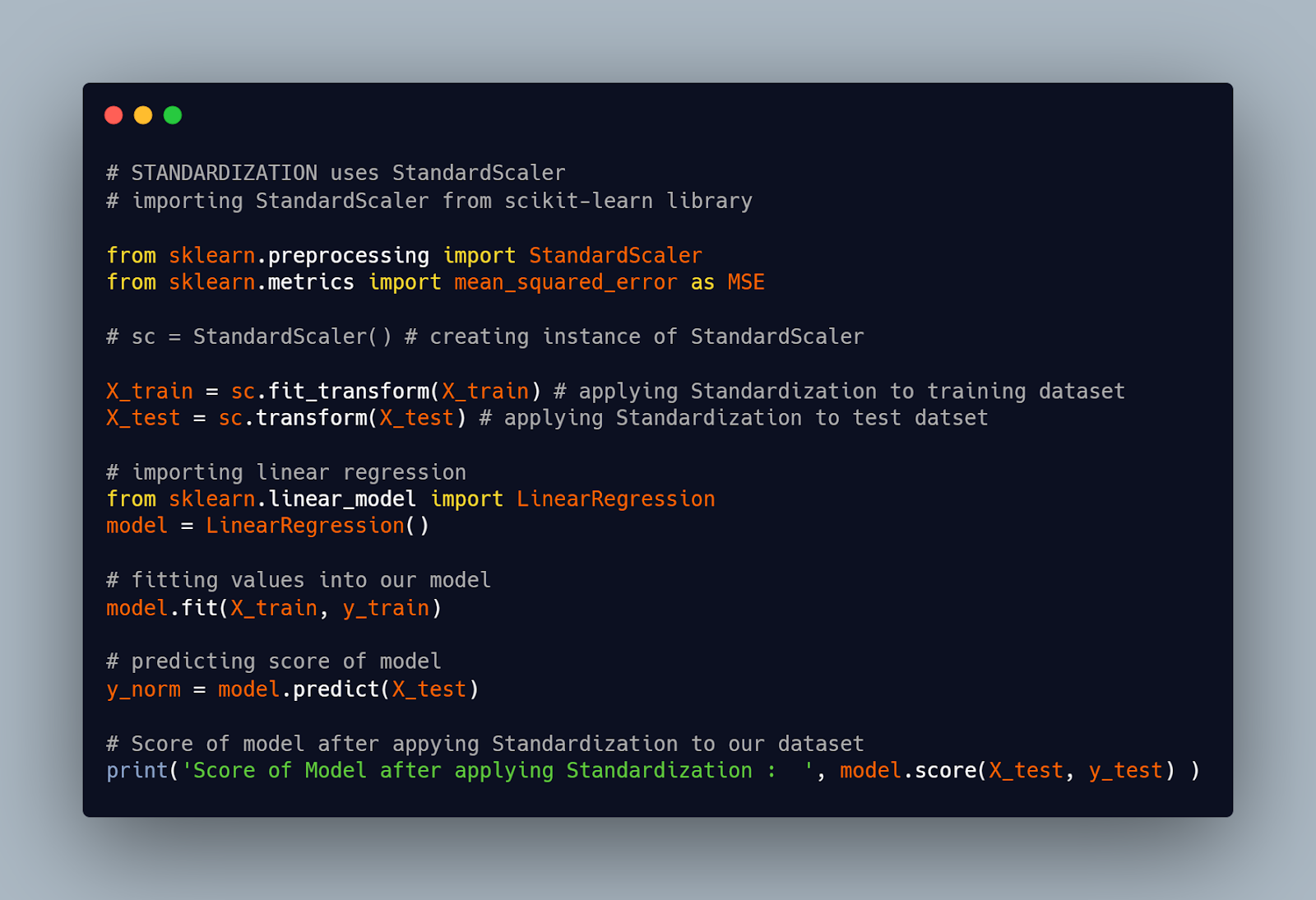
Output :
![]()
Now we will apply log transform on a specific attribute

Output :

After applying the log transform on area feature
Output :
Now we will print the OLS report for our model.


Output :

SUMMARY
In this article, we read about regularization, its need, and types of regularization.
And also why it plays a vital role in determining the accuracy and predictive power of a model.
We learn about Normalization, Standardization, and log transformation and when to apply them and how to apply them. however, We also learned about in which case we should apply them and also saw a practical example and coded it.
We also made a model and applied all types of transformation to it and at last interpreted the accuracy of the model after each transformation. thus, after that, we printed an OLS report of the model which shows us the overall accuracy of the model.
I hope that you liked it.
Written By: Mohit Kumar
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs